개요
스탠포드대 강의인 cs276 information retrieval의 강의를 공부한뒤 강의 슬라이드를 정리하는 포스팅이다. 어디까지나 자의적인 이해와 해석이 있는만큼 참고할 분들은 비판적 사고로 접근하기를 권장한다.
이번 강의에서는 Boolean retreival에 대해 소개한다.
링크
https://mix.office.com/watch/pm1pbrwiwi1d
OUTLINE
이번 포스팅에서 배울 내용은 아래와 같다.
- Introduction
- Inverted index
- Processing Boolean queries
- Query optimization
Introduction
Definition of information retrieval
IR(information retrieval)은 비구조의 데이터(보통 텍스트)의 재료(보통은 문서)를 대용량의 컬렉션(보통 서버) 안에서 필요한 정보를 찾는데 목적이 있다.
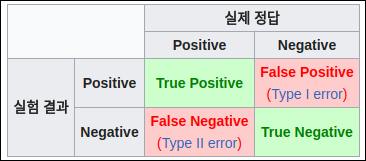
How good are the retrieved docs?
아래의 개념에서 positive/negative는 retrieval 여부이고 true/false는 relavant 여부이다.
- Precision : 획득된 문서중에 관련있는 문서의 비율
- Recall : 컬렉션에서 관련있는 문서의 비율
이 2개의 지표는 tradeoff일때가 많다.




Unstructured Data
전세계 적으로 데이터는 unstructured data가 많다.
Boolean retrieval
- boolean 모델은 information retrieval 시스템 중에서 가장 단순한 모델이다.
- 쿼리는 boolean 표현이다. (예: CAESAR ANd BRUTUS)
- 검색엔진은 boolean 표현식을 만족하는 모든 문서를 반환해준다.
Does Google use the Boolean model?
- 구글에서도 기본 쿼리 표현식은 and의 연속이다.
- $[w_1 \ w_2 \ … \ w_n]$
- 검색식에 포함되지 않아도 리턴될 수 있는 것들
- 앵커 텍스트
- morphology, spelling, correction, synonym
- 너무 긴 쿼리
- simple boolean vs ranking
- simple boolean 은 순서없이 매칭된 문서를 리턴한다.
- 구글은 boolean model을 고도화 하여 랭킹이 있는 결과물을 반환한다.
Inverted index
Unstructured data in 1650
- Shakespeare의 책을 검색하는 것으로 Unstructured 데이터에 대해 알아보자.
- BRUTUS and CAESAR and !(CALPURNIA)인 text를 찾고싶다면?
- 한가지의 방법은 라인별로 grep을 해서 BRUTUS and CAESAR를 찾고 CALPURNIA가 포함된 라인을 제거하는 것이다.
- grep이 좋은 솔루션이 아닌 이유는?
- grep은 매우 느림(대용량 데이터일때)
- grep은 line 기반인데 IR은 문서 기반이다.
- NOT CALPURNIA는 생각보다 쉽지 않다. (프로그램을 따로 짜야함)
- 다른 연산이 필요하다면? (예를 들어 COUNTRYMAN 바로 근처의 ROMANS 단어 찾아보기)
- 따라서 grep말고 다른 방법을 찾아보아야 한다.
Term-document incidence matrix
grep보다 이런 비트연산이 훨씬 더 효율적이다. 이유는 space와 time면에서 더 효율적이기 때문이다.

비트 1은 단어를 포함한다는 뜻이고 0은 그 반대이다. 예를 들어 CALPURNIA는 Julius Casesar에는 포함되고 The Tempest에는 없다는 것을 보여준다.
Incidence vectors
- 각각의 단어는 0/1의 벡터를 가진다.
- 다시 BRUTUS ANd CAESAR and !(CALPURNIA)인 text를 찾고싶다면?
- 위에서 설명한 쿼리에 답을 하기 위해서는:
- 단어들을 벡터화 한다.
- CALPURNIA는 벡터값을 뒤집는다.(010000을 뒤집는다.)
- 세 벡터를 비트와이즈 연산한다. 110100 AND 110111 AND 101111 = 100100
결과는 아래와 같다. 검색식을 만족하는 책은 anthony와 햄릿임을 알 수 있다.

Bigger collections
- 만약 $10^6$ 문서에서 각각 1000개의 토큰이 있다고 한다면?
- $ 10^9$의 토큰이 존재한다.
- 토큰당 6바이트라고 한다면 document colleciton은 $ 6 * 10^9 = 6 GB $
- 만약 500,000개의 각각 다른 term이 컬렉션에 있다면?
- 이정도 큰 크기로는 행렬을 만들기 어려움
- 행렬은 또한 매우 sparse함
- 우리는 term과 token의 차이를 알아볼 것이다.
Can’t build the incidence matrix
- 행렬을 0/1로 표현하면 행렬이 너무 sparse하다.
- 더 나은 방법은?
- 0/1 중에서 1만 행렬로 기록한다.
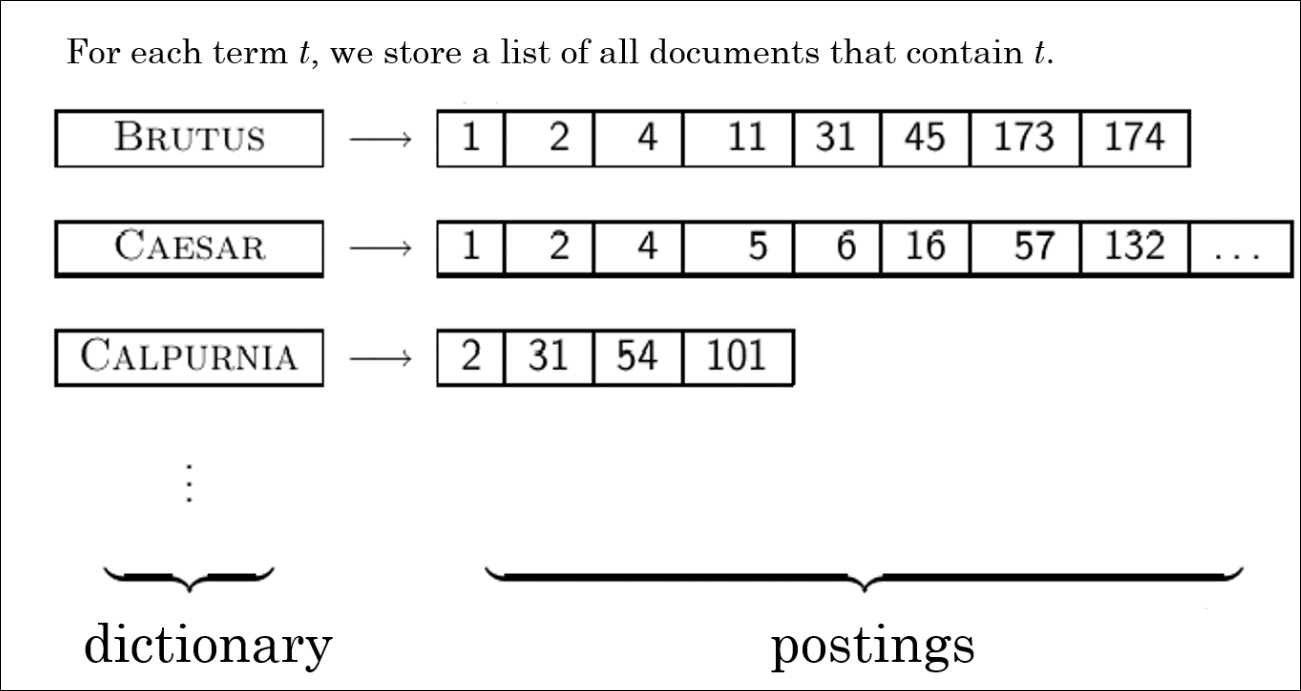
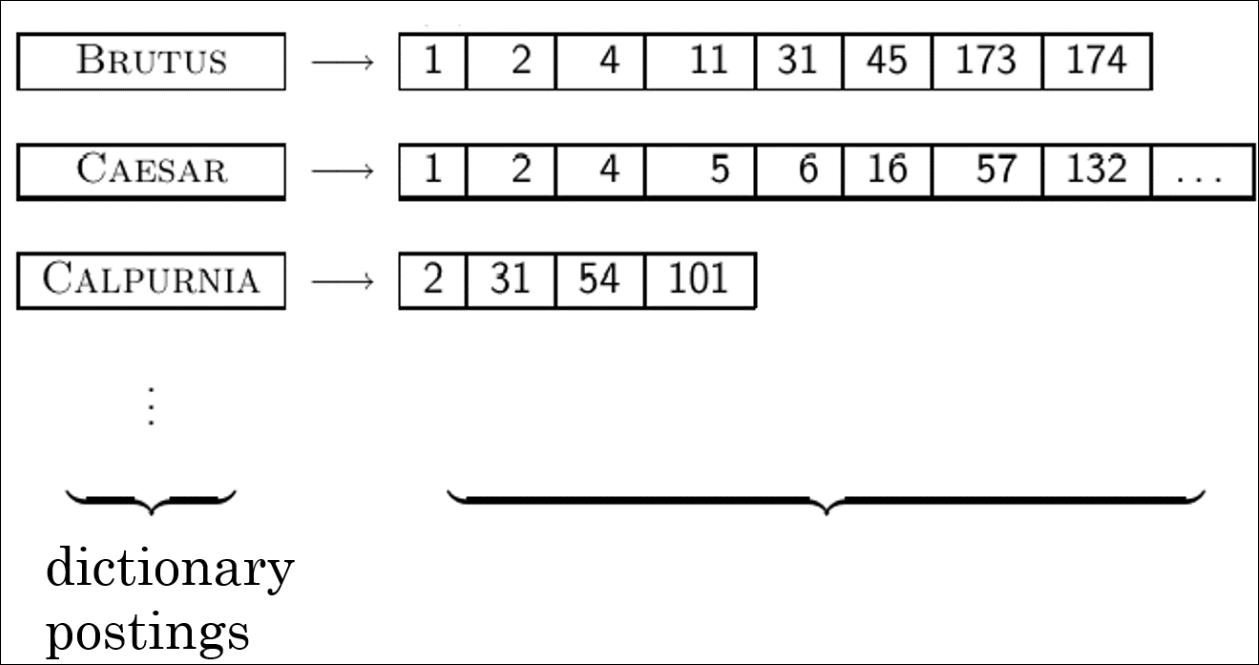
Inverted Index
- 따라서 Inverted Index는 앞선 슬라이드의 아이디어 처럼 term의 존재하는 경우만 관리함
- 사전-포스팅 리스트로 관리
- 사전은 각 term이 속해있음
- 포스팅리스트는 문서 번호가 리스트로 존재함
Inverted Index construction
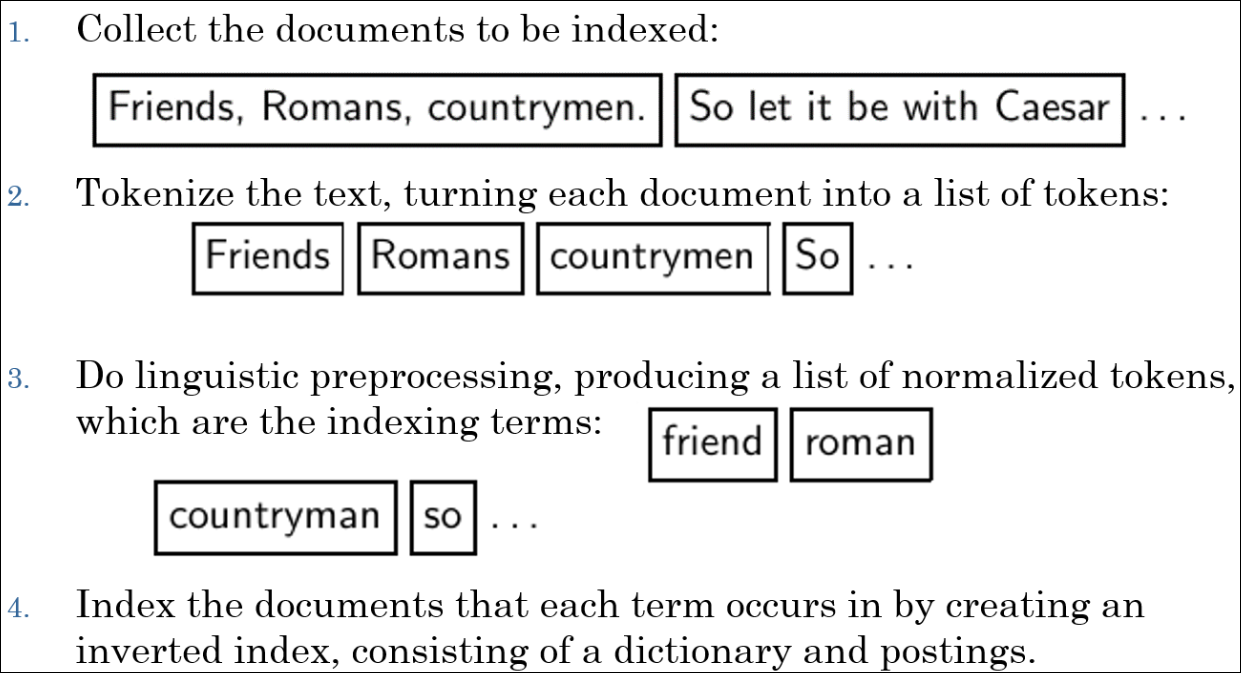
- 색인할 문서를 수집한다.
- text를 토큰화 한다.
- 언어의 특성에 맞는 전처리를 통해 normalized 토큰을 확보한다.
- 문서에 각 term이 발생하는 것을 정리하여 역색인을 만든다.
Initial stages of text processing
- Tokenization
- 문자열을 단어 토큰으로 자름
- “John’s”, a state-of-the-art solution
- Normalization
- text와 query term을 같은 형태로 만듦
- 예를들어 U.S.A.와 USA 를 매치시키고 싶음
- Stemming
- 서로 다른 단어를 같은 어근을 통해 매치시키고 싶을때
- authorize, authorization
- Stop words
- 매우 자주쓰는데 중요치 않은 단어를 생략시킬때 사용
- the, a, to, of
Tokenizing and preprocessing
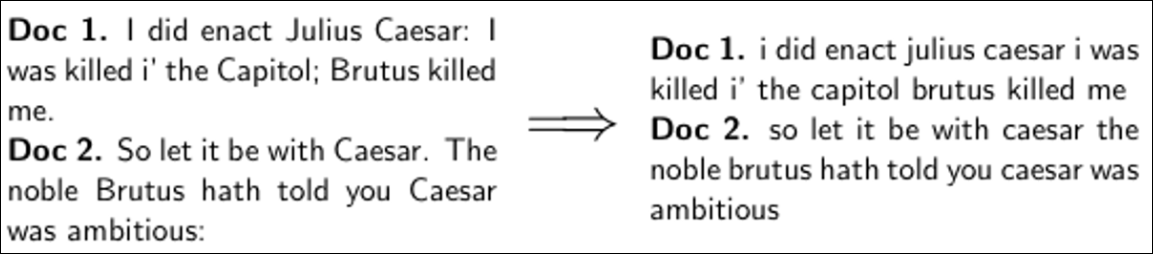
여기서 부터 쉐익스피어 예제로 역색인을 생성하는 방법을 구체적으로 알아본다. 우선 토큰화와 전처리를 수행한다. 우선 구두점을 제거하고 모두 소문자화 한다.
Generate posting
포스팅을 아래와 같이 구한다. 실제로는 MR을 돌면 쉽게 아래와 같이 만들것이다.
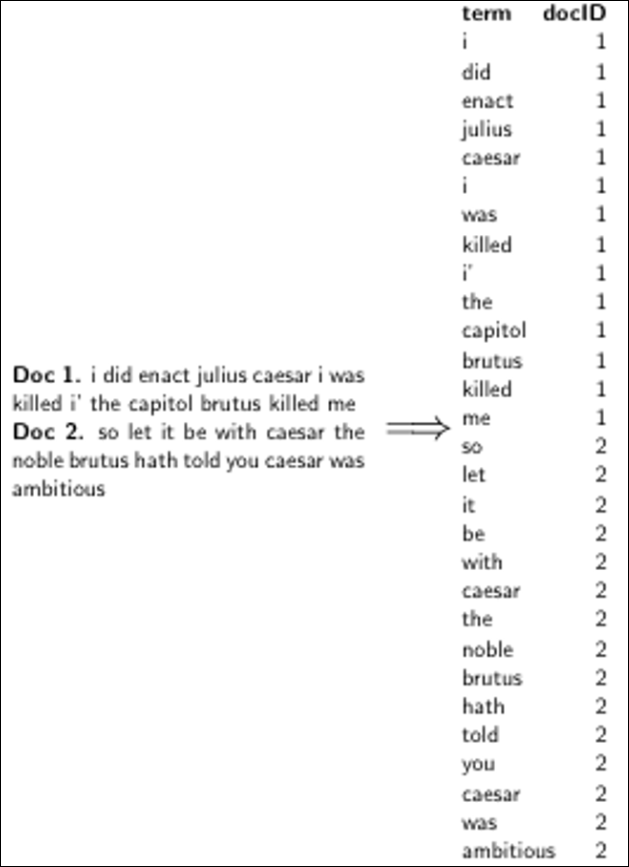
Sort postings
이후 키워드로 포스팅을 알파벳순으로 정렬한다.
Create posting lists, determine document frequency
역 인덱스를 다시 빈도수에 따른 상위 테이블을 만들고 이 테이블의 값으로 포스팅 리스트를 링크드 리스트 형태로 찾아 갈 수 있게 만든다. * 상위 테이블은 term과 df()몇개의 문서에서 term이 발생했는지)로 구성된다. * 포스팅 리스트는 문서 ID의 연결 리스트이다.

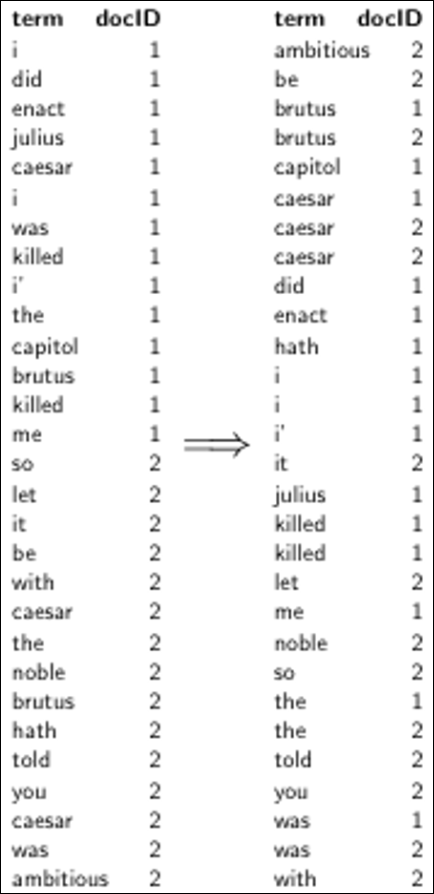
Split the result into dictionary and postings file
결국 아래와 같이 dictonary와 포스팅 파일로 구성되게 만들 수 있다.
Later in this course
- 대용량 컬렉션에서는 어떻게 역색인을 만들것인가?
- 사전과 색인을 유지하기 위해 얼마나 많은 공간이 필요한가?
- index compression
- 얼마나 효율적으로 대용량 컬렉션의 인덱스를 저장할 수 있을까?
- Rank Retrieval
- 최적의 답을 얻기 위해 역 인덱스가 구성되어야 하나?
Processing Boolean queries
Simple conjunctive query(two terms)
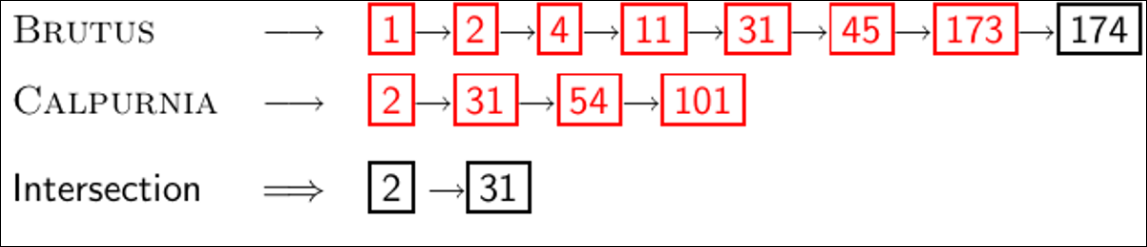
쿼리 : BRUTUS AND CALPURNIA
- BRUTUS를 역 색인 사전에서 찾기
- 해당되는 포스팅 리스트를 획득하기
- CALPURNIA를 사전에서 찾기
- 마찬가지로 포스팅 리스트를 획득하기
- 2개의 교집합의 문서 리스트를 획득하기
- 사용자에게 교집합을 리턴해주기
Intersecting two posting lists
- 하지만 Naive하게 교집합을 찾는것은 성능 효율적이지 않다. 따라서 더 나은 방법을 생각해보자.
- 미리 포스팅 리스트를 문서 ID순서로 정렬해둔다.
- BRUTUS와 CALPURNIA가 둘다 들어가 있는 문서는 결국 2와 31이다.
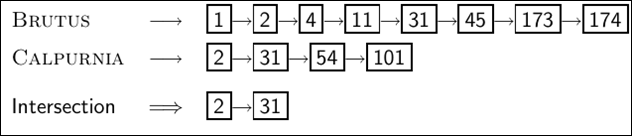
- 이것은 포스팅 리스트 길이에 선형적이다.
- 노트: 이것은 포스팅 리스트가 정렬되어 있어야 수행 가능하다.
Intersecting two posing lists
위의 쿼리를 수행하는 알고리즘은 아래와 같다. 마지막 줄의 else가 indextation이 좀 잘못 된것 같긴한데 기본적으로 포인터가 이동하며 서로 같은 문서 ID를 찾으면 교집합 리스트에 추가하고 그렇지 않으면 문서ID간 비교를 통해 작은쪽 리스트의 포인터를 이동하며 비교한다. 이 것을 두 포인트 모두 리스트의 끝까지 이동할때까지 비교를 수행한다. 
Quiz: Query processing
아래의 쿼리에 답을 구하시오.
((paris AND NOT france) OR lear)

답은 6 10 12 15이다.
Boolean queries
- Boolean retrieval모델은 boolean 표현식으로된 어떠한 쿼리도 답을 할 수 있다.
- Boolean 쿼리는AND OR NOT을 조합하여 사용할 수 있다.
- term을 질의함
- 각 문서를 term의 집합의 관점으로 바라봄
- 정확한 검색 방법 : 문서가 조건에 일치하느냐/아니냐
- 30년간 주요한 상업 검색엔진이 사용한 방법
- 많은 전문 검색가(예: 변호사)들은 아직도 이 방법을 선호함
- 사용자가 검색결과가 어떨지 정확히 알고 있다면
- 현존하는 많은 검색 시스템은 이 방식을 사용
- spotlight, email, intranet etc.
Commercially successful Boolean retrieval: Westlaw
- 상업 boolean 검색 엔진으로 가장 큰 규모의 검색 서비스
- 1975년에 서비스를 시작함
Westlaw: Example queries
아래는 Westlaw 쿼리의 하나의 예제이다.

Westlaw: Comments
Westlaw 쿼리에 사용되는 연산자는 아래와 같은 것들이 있다.
- /p : within paragraph
- \s : within sentence
- \3 : within 3 words
- space : disconjunction
Query optimization
- 쿼리 텀이 2 이상이라고 가정해보자.
- 각각의 텀에 대해 포스팅 리스트를 획득해야 되고 이를 합쳐야 한다.
- BRUTUS AND CALPURNIA AND CAESAR 를 예로 든다면
- 어떤것이 쿼리를 처리하는 최선의 순서일까?
가장 간단한 방법은 포스팅 리스트가 짧은순으로 CAESAR, CALPURNIA, BRUTUS 를 처리하는 것이다.
위의 쿼리를 처리한다면 아래와 같아진다.
- CASESAR와 CALPURNIA를 비교해서 31을 먼저 찾는다.
- 31부터 다시 BRUTUS와 비교한다.

More general optimization
- Example query: (MADDING OR CROWD) and (IGNOBLE OR STRIFE)
- 모든 term의 빈도수를 구함
- 각각의 or는 단어의 빈도를 합하여 구함
- “or size”의 오름차순으로 처리함 -> 내부의 or는 합친 큰 chunk로 봐서 이 순서대로 and를 처리한다.
퀴즈
퀴즈는 이중에서 어떤것을 가장 먼저 처리해야 할 것인가이다.

정답은 문서 리스트 길이의 합이 가장 짧은 kaleidoscope OR eyes를 처리하는 것이 효율적이다.
Term vocabulary & posting lists
outline
- Documents
- Terms
- General + Non-English
- English
- Skip pointers
- Phrase queries
Documents
- 이전까지 simple boolean model을 알아봤다.
- 우리의 가정은
- 문서가 무엇인지 안다.
- 우리는 기계가 각 문서를 읽을수 있게 할 수 있다.
- 하지만 현실세계에서는 이것이 복잡하다.
Parsing a document
- 문서 포맷, 언어에 따라 다뤄줘야 함
- pdf, word, excel, html etc.
- 언어의 종류
- 캐릭터셋
- 이것은 모두 분류 문제로써 나중에 다룰 것이다.
- 대안은 휴리스틱을 사용하는 것이다.
Format/Language: Complications
- 단일 인덱스도 여러개의 언어를 가질 수 있음
- 문서의 단위는?
- 단일 파일
- 이메일
- 첨부를 포함한 이메일
Definitions
아래와 같이 용어를 정의해보자.
- word : delimited 된 문자열
- term : normalized word
- token : 문서 내의 word or term
- type : 대부분 term의 동의어
Normalization
- 색인 된 term과 쿼리 term을 둘다 같은 form으로 normalize 할 필요가 있음
- 예: U.S.A -> USA
- 같은 분류의 term으로 정의하는것
- 예를 들어 아래의 단어를 왼쪽으로 normalize
- window -> window, windows
- windows -> Windows, windows
- Windows (no expansion)
- 더 강력하나 덜 효율적임
- 왜 window, Window, windows, and Windows를 같은 클래스로 분류해야 하는가?
Normalization: Other languages
- 언어에 따라서는 MIT가 다른 뜻으로 해석 될 수 있다
- PETER WILL NICHT MIT. -> MIT = mit
- He got his Phd from MIT. -> MIT != mit
Recall: Inverted index construction
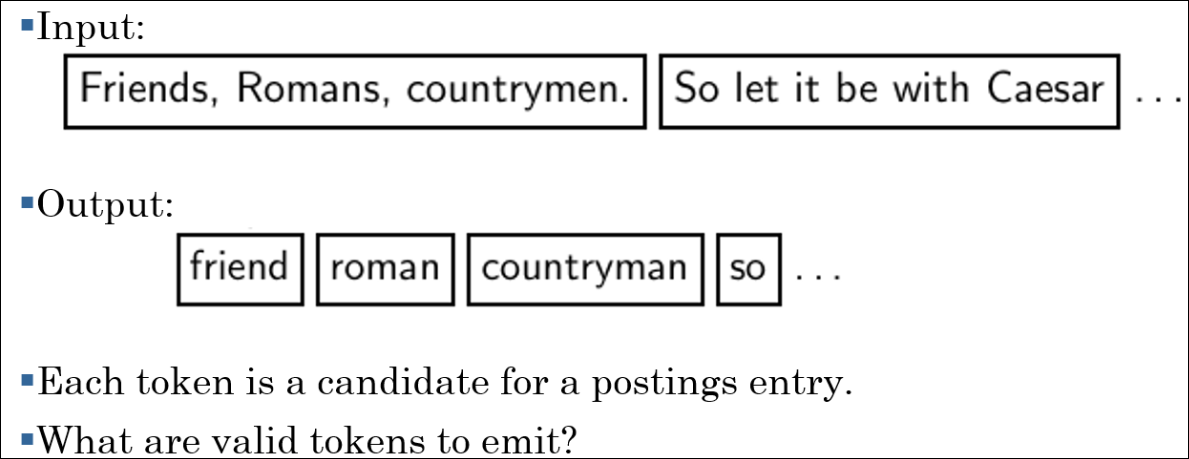
- 각 토큰은 포스팅 엔트리 후보이다.
- 어떤게 유효한 토큰인가?

- 토큰 : 스페이스 기준으로 파싱
- type : in, june, the, like, to, chase, cat, barn (소문자화와 구두점 제거만고려, 단어는 원형으로만 stemming) (stop word는 없다고 가정)
Tokenization problems: One word or two? (or several)
아래의 단어들은 의미상 하나의 단어로 다뤄져야한다.
- Hewlett-Packard
- State-of-the-art
- co-education
- the hold-him-back-and-drag-him-away * maneuver
- data base
- San Francisco
- Los Angeles-based company
- cheap San Francisco-Los Angeles fares
- York University vs. New York University
Numbers
- 3/20/91
- 20/3/91
- Mar 20, 1991
- B-52
- 100.2.86.144
- (800) 234-2333
- 800.234.2333
- 오래된 검색 시스템에서는 숫자를 색인하지 않았음
- 하지만 일반적으로 유용한 feature이다.
Chinese: No whitespace
- 중국어는 공백이 없음
Ambiguous segmentation in Chinese
- 단어에 따라 2개의 한자가 하나의 단어가 될수도 있고 2개의 한자가 각각의 단어가 될 수도 있음
Japansese
- 히리가나 + 카타가나 + 영어 + 숫자의 조합이 어려움
Arabic script
- 오른쪽에서 왼쪽으로 문장을 읽는데 숫자는 왼쪽에서 오른쪽으로
- 유니코드에서는 이슈가 없음
Accents and diacritics
- 쿼리가 아래 둘중 어떤것으로 들어올것인지 예상해야함
- résumé vs. resume
Case folding
MIT나 mit같이 경우에 따라 대소문자를 구별해 줘야 하는 경우도 있음
- 모두 소문자로 만드는 것
- MIT vs. mit
- Fed vs. fed
Stop words
- 너무나 흔한 단어
- 예: a, an, and, are, as, at, be, by, for, from, has, he, in, is, it, its, of, on, that, the, to, was, were, will, with
- 예전의 검색엔진에서는 금칙어를 적용 했었음
- 하지만 “Kingdom of Denmark”와 같은 단어와 같이 of를 제거하면 안되는 케이스도 있다.
- 대부분의 검색 엔진은 금칙어를 색인함
Lemmatization
- 원형으로 변형하는 것
-
예제
- am, are, is -> be
- car, cars, car’s, cars’ -> car
- the boy’s cars are different colors -> the boy car be different color
-
Lemmatization은 lemma라 불리는 사전의 원형 form으로 적절히 변환하는것.
-
굴절형태소 원형 vs 파생형태소 원형
Stemming
- 어근을 빼고 단어를 자름
- lemmatization보다 좀 더 공격적인 기법
- 원형의 prefix만 취하는 것
- 언어에 따라 다름
- automate, automatic, automation -> automat
Porter algorithm
- English에서 아주 흔하고 인기있는 알고리즘
- Rule을 정해놓고 5개의 단계로 단어를 줄임
Rule은 아래와 같다.

Three stemmers: A comparison
sample text는 original text를 의미하고 이 문장이 각 stemmer별로 어떻게 달라지는지 보여준다.

Does stemming improve effectiveness?
- 일반적으로 스테밍은 장단점이 존재할 수 있음
- 장점의 예는 tour san francisco -> tour/tours 가 같아짐
- Porter Stemmer를 쓸 경우 아래의 단어가 다 oper로 같아짐
- oper <- operate operating operates operation operatives operational
- 단점의 예는 operational AND research, operating AND system, operative AND dentistry가 뜻이 다른데 다 oper로 합쳐지는게 이슈가 있음
Quiz: Lemma and Stem
아래의 True False를 구하시오.
- In a Boolean retrieval system, stemming never lowers precision. (T/F)
- In a Boolean retrieval system, stemming never lowers recall. (T/F)
- Stemming increases the size of the vocabulary. (T/F)
- Stemming should be invoked at indexing time but not while processing a query. (T/F)
답은 F F F F
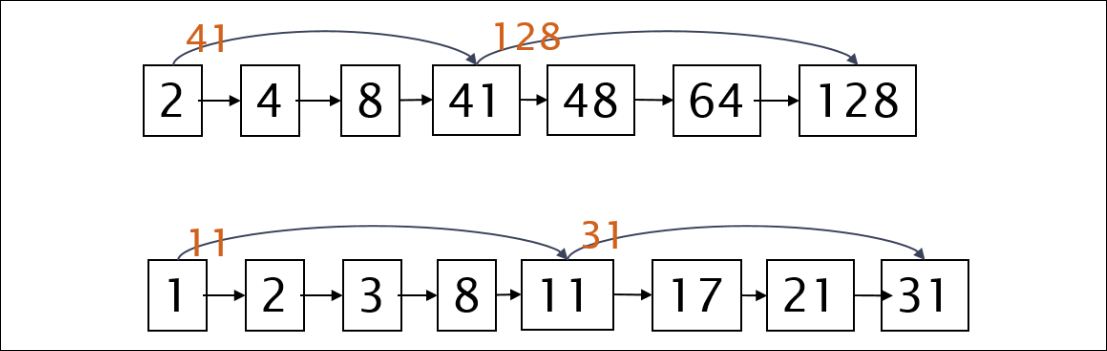
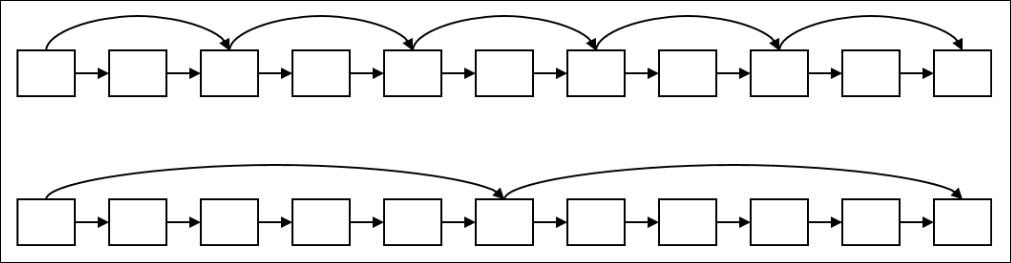
Recall basic intersection algorithm
- 이 그림에서 교집합은 자세히 보면 2에서 31로 확 뛰어넘는데 실제로도 우리가 일부 pointer를 skip할 수 있을까?
- 성능이 포스팅 리스트의 선형적인 길이에 의존함
- 더 나은 방법이 있을까?
Augment postings with skip pointers (at indexing time)
- 아래와 같이 skip pointer를 둬서 일부는 jump가 가능하게 한다.
- 왜?
- To skip postings that will not figure in the search results.
- 어떻게?
- 어디에 skip 포인터를 둬야 할까?
Query processing with skip pointers
- 만약 양쪽 다 8까지 이동한 상황이라고 가정해보자.
- 이때 위의 경우 다음이 41이다.
- 아래는 다음 값이 11이고 41보다 작으므로 skip포인터값이 41보다 작으므로 바로 31로 jump 한다.
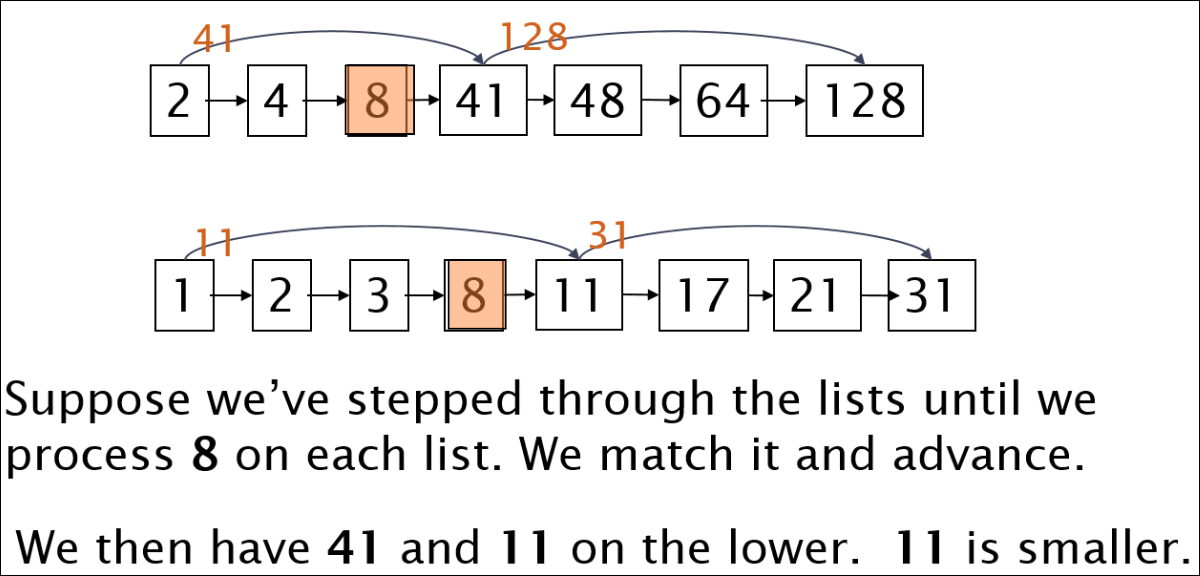
Intersection with skip pointers
알고리즘으로 나타내면 아래와 같다.
기존의 교집합 비교에서 스킵포인터 값을 체크하는 로직만 추가되었다.

Where do we place skips?
- Tradeoff
- more skips -> skip 성공 가능성 높음, 너무 많은 비교가 일어날 수 있음
- fewer skips -> skip 성공 가능성이 낮을 수 있음, 비교가 적어짐
Where do we place skips? (cont)
- 단순한 휴리스틱 : 문서 길이를 $P$라고 가정하면 $\sqrt{P}$개의 skip pointer를 만든다.
- 다만 위의 방법은 query term의 분포가 고려되어 있지 않음
- index가 정적이면 좀 더 쉬움
- skip pointer가 얼마나 도움이 되나?
- 도움은 많이 됨
- 하지만 요즘은 CPU가 워낙 좋아져서 생각보다 도움이 되지 않음
Phrase queries
- 목적은 “stanford university” 같은 검색어를 처리하고 싶음
- “The inventor Stanford Ovshinsky never went to university “는 stanford와 university가 붙어있지 않으므로 리턴되면 안됨
- 웹의 10%가 phrase 쿼리임
- 2개의 역색인 확장 방법이 있음
- biword index
- positional index
Biword indexes
- bigram처럼 word를 순서대로 2개씩 색인함
- 예를 들어 “Firends Romans Countryman”이면 “Friends, Romans”와 “Romans Countryman”을 저장함
Longer phrase queries
- “stanford university palo alto”가 있다고 하면 biword로 색인한다.
- biword index를 찾고 post filtering으로 4개의 단어가 다 있는지 확인한다.
Extended biwords
- 각 문서를 파싱하여 아래와 같은 규칙으로 태깅함
- 명사/전치사 등을 bucket으로 나눔
- NX*N 형태로 만듦(X는 1회 이상)
- 예
- catcher in the rye N X X N
- king of Denmark N X N
- 하지만 computing cost가 비쌈, 구글에서도 안씀
Issues with biword indexes
- Why are biword indexes rarely used?
- false positive(찾았는데 잘못 찾은 경우) -> post filter를 하더라도 지저분 할 수 있음
- 색인이 너무 큰 단어 사전에 의해 용량이 너무나 많이 증가할 수 있음
Positional indexes
- biword 인덱스에 비해 효율적임
- 순서가 없는 포스팅 리스트 : 각 문서는 docId를 가짐
- 순서가 있는 포스팅 리스트 : 각 문서는 docId가 있고 위치에 대한 리스트가 있음
Positional indexes: Example

Proximity search
- posional index를 이용하여 proximity search가 가능함
- 예를 들어 “employment /4 place”를 검색한다고 가정해보자
- /4는 wihtin 4 words이다.
- employment와 place를 찾는데 4 단어 안에 있는것을 찾는다
아래 두개로 보면 위의 문장은 4단어 사이에 두 term이 존재해서 hit가 되고 아래는 4단어 보다 멀어서 hit되지 않는다.
- Employment agencies that place healthcare workers are seeing growth is a hit.
- Employment agencies that have learned to adapt now place healthcare workers is not a hit.
Proximity search
- positional index를 사용함
- 단순한 알고리즘 : 교집합을 찾는 것
- 하지만 이방법은 자주쓰는 단어에 있어 매우 비효율적임(많은 문서, 많은 위치)
- 또한 찾아지는 위치만 리턴하는 것이 아니라 문서 리스트를 리턴해야 함
“Proximity” intersection
알고리즘은 아래와 같다.

Combination scheme
- Biword 색인과 positional 색인은 효율적으로 조합될 수 있음
- 많은 biword는 매우 자주 등장 할 수 있음 : Michael Jackson, Britney Spears
- 이런 biword는 positional index대비 속도가 빠름
- frequent biword는 vocabulary term으로 색인하고 나머지는 positional intersection을 함
“Positional” query on google
- 웹 검색에서 positional 쿼리는 boolean query에 비해 매우 무거움
- phrase 쿼리의 예를 보자.
- 왜 더 무거울까?
- 구글에서 boolean 쿼리 대비 phrase 쿼리가 더 무거운것을 시연할 수있을까?
Take-away
- 기본 IR시스템의 기본 단위 이해
- words
- documents
- term
- Tokenization
- 어떻게 원문이 word로 얻어지는지
- 더 복잡한 index
- skip pointers
- phrases