개요
최근 회사에서 S3 사용 비용이 꽤 많이 나와서 원인 분석 및 대응을 위해 진행해본 문제해결 과정을 정리해둔다.
S3 발생 비용, 카테고리 구분
S3 비용은 크게 2가지로 나눌 수 있다.
사용 환경에 따라 종류별 비용의 비율을 확인하여 생산적으로 튜닝을 하는게 필요하다는 생각이다.
- 적재 비용 : 데이터를 적재하여 보관하는데 드는 비용이다.
- read/write 비용 : 적재된 데이터에 read/write 할 때 소요되는 비용이다.
카테고리별 현황 확인 방법
1. 적재 용량 확인
AWS 콘솔에서 S3 Storage Lens를 활성화 하면 버킷별 데이터 적재 현황을 확인 할 수 있다.
2. 데이터 read/write 통계 확인
S3 버킷별 read/write를 확인하기 위해 전제조건이 필요하다.
S3 버킷에 server access 로그를 특정버킷으로 남기게 설정을 한 뒤 여기에 모인 로그를 가지고 분석을 할 수 있다.
(적어도 금융권에서는 이 설정이 필수이므로 의미없는 행위는 아니다.)
access 로그를 남기기 원하는 S3 버킷에서 properties 탭에서 아래 그림과 같이 로깅 설정을 하면 스크린샷 기준 sli-dst-dlprod-public이라는 버킷에서 로그를 확인 할 수 있다.

이후 오픈소스 Baram으로 해당 기능을 개발해두었으니 이용하면 엑세스로그 현황을 볼 수 있다. 아래와 같이 설치하자.
아래와 같이 지정하면 24년 10월 내 엑세스로그를 읽어 read/write를 분석해준다.
# When
from baram.s3_manager import S3Manager
bucket_name = 'sli-dst-dlbeta-public'
sm = S3Manager(bucket_name)
stats = sm.analyze_s3_access_logs(bucket_name=bucket_name,
prefix=f'계정/ap-northeast-2/{bucket_name}/',
start_date='2024-10-01',
end_date='2024-10-31')
# Then
print(stats)
통계를 출력하면 아래의 형식으로 object별 read/write 비율이 나오고 stdout을 바로 복사해 excel이나 google sheet에서 복붙하여 세부적인 분석을 할수도 있다.
Count Type Target Bucket Resource Value
read sli-dst-dlprod-public /smbeta-pipeline/model/pipelines-v5g0epxo78dc-train-smbeta-pipelin-T2cscQY9nc/output/model.tar.gz 942
read sli-dst-dlprod-public /?tagging 69
read sli-dst-dlprod-public / 69
read sli-dst-dlprod-public /sli-dst-dlprod-public?versioning 11
read sli-dst-dlprod-public /sli-dst-dlprod-public?logging 9
read sli-dst-dlprod-public /?encryption 6
대응 방법
1. 적재비용: Hot/Cold 스토리지 전략 수행
시중에 나와있는 소위 Hot/Cold 스토리지 전략으로써 자주 안쓰는 데이터는 S3 Glacier로 옮겨 적재비용을 1/20으로 줄일 수 있다.
a. Storage Class 변경
위와 마찬가지로 Baram을 이용하여 특정 디렉토리 하위의 객체 스토리지 클래스를 더 값싼 것으로 변경할 수 있다.
from baram.s3_manager import S3Manager
bucket_name = '버킷명'
sm = S3Manager(bucket_name)
sm.change_object_storage_class(prefix='원하는디렉토리명', storage_class='DEEP_ARCHIVE')
특정 object 하나만 변경하고 싶으면 아래와 같이 해도 된다.
from baram.s3_manager import S3Manager
bucket_name = '버킷명'
sm = S3Manager(bucket_name)
key = 's3_key값'
sm.copy(from_key=key, to_key=key, StorageClass='DEEP_ARCHIVE')
b. life cycle 설정
매번 수동으로 Storage Class를 옮길수 없으니 (예를 들어) 60일 초과시 자동으로 Storage Class가 DEEP_ARCHIVE 로 변경되게 자동화 할 수있다.
S3 버킷의 Management 탭에서 Create Lifecycle rules를 클릭한다.

rule 이름을 정한다.
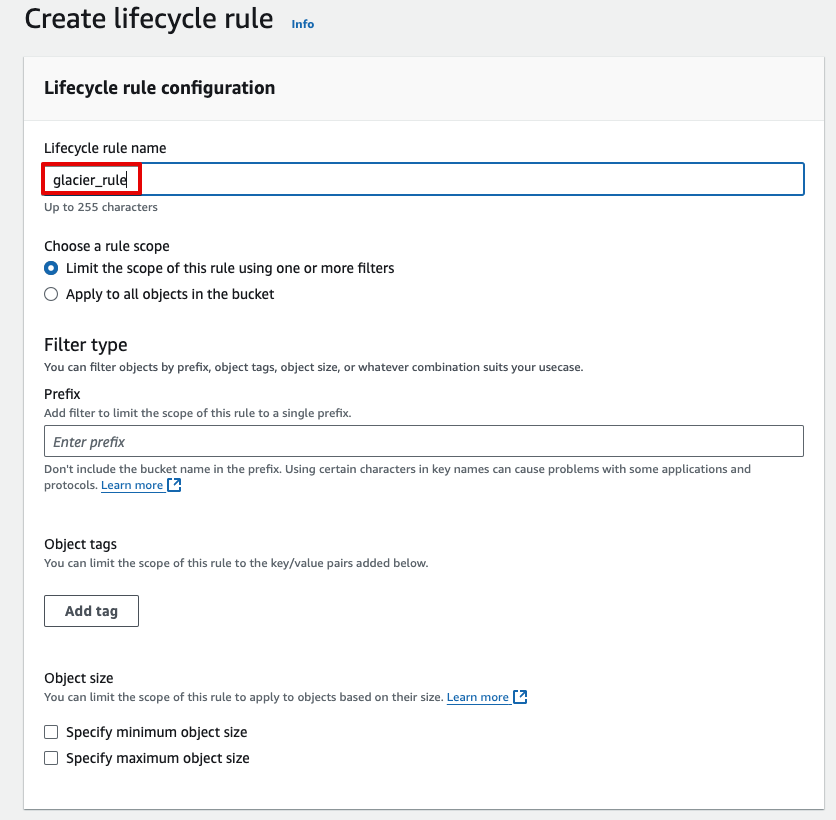
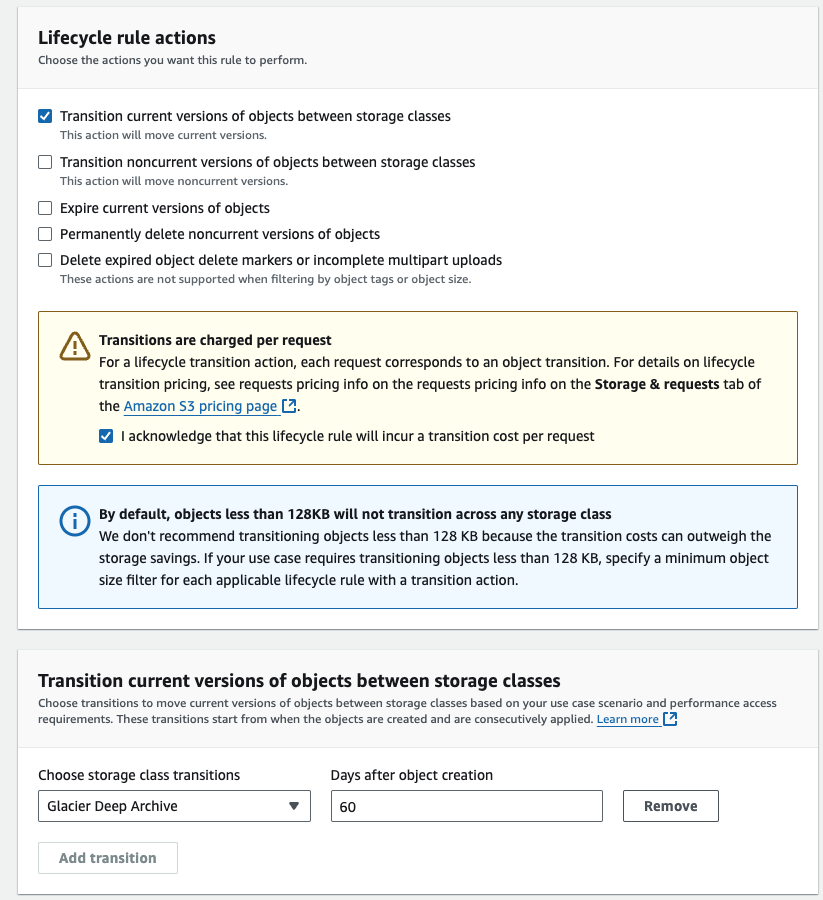
그림과 같이 60일 경과 시 자동으로 스토리지 클래스가 변경되게 설정한다.
2. read/write 비용: Hot spot 데이터 처리
이건 위에서 도출한 통계를 보고 본인 환경에 맞는 근본 원인을 튜닝해야 할 것이다.
결론
S3 비용 실정에 맞게 원인을 파악하여 어떤 카테고리에서 비용이 많이 발생하는지 보고 세부 원인을 파악한뒤 튜닝을 진행하면 된다.