개요
필자는 Airflow를 AWS환경에서 MWAA 환경으로 사용중이다.
MWAA 사용 기간이 늘어남에 따라 자연스럽게 Dag 생성/삭제가 반복 되었는데 문제는 소스코드 상에서는 분명히 지워졌는데 Web UI에서는 계속 dag count가 남아있는것이 발견되었다.
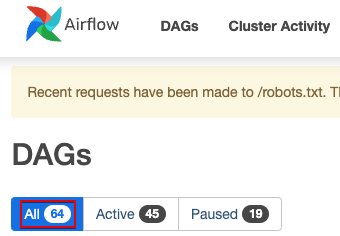
이를 해결하기 위한 방법을 찾아 본 뒤 정리해둔다.
원인
Airflow의 DB(이하 메타스토어)에 기록된 내용과 실제 Dag 갯수가 달라서 발생하는 문제였다.
WebUI에서 표시되는 카운트와 실제 물리 파일 카운트가 안맞는것도 문제지만 이현상이 지속될수록 Airflow Scheduler가 Dag Scan을 하는 작업이 쓸모없이 무거워 진다는 문제점이 발생하였다.
해결방법
해결 방법은 File로 Scan되는 Dags와 메타스토어의 Dags를 비교하여 필요없는 Dag를 삭제해 주는 것이다.
Airflow에 Python Operator로 만들어 아래 메서드를 실행해 주면 된다.
def clear_missing_dags(self):
'''
remove missing dags on s3 'dags' folder but still exsited on DB.
:return:
'''
logging.info("Starting to run Clear Process")
try:
host_name = socket.gethostname()
host_ip = socket.gethostbyname(host_name)
logging.info(f"Running on Machine with Host Name: {host_name}")
logging.info(f"Running on Machine with IP: {host_ip}")
except Exception as e:
print(f"Unable to get Host Name and IP: {e}")
session = settings.Session()
logging.info("Configurations:")
logging.info(f"session: {session}")
logging.info("")
dags = session.query(DagModel).all()
entries_to_delete = []
for dag in dags:
fileloc = dag.fileloc
if fileloc is None:
logging.info(
f"After checking DAG '{dag}', "
f"the fileloc was set to None so assuming "
f"the Python definition file DOES NOT exist")
entries_to_delete.append(dag)
elif not os.path.exists(fileloc):
logging.info(
f"After checking DAG '{dag}', "
f"', the Python definition file DOES NOT exist: {fileloc}")
entries_to_delete.append(dag)
else:
logging.info(
f"After checking DAG '{dag}', "
f"', the Python definition file does exist: {fileloc}")
logging.info("Process will be Deleting the DAG(s) from the DB:")
for entry in entries_to_delete:
logging.info(f"\tEntry: {entry}")
logging.info("Process will be Deleting {len(entries_to_delete) DAG(s)")
logging.info("Performing Delete...")
for entry in entries_to_delete:
session.delete(entry)
session.commit()
logging.info("Finished Performing Delete")
logging.info("Finished Running Clear Process")
추가 Airflow DB 최적화
위에서는 파일과 메타스토어의 Dag Sync 안 맞는것을 해결했다면 이번에는 DB의 오래된 기록들을 클렌징 하는 방법을 알아보자.
cleanup_metastore_objects를 통해 DATABASE_OBJECTS의 airflow_db_model별로 30일이 지난 데이터들을 클렌징 한다.
요약 하면 지속된 Airflow Dag 실행 과정에서 생긴 여러 DB 기록들 중 한달가량이 넘은 데이터들을 지워주는 것이다.
이렇게 DB의 데이터도 지속적으로 지워주지 않으면 점진적으로 오버헤드가 쌓여간다고 볼 수 있어 관리를 해줘야 한다.
def cleanup_metastore_objects(self):
from airflow.models import DagModel, DagRun, Log, XCom, SlaMiss, TaskInstance
from airflow.models import ImportError
from airflow.models import TaskFail
from airflow.models import TaskReschedule
from airflow.jobs.job import Job as BaseJob
from celery.backends.database.models import Task, TaskSet
DATABASE_OBJECTS = [
{
"airflow_db_model": BaseJob,
"age_check_column": BaseJob.latest_heartbeat,
"keep_last": False,
"keep_last_filters": None,
"keep_last_group_by": None
},
{
"airflow_db_model": DagRun,
"age_check_column": DagRun.execution_date,
"keep_last": True,
"keep_last_filters": [DagRun.external_trigger.is_(False)],
"keep_last_group_by": DagRun.dag_id
},
{
"airflow_db_model": TaskInstance,
"age_check_column": TaskInstance.updated_at,
"keep_last": False,
"keep_last_filters": None,
"keep_last_group_by": None
},
{
"airflow_db_model": Log,
"age_check_column": Log.dttm,
"keep_last": False,
"keep_last_filters": None,
"keep_last_group_by": None
},
{
"airflow_db_model": XCom,
"age_check_column": XCom.timestamp,
"keep_last": False,
"keep_last_filters": None,
"keep_last_group_by": None
},
{
"airflow_db_model": SlaMiss,
"age_check_column": SlaMiss.execution_date,
"keep_last": False,
"keep_last_filters": None,
"keep_last_group_by": None
},
{
"airflow_db_model": DagModel,
"age_check_column": DagModel.last_parsed_time,
"keep_last": False,
"keep_last_filters": None,
"keep_last_group_by": None
},
{
"airflow_db_model": TaskReschedule,
"age_check_column": TaskReschedule.reschedule_date,
"keep_last": False,
"keep_last_filters": None,
"keep_last_group_by": None
},
{
"airflow_db_model": ImportError,
"age_check_column": ImportError.timestamp,
"keep_last": False,
"keep_last_filters": None,
"keep_last_group_by": None
},
{
"airflow_db_model": TaskFail,
"age_check_column": TaskFail.end_date,
"keep_last": False,
"keep_last_filters": None,
"keep_last_group_by": None
},
{
"airflow_db_model": Task,
"age_check_column": Task.date_done,
"keep_last": False,
"keep_last_filters": None,
"keep_last_group_by": None
},
{
"airflow_db_model": TaskSet,
"age_check_column": TaskSet.date_done,
"keep_last": False,
"keep_last_filters": None,
"keep_last_group_by": None
}
]
for db_object in DATABASE_OBJECTS:
# TODO: Python Operator로 self.cleanup_metastore(db_object) 실행
실제 클린업 역할이 수행되는 메서드는 아래와 같다.
def cleanup_metastore(self, **context):
'''
cleanup unused metadata on meatastore
:param context:
:return:
'''
from sqlalchemy import func, and_
from sqlalchemy.exc import ProgrammingError
from sqlalchemy.orm import load_only
from airflow import settings
from airflow.models import DagTag, DagRun
from airflow.utils import timezone
now = timezone.utcnow
DEFAULT_MAX_DB_ENTRY_AGE_IN_DAYS = 30
max_date = now() + timedelta(-DEFAULT_MAX_DB_ENTRY_AGE_IN_DAYS)
session = settings.Session()
airflow_db_model = context["params"].get("airflow_db_model")
age_check_column = context["params"].get("age_check_column")
keep_last = context["params"].get("keep_last")
keep_last_filters = context["params"].get("keep_last_filters")
keep_last_group_by = context["params"].get("keep_last_group_by")
logging.info(f"Configurations:")
logging.info(f"max_date: {max_date}")
logging.info(f"session: {session}")
logging.info(f"airflow_db_model: {airflow_db_model}")
logging.info(f"age_check_column: {age_check_column}")
logging.info(f"keep_last: {keep_last}")
logging.info(f"keep_last_filters: {keep_last_filters}")
logging.info(f"keep_last_group_by: {keep_last_group_by}")
logging.info("")
logging.info("Running Cleanup Process...")
try:
query = session.query(airflow_db_model).options(load_only(age_check_column))
logging.info(f"INITIAL QUERY : {query}")
if keep_last:
subquery = session.query(func.max(DagRun.execution_date))
if keep_last_filters is not None:
for entry in keep_last_filters:
subquery = subquery.filter(entry)
logging.info(f"SUB QUERY [keep_last_filters]: {subquery}")
if keep_last_group_by is not None:
subquery = subquery.group_by(keep_last_group_by)
logging.info(f"SUB QUERY [keep_last_group_by]: {subquery}")
subquery = subquery.from_self()
query = query.filter(
and_(age_check_column.notin_(subquery)),
and_(age_check_column <= max_date)
)
else:
query = query.filter(age_check_column <= max_date, )
entries_to_delete = query.all()
logging.info(f"Query: {query}")
logging.info(f"Process will be Deleting the following {airflow_db_model.__name__}(s)")
for entry in entries_to_delete:
logging.info(f"\tEntry: {entry}, Date: {entry.__dict__[str(age_check_column).split('.')[1]]}")
logging.info(f"Process will be Deleting {len(entries_to_delete)} {airflow_db_model.__name__}(s)")
logging.info('Performing Delete...')
if airflow_db_model.__name__ == 'DagModel':
logging.info('Deleting tags...')
ids_query = query.from_self().with_entities(DagModel.dag_id)
tags_query = session.query(DagTag).filter(DagTag.dag_id.in_(ids_query))
logging.info(f'Tags delete Query: {tags_query}')
tags_query.delete(synchronize_session=False)
# using bulk delete
query.delete(synchronize_session=False)
session.commit()
logging.info('Finished Performing Delete')
logging.info("Finished Running Cleanup Process")
except ProgrammingError as e:
logging.error(e)
logging.error(f"{airflow_db_model} is not present in the metadata. Skipping...")
결론
위에서 소개한 방식은 1회성으로 수행할게 아닌 지속 관리가 필요한 영역이다.
따라서 필자는 위 2가지의 메소드를 Python Operator로 만들어 Daily로 실행하게 Dag를 구성하였다.
다른 분들 또한 위 방식을 추천드린다.
Reference
- https://github.com/teamclairvoyant/airflow-maintenance-dags/tree/master