개요
Exploring Web Scale Language Models for Search Query Processing논문을 읽고 내용을 요약 정리한다.
Abstract
검색 쿼리가 문서의 body나 title에 따라 매우 다른 스타일로 구성되는것은 널리 관측된다. 이런 언어 스타일의 차이를 고려하는 많은 테크닉들이 IR분야에서 희망적인 결과를 보여줬지만 대용량 데이터에서의 분석은 부족했다. 이 논문에서는 이 이슈에 대한 확장 연구를 LM의 검색 쿼리와 3개의 text stream(body, title, anchor text)에 대한 프로퍼티를 실험하였다. 논문의 정보검색이론에 대한 분석은 쿼리는 아무래도 구성되는것이 저자가 어떻게 문서의 anchor text나 title을 요약하는 것과 유사했다. 또한 이 과정에서 정량적인 관측에 대한 설명을 제공한다. 논문에서는 web scale n-gram LM에 3 search query processing(SQP) 작업을 적용했다: query spelling correction, query bracketing, long query segmentation. LM의 크기와 order를 바꾸어가며 실험한 결과 perplexity는 좋은 정확도 측정기준이라는 것을 발견하였다. 논문에서는 smoothed LM이 글들의 web count를 사용하는것 대비 query bracketing 작업에 있어 높은 정확도 향상을 얻을 수 있었다. 논문에서는 또한 큰 용량의 LM을 적용하여 작은 것 대비 정확도 향상을 얻을 수 있었다.
N-gram Language Model
확률적 language model은 단어의 순서에 대한 확률분포이다. 주어진 순서에서 예를 들어 길이가 m이라면 이를 확률 $P (W_1 , … , W_m)$로 구성되게 나타내는 것이다. 다른 phrase들이 등장할 가능성을 예측하는 것은 text를 출력으로 생성하는 많은 자연어 처리 어플리케이션 입장에서 유용하다. language 모델링은 음성 인식, 기계 번역, 음성 부분 태깅, 파싱, 필기체 인식, 정보검색 등 다양헌 어플리케이션에서 활용된다.
Perplexity(혼잡도)는 정보검색의 잘 알려진 이론으로써 language 모델이 테스트 데이터를 얼마나 잘 예측하는지 평가하는 지표이다. 낮은 perplexity값은 LM이 더 나은 예측성능을 보인다는 의미이다. Perplexity에 대한 이해는 Evaluation and Perplexity – Stanford NLP – Professor Dan Jurafsky & Chris Manning가 도움이 된다.
Table 1에 의하면 order 4(4-gram)은 anchor와 title이 size 연구에 포함되었다. 하지만 나중에 다루겠지만 order 4 LM는 얻는것 대비 용량이 훨신 커진다.
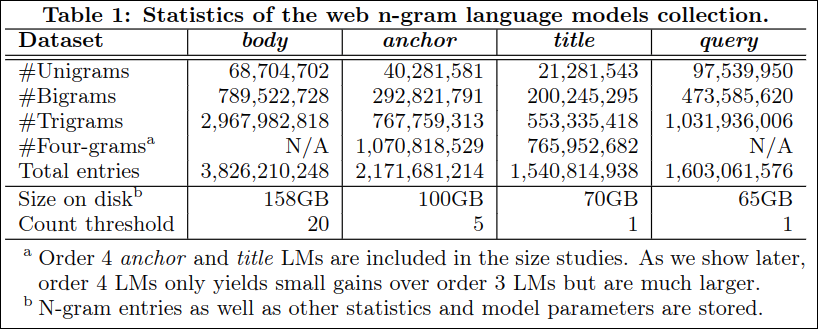
Figure 1은 n-gram order에 따른 query, anchor, title, body의 perplexity를 나타낸다. 이는 733,147개의 쿼리를 돌린 결과이다. 높은 order의 모델은 일반적으로 perplexity가 줄었는데 특히 uni-gram에서 n-gram으로 넘어갈때 수치가 대폭 감소하였다. query LM은 의심할 여지 없이 테스트 쿼리에 대해 가장 잘 예측하였다.
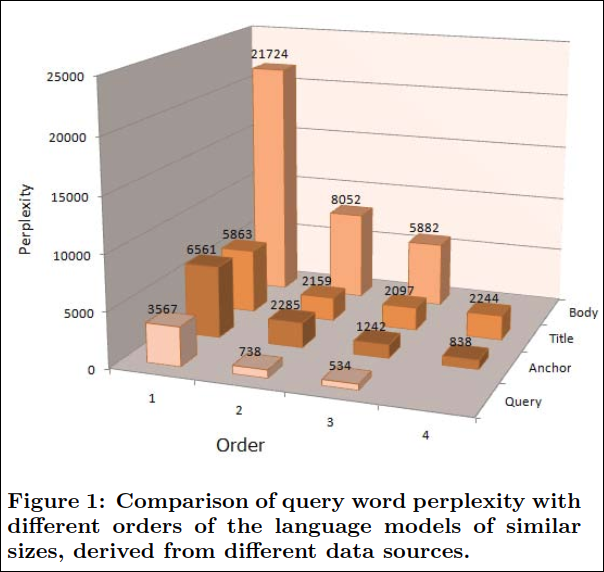
Figure 2는 size와 order에 따라 anchor LM의 perplexity 비교이다.
논문에서는 perplexity와 LM의 size의 관계에 대해 연구하였다. 논문에서는 anchor text LM의 크기를 임계치를 두고 바꾸어보았다. Figure 2에서 관측된것은 perplexity 감소가 log-linear 보다는 느리다는 점이다.(order 2, 3, 4) 하지만 perplexity는 수십억개의 LM이 되더라도 둔화되지 않았다. 사실, 모델 크기를 크게 만드는 것은 드문 n-gram을 더 확보하여 예측 확률을 높여 LM을 더 정확하게 예측할 수 있게 한다. 이것은 기본적으로 모델의 order가 높아짐에 따라 data의 sparsity가 높아져 차원의 저주로 악화 되는 것과 현저한 대조를 이룬다.(이 부분에 대해 필자가 완벽히 이해를 하지 못했는데 여러번 생각해본 결과 앞에서도 논문에서 차원에 저주에 대한 언급이 있던걸로 보았을때 Figure 2에서 order가 높아짐에 따라 perplexity가 낮아진다는 의미보다는 perplexity가 만족스럽더라도 실제로 test dataset이나 상용환경에서 관측되지 않은 단어들로 정확도가 오히려 떨어지는것을 의미하는듯 하다.)
Query Spelling Correction
타이틀과 anchor에 정확한 내용을 입력해 주면 검색 정확도가 높아진다.
Query speller는 검색엔진에서 흔하게 발견되는데 정보 검색의 프로세스를 대폭 향상시킨다. 사용자가 오타를 포함하여 쿼리하면(예: “white zinfandal”) Query speller가 올바른 스펠링 “‘”white zinfandel”를 실시간으로 제안한다.
특별히, language 모델의 결합확률을 랭킹의 feature로 사용한다. 예를들어 k길이의 쿼리 q가 있다면 순서 r을 고려하여 아래와 같이 계산 가능하다.
$P(q) = P(w_1w_2…w_k) = \Pi_{i=1}^{k+1} P(w_i|w_{i-r+1}…w_{i-1}) $
$w_{k+1}$는 올바른 문장 경계인 [/S]이고 $w_i$(i <1)는 왼쪽 문장 경계[S]를 의미한다.
문맥에 민감한 쿼리 스펠링 교정 작업을 위해 15,657개의 쿼리가 랜덤하게 샘플링 되었고 인간이 직접 각 쿼리의 스펠링 교정 정답지를 생성하였다. 테스트 생성 후 약 15%(약 2,349개)의 샘플 쿼리가 스펠링 교정이 필요하다고 발견되었다.
논문의 문맥에 민감한 query speller는 이러한 쿼리에 필요한 교정을 수행한다. 교정을 위한 spelling 후보군이 가지는 랭킹의 성능을 측정하기 위해 논문에서는 precision@1 metric을 사용한다. 예를 들어 첫번재 랭킹의 스펠링 제안이 얼마나 true positive인지 퍼센트를 보는것이다. 이 메트릭은 실용적인 환경에서 중요한 측정지표이다.
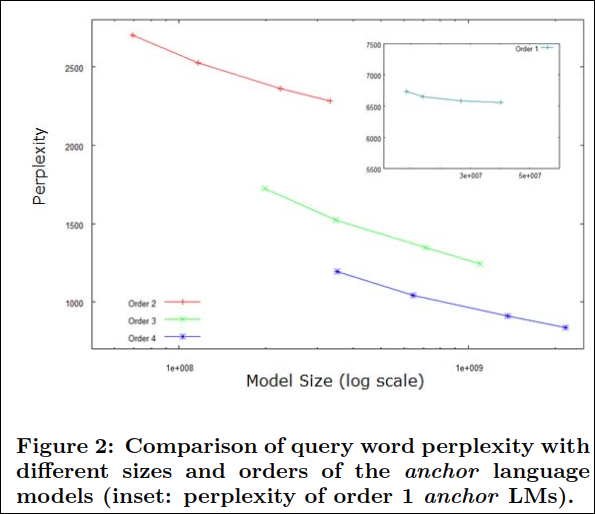
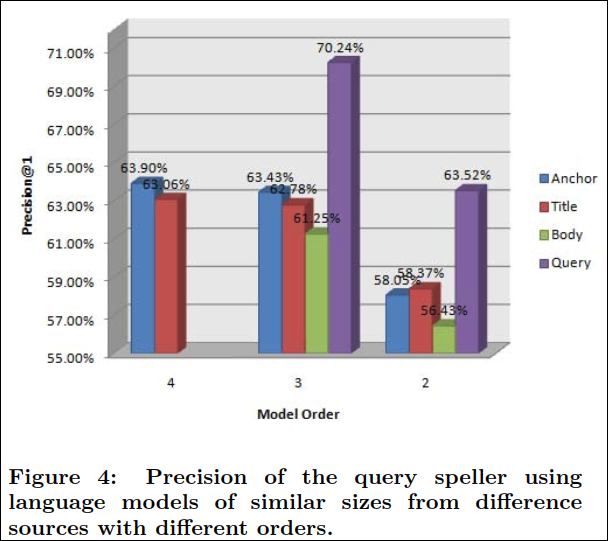
Figure 3는 query speller의 precision@1을 order와 size를 달리하며 anchor LM에 대해 보여주고 있다.
논문에서는 query speller를 anchor LM의 query 결합 확률을 이용하여 이를 랭킹계산의 feature로 사용하였다. Figure 3은 anchor 모델의 크기와 order에 따른 precision@1을 보여주고 있다. Figure 2에서의 perplexity를 살펴본바와 같이 order 2~4의 모델은 크기를 증가시키면서 precision이 개선되었다. 예를 들어, 3-gram 모델의 크기를 100만에서 10억으로 증가시킬때 precision이 5% 향상되었다. 게다가 같은 모델 크기라도 3-gram, 4-gram은 bigram의 성능을 압도하였다. 더욱이 높은 order의 LM의 정확도는 낮은 차수에 비해서 둔화가 훨씬 느리게 일어났다.
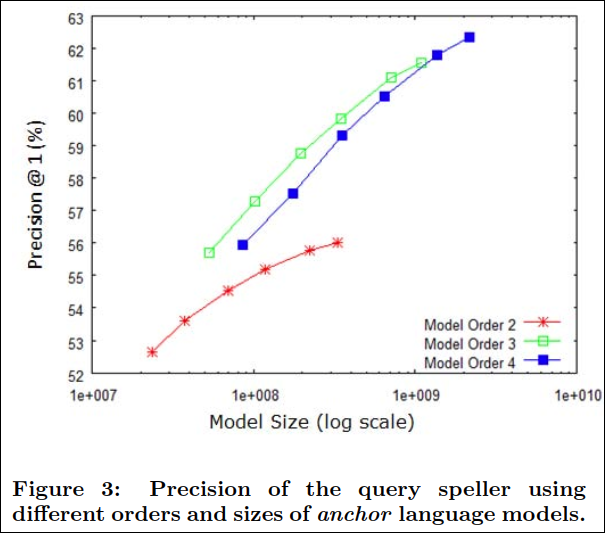
Figure 4는 query speller의 precision을 비슷한 크기의 다른 LM에 대해 차수별로 보여주고 있다.
order에 대해 얘기하자면 3-gram의 LM은 unigram 대비 5~7%의 향상이 있었다. 반면에 4-gram은 매우 적은 0.5%의 향상이 있었다.
data source면에서는 query LM이 문서 기반의 LM에 비해 5~9% 더 높았다. 이것이 놀랍지 않은 이유는 비록 테스트 쿼리와 LM을 만드는데 쓰인 쿼리가 서로 독립적이더라도 같은 “query language”의 “문장”이기 때문이다. 매우 높은 가능성은 쿼리 로그에는 올바른 문법의 문장이 많이 존재한다는 것이다. (필자의 해석은 misspelling의 쿼리와 사람이 교정한 쿼리가 서로 독립적이더라도 워낙 문법에 맞는 문장이 많으니 precision은 높게 나오는게 아니냐는 뜻으로 이해했다.)
document 모델에서는 anchor LM이 title보다 성능이 좋고 title이 body 보다 성능이 좋았다.(odrer 3, 4) 이는 앞서 살펴본것과 같이 anchor text가 title 보다 문법에서 비교적 자유롭고 더 간결하게(예를 들어 명사의 나열) 표현되는 경향이 있기 때문이다. 반면에 title은 더 완전하고 문법에 맞는 문장이 등장한다.
Query Bracketing
괄호지정을 통해 쿼리에 힌트를 주는 기법이다.
예를 들어 “big blue sky”의 경우 괄호 없이 n-gram을 태우면 “big blue”가 포함되어 IBM의 유명한 “big blue”로 검색결과가 영향을 받는 현상이 발생한다. 따라서 논문에서는 length-3 쿼리를 가지고 query bracketing을 연구하였다. length 3을 가지고 진행하는 이유는 괄호가 가능한 최소한의 수치이자 실제 인터넷 환경에서 length 3이하의 쿼리가 전체의 약 20% 정도이므로 의미가 있기 때문이다.
Table 2는 query bracketing annotation 예제이다. 사각형 괄호가 원본 쿼리에 추가되어 bracketing의 선택의 폭을 보여준다. 실제로 논문저자들이 발견한것은 약 60%가 왼쪽 괄호이고 따라서 작업에서 왼쪽 괄호를 baseline으로 사용되었다.

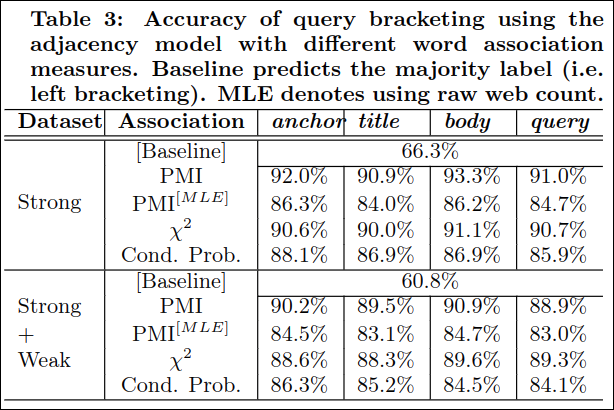
Table 3은 query bracketing의 정확도를 adjacency 모델을 다른 word associaton measure를 사용하며 보여준다. MLE는 raw web count를 표시한다.
query bracketing task에 대해서, adjacency 모델은 매우 정확하게 3 단어의 쿼리의 괄호를 정의했다. 최고의 feature는 93% 이상의 정확도를 얻었고 그러므로 사람이 붙인 anontation과 매우 가까웠다. adjacency 모델이 dependency 모델대비 query bracketing에 더 적절했다. 모든 쿼리가 명사의 조합이 아닌만큼 두 모델은 데이터에 따라 장점이 다를 수 있다.
Long Query Segmentation
- 실제로 많은 상용 검색 엔진의 성능은 이러한 Long Query로 인해 느려진다. 따라서 Long Query 세분화는 검색 엔진의 성능 향상을 위해 분할 하는 것을 목표로 한다.
- Long Query 세분화를 위해 세그먼테이션 모델을 단순화하는 웹 n-gram 언어 모델을 사용한다.
- 이러한 중요성에도 불구하고 이 분야의 관련 연구는 상대적으로 적다.
- 분할 기술은 구문 분석 트리 구조를 생성한다. 이 구조는 사람의 해석과 인접 순위 지정에 더 유용하다.
- Long Query 분할를 위해 Long Query는 일반적으로 특정한 것을 정의하는 키워드 / 개념 (주로 명사구) 연결로 구성된다. 따라서 term 대신에 세그먼트가 분석을 위한 좋은 단위이다.
- 또한, 각 세그먼트는 파싱 트리 구조 (세분화 트리라고 함)에서 가장 잘 표현 될 수 있는 자체 하부 구조를 가질 수 있다. 앞 페이지에서 Query Bracketing을 위한 단어 연관의 다양한 측정을 사용하는 것과 유사하게, Long Query를 세그먼트화 하기 위한 기준으로 세그먼트의 독립 정도를 사용할 수 있다.
Figure 5는 long query를 분할(Segmentating) 하여 segmentation tree 구조로 나타내는 것의 예제이다.
Figure 5는 긴 쿼리의 예제로 (raleigh serengeti mountain bike)와 쇼핑 사이트 (canadian tire)를 예로 들고 있다. 그러므로 terms 대신에 세그먼트는 분석을 위한 좋은 단위이다. 더욱이, 각 세그먼트는 자식의 부분구조를 가질 수 있고 이것은 tree 구조로 파싱 될 수 있다. 이 예제에서 세그먼트 (raleigh serengeti)는 쇼핑 사이트 보다는 브랜드 이름으로 얻어진다. segmation 트리는 또한 원하는 segmantation의 형태로 선택할수 있게 practitioner에 유연성을 부여한다. (예를 들어 raleigh serengeti mountain bike 세그먼트를 2개의 부분으로 나눌지)
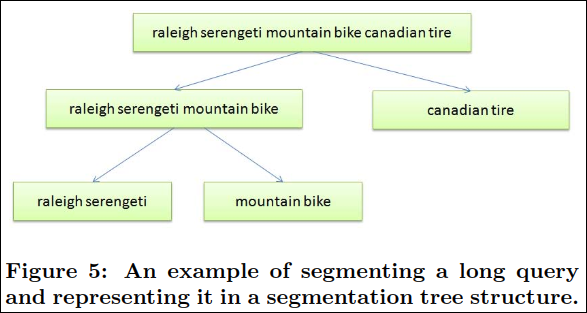
Figure 6는 다른 granuality에 따른 setgementation tree의 성능을 나타낸다.(anchor LM)
거친 segmation 트리는 대부분의 cover case를 가진다. 대부분의 cover 케이스는 exact 매치를 변환되어 exact(leaf) match 율이 가파르게 상승한다. 0.12 violation rate 근처가 터닝포인트인데 여기서 정점을 찍고 exact leaf rate가 악화되기 시작한다. 이부분 이후로 exact match rate는 violation rate보다 느리게 성장한다. 이 부분에서 violation rate를 설정하는 것은 알고리즘이 사람이 annotation한것 대비 약 70%의 세그먼트를 발견할 수 있었다.
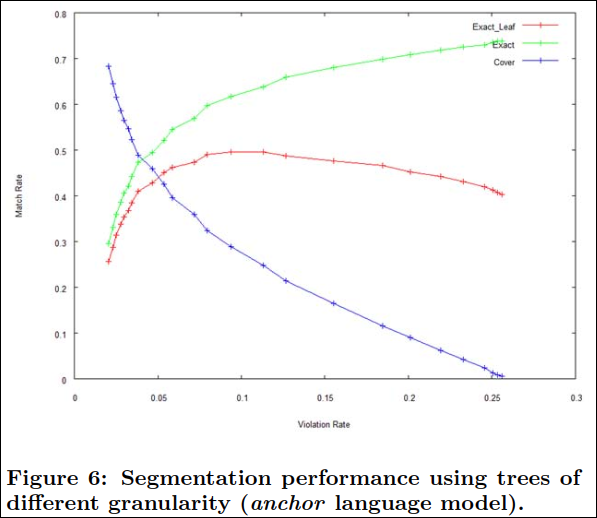
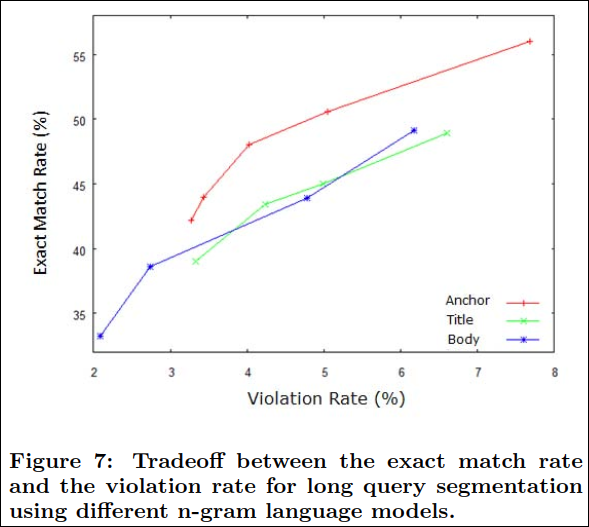
Figure 7은 long query segmation을 다른 n-gram LM 에 대해 extact match rate와 violation rate에 대한 tradeoff를 보여준다.
ROC curve와 유사하게 커브는 대부분의 커브 아래쪽 면적이 넓을수록 best이다. LM 사이에서 anchor는 뚜렷하게 최고의 성능을 획득한다. 이것의 이유는 anchor text는 대부분 단일 혹은 키워드의 조합으로써 long 쿼리를 구성되는 방식과 가장 유사하기 때문이다. body와 title의 성능차이는 이 케이스에서는 특별히 드러나지 않는다.
Conclusion
- 광활한 월드 와이드 웹은 야생에서 자유롭게 사용할 수 있는 엄청난 양의 보물을 제공한다.
- n-gram 언어 모델을 선택하여 레이블이 지정되지 않은 필터링 되지 않은 웹 데이터에서 웹 언어 정보를 찾아낸다.
- 웹 스케일 언어 모델링 기술의 최근 발전으로 인해 우리는 anchor texts, title 및 문서 body 뿐만 아니라 검색 쿼리를 포함한 웹 문서 소스로부터 언어 모델을 만들었다.
- 저자는 anchor texts나 title로 문서를 요약하는 방법과 가장 유사한 방식으로 웹 검색 쿼리를 구성해야 한다고 제안한다. 실제로 웹 언어 모델은 웹 검색 엔진에서 다양한 문서 및 쿼리 처리 작업에 적용될 수 있다.
- 이 논문에서 SQP (Search Query Processing) 에 대해 아래 3가지 방법을 제안한다.
- 상황에 맞는 Query spelling correction으로 언어의 차이가 실제 응용 프로그램의 정확도와 어떻게 다른지 관찰
- 3-word 질의에 대한 sub-query bracketing 구조를 분석하고
- 웹 언어 모델을 사용하여 새로운 계층적 long 질의 분할 방법을 제안한다.