개요
hive 성능 개선과 관련된 블로그 글을 읽고 정리해둔다. 기본적으로 hadoop 및 hive에 대한 기본 이해가 있다는것이 전제가 되는 글이다.
1. partitioning
칼럼 읽는 양을 파티션을 통해 줄여 disk i/o time을 줄이고 그 결과 쿼리 퍼포먼스가 좋아짐
사용법 예제는 아래와 같다.
CREATE TABLE table_name (column1 data_type, column2 data_type, …) PARTITIONED BY (partition1 data_type, partition2 data_type,….);
2. bucketing
칼럼 중에 high cardinality 값이면 추가로 value에 따라 bucket hash를 돌려 데이터 프로젝션 효율을 증대시킴
사용법 예제는 아래와 같고 CLUSTERED BY 를 사용한다.
CREATE TABLE table_name (column1 data_type, column2 data_type, …) PARTITIONED BY (partition1 data_type, partition2 data_type,….) CLUSTERED BY (clus_col1) SORTED BY (sort_col2) INTO n BUCKETS;
3. Using Tez as Execution Engine
Tez는 클라이언트 사이트 execution engine이고 DAG 구성 프로세싱을 더 빠르게 도와준다.
이부분은 테스트 및 검증이 많이 필요할듯 하다. 참고로 hive3 부터 tez engine이 기본인것으로 알고 있다.
4. Using Compression
zipped sequence file로 압축하면 CPU를 더 쓸수는 있지만 I/O 시간을 줄일 수 있다.
5. Using ORC Format
ORC는 아래와 같은 장점을 가짐
- 높은 level의 compression,
orc.compress로 알고리즘 변경가능, default는 zlib - 만약 쿼리에 부합하지 않는 블럭 내의 전체 범위의 row를 skip할 수 있음
- skip 되는 row들은 decompression도 하지 않음
- 각 task의 output을 단일 file들로 생성하여 네임 노드의 부하를 감소시킴
- 파일을 동시에 읽기위해 다중 스트림을 지원함
- 파일내의 메타데이터를 protocol buffer를 사용하여 보관함(구조화된 데이터 serialization용도)
ORC 구조는 아래와 같은데 하나의 ORC 파일은 여러개의 stripe로 구성될 수 있고 하나의 stripe 안에서 칼럼은 각각 compress되어 있으며 query 조건에 부합하여 값을 꺼내야 하는 column만 decompress한다.
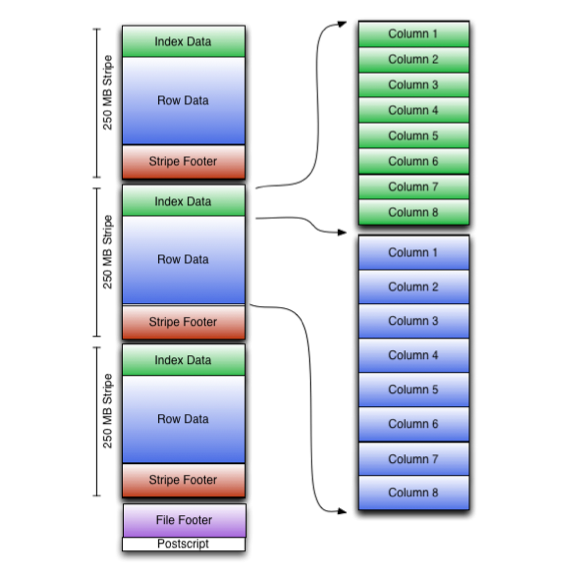
stripe 데이터는 아래 3가지로 구성된다.
1. stripe footer는 디렉토리의 stream location을 가리킴
2. row data 는 테이블 스캔에 사용되고 default로 1만 row를 가짐
3. index data는 각 칼럼의 min, max 값을 가짐
ORC 를 사용하면 아래의 최적화가 적용된다.
Push-down Predicates
ORC reader로 쿼리 where 조건이 전달 되는데 전체 블럭의 칼럼 값에서 index data를 순회시 min, max값 내로 블럭 내 전체 값이 해당되지 않으면 블럭 전체를 skip함
Bloom Filters
bloom filter는 메모리 내에 최소 공간으로 element의 존재 여부를 알아 낼 수 있다. bloom filter는 push-down 예측을 도와준다. bloom filter에 의해 원소가 존재한다고 판단되었을때는 실제로 원소가 있을수도 있고 없을수도 있지만 원소가 존재하지 않는다고 판단되었을때는 실제로 존재하지 않을 확률이 100%다. wiki 참고 따라서 이 점을 이용 하여 push-down 예측시 where절에 해당하는 범위에 값이 있는지를 효율적으로 판단한다.
ORC Compression
orc 포맷은 칼럼 값을 compress 할 뿐만 아니라 stripe도 통째로 compress한다. compress 알고리즘은 아래 중에 선택 가능하다.
- zlib : higher compression, more cpu
- snappy : less compression, less cpu
- none : none
Vectorization
scannig, filtering, aggregations, join 등의 연산은 vectorized query execution으로 성능 향상이 가능하다. 기본 query 실행 프로세스에서는 row/time으로 처리한다. 반면 vectorization 은 1024 블럭의 row을 time마다 처리한다.
vectorized query execution을 사용하기 위해 ORC format을 반드시 써야 하며 HQL에 아래의 변수를 설정해야 한다.
set hive.vectorized.execution.enabled = true;
set hive.vectorized.execution.reduce.enabled=true
set hive.vectorized.execution.reduce.groupby.enabled=true
쿼리가 백터화 해서 실행되는지는 explain 명령어를 실행했을 때 Execution mode: vectorized가 뜨는지 보면 된다.
6. Join Optimizations
Multi-way Join
hive 가 아래와 같이 계속 사용되는 b의 key1으로 sorting 이후 join 을 수행하는 optimization을 해준다.
Map Join
set hive.auto.convert.join=true;
set hive.auto.convert.join.noconditionaltask = true;
set hive.auto.convert.join.noconditionaltask.size = 10000000;
Bucket Map Join
SMB Join
set hive.input.format= org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
Skew Join
7. Cost-based Optimizations
Cost Based Optimization은 아래의 장점을 가져옴
Logical Optimizations:
- Projection Pruning
- Deducing Transitive Predicates
- Predicate Pushdown
- Merging of Select-Select, Filter-Filter into a single operator
- Multi-way Join
- Query Rewrite to accommodate for Join skew on some column values
Physical Optimizations:
- Partition Pruning
- Scan pruning based on partitions and bucketing
- Scan pruning if a query is based on sampling
- Apply Group By on the map side in some cases
- Optimize Union so that union can be performed on map side only
- Decide which table to stream last, based on user hint, in a multiway join
- Remove unnecessary reduce sink operators
- For queries with limit clause, reduce the number of files that needs to be scanned for the table.
CBO 활성화는 hive-stie.xml에 hive.cbo.enable=true를 명시하면 된다.
CBO를 위해 쓰이는 각 테이블의 통계는 hive.stats.autogather=ture 혹은 analyze 명령어에 의해 획득할 수 있다.
Reference
- https://towardsdatascience.com/apache-hive-optimization-techniques-1-ce55331dbf5e
- https://towardsdatascience.com/apache-hive-optimization-techniques-2-e60b6200eeca