개요
자바8 스트림 API에대해 살펴보며 성능이 기존 대비 차이가 있는지 궁금하였습니다. 이에 따라 구글링을 좀 해보니
아마존에 근무하는 개발자 블로그에서 간단한 Article 리스트를 만들어 아래의 기능들을 벤치마킹 해놓은 결과가 있었습니다.
해당 개발자가 테스트 코드를 github에 공개해 놓아 이를 fork하여 parallel API를 활용하게끔 확장하여 벤치마킹을 직접 해보았습니다.
벤치마크 내용
- 10만개의 Article로 테스트
- 아래의 4가지 메서드 테스트
- “JAVA”가 첫번재로 등장하는 Article을 찾아 리턴
- “JAVA”가 등장하는 모든 Article을 조회
- distict
- group by
- 위의 4가지 메서드를 아래의 방법으로 테스트
- 기본 for loop
- stream API 사용
- stream API를 parallel 옵션으로 사용
벤치마크 코드 일부
public class Article {
private final String title;
private final String author;
private final List<String> tags;
public Article(String title, String author, List<String> tags) {
this.title = title;
this.author = author;
this.tags = tags;
}
public String getTitle() {
return title;
}
public String getAuthor() {
return author;
}
public List<String> getTags() {
return tags;
}
}
public class ArticleOps {
private final List<Article> articles;
public ArticleOps(List<Article> articles) {
this.articles = articles;
}
public Article getFirstJavaArticle_loop() {
for (Article article : articles) {
if (article.getTags().contains("Java")) {
return article;
}
}
return null;
}
public Optional<Article> getFirstJavaArticle_stream() {
return articles.stream().filter(article -> article.getTags().contains("Java")).findFirst();
}
public Optional<Article> getFirstJavaArticle_stream_parallel() {
return articles.stream().parallel().filter(article -> article.getTags().contains("Java")).findFirst();
}
public List<Article> getAllJavaArticles_loop() {
List<Article> result = new ArrayList<>();
for (Article article : articles) {
if (article.getTags().contains("Java")) {
result.add(article);
}
}
return result;
}
public List<Article> getAllJavaArticles_stream() {
return articles.stream().filter(article -> article.getTags().contains("Java")).collect(Collectors.toList());
}
public List<Article> getAllJavaArticles_stream_parallel() {
return articles.stream().parallel().filter(article -> article.getTags().contains("Java"))
.collect(Collectors.toList());
}
public Map<String, List<Article>> groupByAuthor_loop() {
Map<String, List<Article>> result = new HashMap<>();
for (Article article : articles) {
if (result.containsKey(article.getAuthor())) {
result.get(article.getAuthor()).add(article);
} else {
ArrayList<Article> articles = new ArrayList<>();
articles.add(article);
result.put(article.getAuthor(), articles);
}
}
return result;
}
public Map<String, List<Article>> groupByAuthor_stream() {
return articles.stream().collect(Collectors.groupingBy(Article::getAuthor));
}
public Map<String, List<Article>> groupByAuthor_stream_parallel() {
return articles.stream().parallel().collect(Collectors.groupingBy(Article::getAuthor));
}
public Set<String> getDistinctTags_loop() {
Set<String> result = new HashSet<>();
for (Article article : articles) {
result.addAll(article.getTags());
}
return result;
}
public Set<String> getDistinctTags_stream() {
return articles.stream().flatMap(article -> article.getTags().stream()).collect(Collectors.toSet());
}
public Set<String> getDistinctTags_stream_parallel() {
return articles.stream().parallel().flatMap(article -> article.getTags().stream().parallel()).collect(Collectors.toSet());
}
}
벤치마크 환경
- CPU : Intel(R) Xeon(R) CPU E5-2609 v2 @ 2.50GHz
- RAM : 64 GB
- OS : Ubuntu 14.04 LTS 벤치마크 결과 벤치마크 결과는 아래와 같습니다.
10만개 성능비교
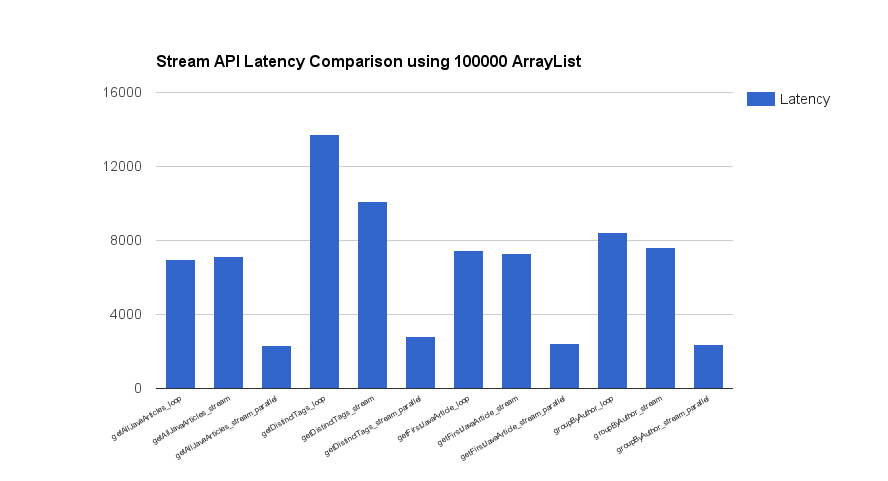
10만개 벤치마크 세부결과
| Benchmark | Mode | Samples | Score | Error | Units |
|---|---|---|---|---|---|
| getAllJavaArticles_loop_benchmark | avgt | 10 | 6969.140 | ±34.281 | us/op |
| getAllJavaArticles_stream_benchmark | avgt | 10 | 7126.620 | ±88.946 | us/op |
| getAllJavaArticles_stream_parallel_benchmark | avgt | 10 | 2304.584 | ±20.797 | us/op |
| getDistinctTags_loop_benchmark | avgt | 10 | 13716.768 | ±52.438 | us/op |
| getDistinctTags_stream_benchmark | avgt | 10 | 10112.799 | ±522.467 | us/op |
| getDistinctTags_stream_parallel_benchmark | avgt | 10 | 2803.752 | ±62.616 | us/op |
| getFirstJavaArticle_loop_benchmark | avgt | 10 | 7457.977 | ±47.366 | us/op |
| getFirstJavaArticle_stream_benchmark | avgt | 10 | 7308.036 | ±37.527 | us/op |
| getFirstJavaArticle_stream_parallel_benchmark | avgt | 10 | 2406.746 | ±30.961 | us/op |
| groupByAuthor_loop_benchmark | avgt | 10 | 8455.549 | ±818.356 | us/op |
| groupByAuthor_stream_benchmark | avgt | 10 | 7610.899 | ±2016.121 | us/op |
| groupByAuthor_stream_parallel_benchmark | avgt | 10 | 2371.920 | ±137.847 | us/op |
100개 성능비교
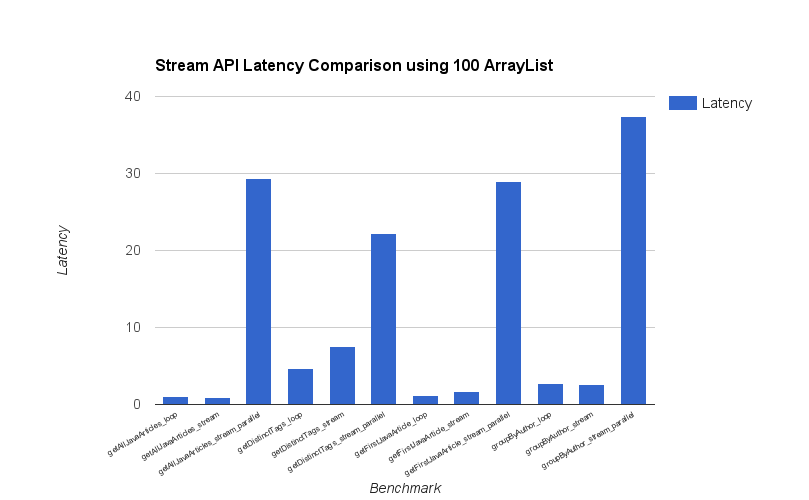
100개 벤치마크 세부결과
| Benchmark | Mode | Samples | Score | Error | Units |
|---|---|---|---|---|---|
| getAllJavaArticles_loop_benchmark | avgt | 10 | 1.059 | ±0.007 | us/op |
| getAllJavaArticles_stream_benchmark | avgt | 10 | 0.875 | ±0.005 | us/op |
| getAllJavaArticles_stream_parallel_benchmark | avgt | 10 | 29.325 | ±0.544 | us/op |
| getDistinctTags_loop_benchmark | avgt | 10 | 4.705 | ±0.055 | us/op |
| getDistinctTags_stream_benchmark | avgt | 10 | 7.588 | ±0.185 | us/op |
| getDistinctTags_stream_parallel_benchmark | avgt | 10 | 22.180 | ±0.739 | us/op |
| getFirstJavaArticle_loop_benchmark | avgt | 10 | 1.159 | ±0.011 | us/op |
| getFirstJavaArticle_stream_benchmark | avgt | 10 | 1.659 | ±0.024 | us/op |
| getFirstJavaArticle_stream_parallel_benchmark | avgt | 10 | 28.992 | ±0.911 | us/op |
| groupByAuthor_loop_benchmark | avgt | 10 | 2.734 | ±0.044 | us/op |
| groupByAuthor_stream_benchmark | avgt | 10 | 2.645 | ±0.057 | us/op |
| groupByAuthor_stream_parallel_benchmark | avgt | 10 | 37.355 | ±5.392 | us/op |
결론
- 10만개의 테스트에서 확인한 것은 parallel의 경우 월등히 설능이 빠릅니다. 다만, 모든 CPU 코어의 사용률이 100% 가까이 치솟았습니다. -> 성능은 확실하지만 코드에서 사용시에 유념해야 할듯 합니다.
- 10만개 테스트 시에는 distinct를 제외하고는 기본 loop와 stream API 성능이 비슷한 것을 확인 할 수 있습니다. 따라서 기호에 맞게 API를 사용하면 되는데 코드 간결성 및 활용도를 생각해서 Stream API를 적극 사용하는 것이 나쁘지 않아 보입니다.
- 100개 테스트 에서는 parallel이 오히려 성능이 월등히 나쁜것을 확인 할 수 있습니다. -> 병렬 처리 등을 위해 쓰레드를 내부적으로 생성하는 등의 오버헤드가 더 클것으로 보입니다.
