개요
텐서플로우 튜토리얼의 Linear Models 중에 필요한 부분만 정리해둔다.
모델 실행법
- 코드 repository 클론
- 데이터셋 다운로드 및 코드 실행
아래와 같이 코드를 실행한다.
Feature 다루기
카테고리 Feature
CSV에서 숫자갑이 아닌 아래와 같이 정해진 카테고리의 필드가 있다면 아래와 같이 손쉽게 0부터 auto increment되는 정수로 바꿀 수 있다.
relationship = tf.feature_column.categorical_column_with_vocabulary_list(
'relationship', [
'Husband', 'Not-in-family', 'Wife', 'Own-child', 'Unmarried',
'Other-relative'])
값의 범위가 정해지지 않은 데이터셋도 아래와 같이 해시화 하여 수치로 바꿀 수 있다. 해시이기 때문에 conflict가 날 수 있지만 모델 학습에 있어 대세에 지장은 없다고 설명하고 있다.(하지만 필자 생각엔 조금 유의하긴 해야할 듯 하다.)
occupation = tf.feature_column.categorical_column_with_hash_bucket(
'occupation', hash_bucket_size=1000)
숫자값
숫자값은 아래와 같이 평범하게 처리 할 수 있다.
age = tf.feature_column.numeric_column('age')
education_num = tf.feature_column.numeric_column('education_num')
capital_gain = tf.feature_column.numeric_column('capital_gain')
capital_loss = tf.feature_column.numeric_column('capital_loss')
hours_per_week = tf.feature_column.numeric_column('hours_per_week')
숫자값 Bucketization
예를 들어 연봉 예측에 있어 나이는 단순한 정비례/반비례 관계가 아닐 수 있다. 예를 들어 사회 초년생때는 연봉이 적고 점차 늘지만 은퇴 이후에는 다시 감소하는 양상이 나타날 수 있기 때문이다. 그런데 이부분을 feature를 가공해 주지 않으면 단순 로지스틱 Regression에서는 아래의 상관관계만 존재 할 수 있기 때문에 모델성능이 좋지 않게 나올 수 있다.
- 양의 상관관계
- 음의 상관관계
- 상관관계 없음
따라서 아래와 같이 18세 미만, 18세~24세, 25~29세, 65세 초과 등으로 그룹을 나누는게 효과적이다.
age_buckets = tf.feature_column.bucketized_column(
age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
CrossedColumn
feature중에 단일 feature로 설명되지 않는 복합적인 경우가 발생할 수 있다. 예를 들어 학력(석사나 학사)로 가중치를 측정할 수는 있지만 학사이면서 의사인 경우나 학사이면서 대학원생인 경우와 같은 조합의 관계는 설명되지 않을 수 있다. 따라서 아래와 같이 복합 feature를 정하여 이 부분에도 가중치를 부여할 수 있다.
education_x_occupation = tf.feature_column.crossed_column(
['education', 'occupation'], hash_bucket_size=1000)
CrossedColumn은 꼭 2개가 아니어도 되고 복수개를 지정할 수 있다.
[age_buckets, ‘education’, ‘occupation’], hash_bucket_size=1000)
모델 지정
위에서 정의한 feature를 가지고 아래와 같이 LinearClassifier를 지정할 수 있다.
base_columns = [
education, marital_status, relationship, workclass, occupation,
age_buckets,
]
crossed_columns = [
tf.feature_column.crossed_column(
['education', 'occupation'], hash_bucket_size=1000),
tf.feature_column.crossed_column(
[age_buckets, 'education', 'occupation'], hash_bucket_size=1000),
]
model_dir = tempfile.mkdtemp()
model = tf.estimator.LinearClassifier(
model_dir=model_dir, feature_columns=base_columns + crossed_columns)
모델 학습 및 평가
모델 학슴은 아래와 같이 가능하다.
또한 모델 평가는 아래와 같이 가능하다.
results = model.evaluate(input_fn=lambda: input_fn(
test_data, 1, False, batch_size))
for key in sorted(results):
print('%s: %s' % (key, results[key]))
오버피팅 방지를 위한 Regularization
Regularization은 아래와 같이 가능하다. 이때 L1, L2 Regularization에 각각 특징이 있으니 궁금하면 따로 공부하자.
model = tf.estimator.LinearClassifier(
model_dir=model_dir, feature_columns=base_columns + crossed_columns,
optimizer=tf.train.FtrlOptimizer(
learning_rate=0.1,
l1_regularization_strength=1.0,
l2_regularization_strength=1.0))
로지스틱 Regression
위 모델의 원리는 아래의 가설함수를 사용하는 것이다.
$$ P(Y=1|X) = \frac{1}{1+ exp(-(W^T X + b))} $$
위 수식의 의미는 필자가 정리한 코세라 강의 중 로지스틱 Regression 부분을 보면 자세히 나와 있다.
간략히 슬라이드 하나만 발췌하면 아래에서 얘기하는 수식이다.
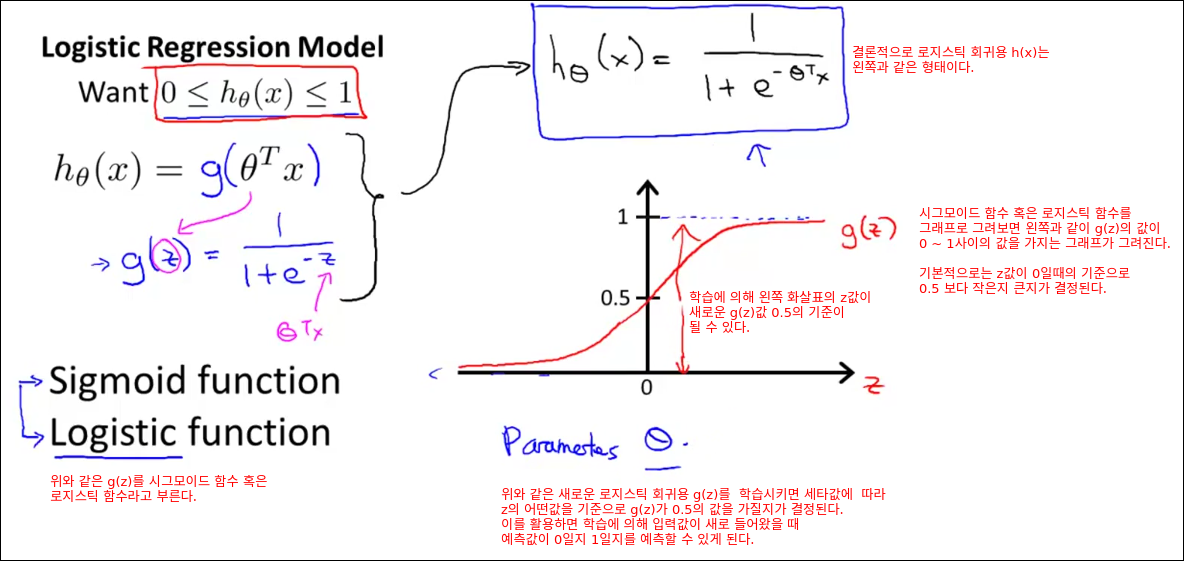
위의 가설함수를 통해 loss fuction을 정의하여 Cost를 최소화 하는 문제로 데이터를 이용하여 문제를 푼다.
조금 더 배우고 싶다면
다음 챕터인 Wide & Deep Learning Tutorial를 참고한다.