개요
현재 멜론에서 분석용 ES 장비를 15대 정도 운영하고 있다. (총 4개의 다른종류의 검색 클러스터를 보유)
현재 분석 장비를 사내에서는 live로 색인/검색 요청을 받기 때문에 어쩌다가 rolling restart를 수행해야 할때(이를테면 설정파일 변경) 전체 클러스터를 내리지 않고 튜닝을 진행하는데 고통스러웠다. 따라서 이부분은 분석계 장비 튜닝을 안정적이고 적극적으로 수행하기 위해 Rolling Restart의 자동화가 필요하다고 판단했고 이부분을 Ansible로 구현하여 정리해둔다.
다른분들도 도움이 될까봐 Ansible 스크립트를 공유하는데 대신 돌리기만 하면 되는 형태는 아니고 부득이 조금의 커스터마이징이 필요한점은 염두해 두자.
롤링 재시작 혹은 업그레이드에 대한 프로세스(개념)은 엘라스틱서치(ES) 클러스터 재시작 혹은 업그레이드 Tip를 참고하자.
아래 롤링 재시작 Ansible 스크립트가 최적화가 되어있다고 생각하지는 않지만 장점은 상용에서 검증이 되었다는 점 정도 되겠다.
동작원리
기본 동작 방식은 아래와 같다.
- Ansible 숙주 서버 -> ES 장비#1 ~ #N
다만 기존 Ansible 세계관이 SSH로 각 장비에서 Ansible이 실행되는 구조라면 필자가 택한 방식은 Ansible 숙주 서버에서 ES REST API로 대부분의 클러스터 상태 체크나 샤드 할당 비활성화 등을 실행하고 ES 종료 및 시작은 SSH 스크립트를 통해 원격지 장비에 명령을 내리는 특이한 구조를 지닌다.
위와 같이 변형이 된 이유는 아래와 같다.
- 필자의 회사에서는 ES 분석계는 외부망 통신이 끊겨 있고 EPEL 사용도 쉽지 않아 Ansible 설치 등도 순탄치가 않다.
- 필자의 목적성은 최대한 관리를 심플하고 효율적으로 관리하는 것인데 이 면에서도 필자 혼자 이런 Devops류를 챙겨야 하는 입장에서는 숙주 서버에서 Ansible을 관리하는것이 편하다고 판단했다.
Ansible 스크립트
다시 한번 얘기하지만 아래의 스크립트는 Ansible 실행이 각 ES장비가 아닌 숙주 서버에서만 일어남을 유의하자. 아래 스크립트에서 start-remote-daemon.sh나 stop-remote-daemon.sh는 SSH로 실제 ES 장비의 데몬을 시작/종료하는 역할만 담당한다.
또한 데뷰에서 네이버쪽에서 발표한 ES관련 노하우에서도 얘기하듯이 Rolling restart나 upgrade시에는 색인을 잠시 중단하여야 한다. (적어도 필자는 이게 맞다고 판단한다.)
rolling_restart.yml
# Ansible
# Rolling Restart of Elasticsearch
# author: Kwangsik Lee(lks21c@gmail.com)
# modified from https://github.com/ekhoinc/ansible-examples/blob/master/elasticsearch-rolling-upgrade.yml
# tested with Ansible 2.4.3 with ES 5.5.0 on Centos7
- name: "inner_rolling_start"
# This is tested on melon.com with 14 nodes in a cluster.
# You should Modify hosts to match your inventory group strategy.
# such as:
# hosts: tag_Services_elasticsearch:&tag_Environment_production
hosts: localhost
# Below enables running playbook on hosts sequentially.
serial: 1
vars:
es_disable_allocation: '{"transient":{"cluster.routing.allocation.enable":"none"}}'
es_enable_allocation: '{"transient":{"cluster.routing.allocation.enable": "all"}}'
es_path: '/home/upsadm/elasticsearch'
es_master_url: "마스터URL"
es_master_http_port: "마스터 노드 HTTP 포트번호"
ssh_user: "SSH 계정명"
tasks:
- debug:
msg: main task
- include_tasks: inner_rolling_restart.yml
with_items:
- 서버명 #1
- 서버명 #2
inner_rolling_restart.yml
---
- set_fact:
outer_item: "{{ item }}"
# the ansible the uri action needs httplib2
# you should replace yum to apt if you use Ubuntu.
- name: ensure python-httplib2 is installed
yum: name=python-httplib2 state=present
- name: check current version
uri:
url: "http://{{es_master_url}}:{{ es_master_http_port }}"
method: GET
register: version_found
retries: 10
delay: 10
- name: Display Current Elasticsearch Version
debug: var=version_found.json.version.number
- name: Disable shard allocation for the cluster
uri:
url: 'http://{{es_master_url}}:{{ es_master_http_port }}/_cluster/settings'
method: PUT
body: "{{ es_disable_allocation }}"
body_format: json
register: response
# next line is boolean not string, so no quotes around true
# use python truthiness
until: "response.json.acknowledged == true"
retries: 5
delay: 30
- name: Synced Flush
uri:
url: 'http://{{es_master_url}}:{{ es_master_http_port }}/_flush/synced'
method: POST
register: response
# next line is boolean not string, so no quotes around true
# use python truthiness
until: "response.json._shards.failed == 0"
retries: 5
delay: 30
- debug:
msg: "Shutdown {{outer_item}}"
- name: Shutdown elasticsearch node
script: "{{es_path}}/script/stop-remote-data.sh {{ssh_user}}@{{outer_item}}"
ignore_errors: yes
- name: Wait for elasticsearch node to come back up
pause:
seconds: 30
- name: Wait for all shards to be reallocated
uri:
url: "http://{{es_master_url}}:{{ es_master_http_port }}/_cluster/health"
method: GET
register: response
until: "response.json.relocating_shards == 0"
retries: 10
delay: 30
- name: add permission to elasticsearch start script
file:
path: "{{es_path}}/script/start-remote-data.sh"
mode: 0755
- debug:
msg: "starting {{outer_item}}"
- name: Start elasticsearch
script: "{{es_path}}/script/start-remote-data.sh {{ssh_user}}@{{outer_item}}"
- name: Enable shard allocation for the cluster
uri:
url: "http://{{es_master_url}}:{{ es_master_http_port }}/_cluster/settings"
method: PUT
body: '{{ es_enable_allocation }}'
body_format: json
register: response
# next line is boolean not string, so no quotes around true
# use python truthiness
until: "response.json.acknowledged == true"
retries: 5
delay: 30
- name: Wait for cluster health to return to yellow or green
uri:
url: "http://{{es_master_url}}:{{ es_master_http_port }}/_cluster/health"
method: GET
register: response
until: "response.json.status == 'green'"
retries: 120
delay: 30
inner_rolling_restart.yml 개선버전
실제 상용에서 활용했을때 필자의 경우 Master가 “Disable shard allocation for the cluster”와 같은 작업에서 응답을 늦게 주는 경우가 있어 아래와 같이 스크립트를 수정하여 사용중이다.
---
- set_fact:
outer_item: "{{ item }}"
- name: ensure python-httplib2 is installed
yum: name=python-httplib2 state=present
- name: check current version
uri:
url: "http://{{es_master_url}}:{{ es_master_http_port }}"
method: GET
register: version_found
retries: 10
delay: 10
- name: Display Current Elasticsearch Version
debug: var=version_found.json.version.number
- name: Disable shard allocation for the cluster
uri:
url: 'http://{{es_master_url}}:{{ es_master_http_port }}/_cluster/settings'
method: PUT
body: "{{ es_disable_allocation }}"
body_format: json
register: response
# until: "response.json.transient.cluster.routing.allocation.enabled == none"
until: "response['status']|default(0) == 200"
retries: 30
delay: 120
#- name: Synced Flush
# uri:
# url: 'http://{{es_master_url}}:{{ es_master_http_port }}/_flush/synced'
# method: POST
# register: response
# until: "response.json._shards.failed == 0"
# retries: 30
# delay: 30
- debug:
msg: "Shutdown {{outer_item}}"
- name: Shutdown elasticsearch node
script: "{{es_path}}/script/stop-remote-data.sh {{ssh_user}}@{{outer_item}}"
ignore_errors: yes
- name: Wait for elasticsearch node to come back up
pause:
seconds: 30
- name: Wait for all shards to be reallocated
uri:
url: "http://{{es_master_url}}:{{ es_master_http_port }}/_cluster/health"
method: GET
register: response
until: "response.json.relocating_shards == 0"
retries: 10
delay: 30
- name: add permission to elasticsearch start script
file:
path: "{{es_path}}/script/start-remote-data.sh"
mode: 0755
- debug:
msg: "starting {{outer_item}}"
- name: Start elasticsearch
script: "{{es_path}}/script/start-remote-data.sh {{ssh_user}}@{{outer_item}}"
- name: Enable shard allocation for the cluster
uri:
url: "http://{{es_master_url}}:{{ es_master_http_port }}/_cluster/settings"
method: PUT
body: '{{ es_enable_allocation }}'
body_format: json
register: response
# until: "response.json.transient.cluster.routing.allocation.enabled == all"
until: "response['status']|default(0) == 200"
retries: 30
delay: 120
- name: Wait for cluster health to return to yellow or green
uri:
url: "http://{{es_master_url}}:{{ es_master_http_port }}/_cluster/health"
method: GET
register: response
until: "response.json.status == 'green'"
retries: 360
delay: 30
동작화면
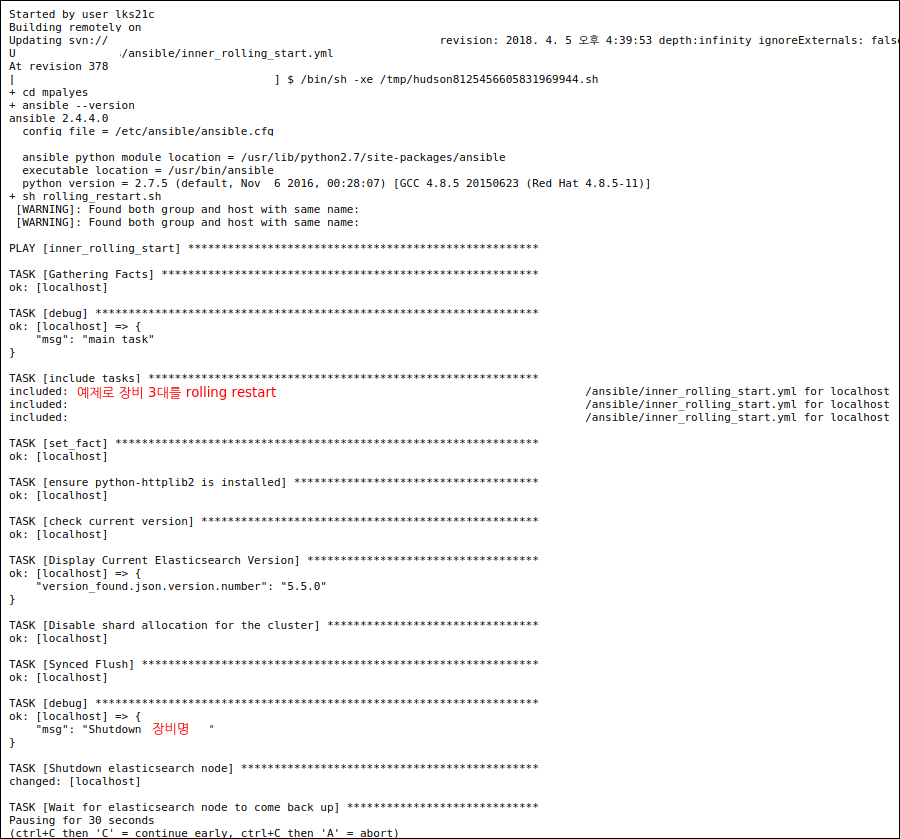
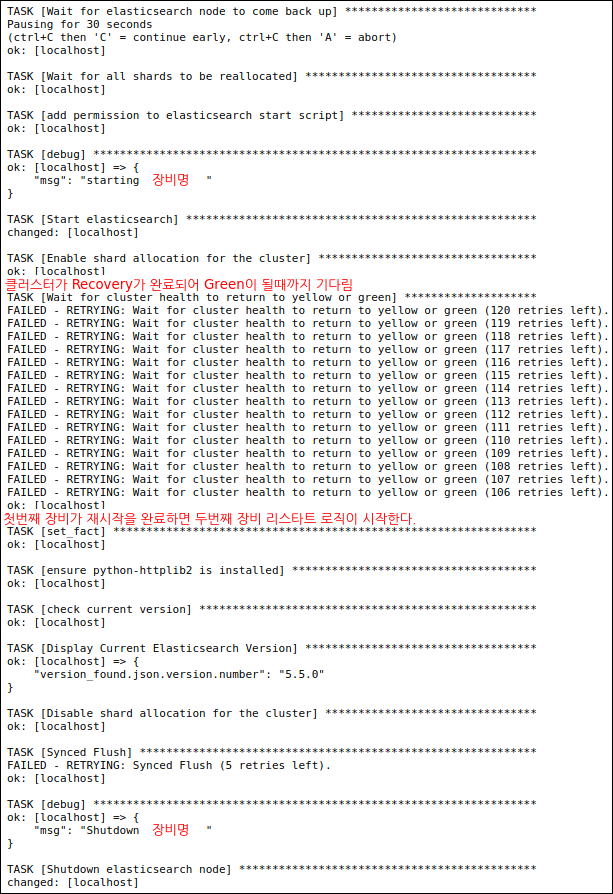
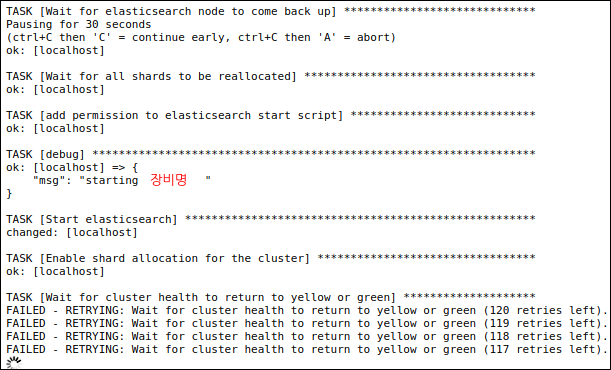
필자는 젠킨스를 활용하여 Ansible Job을 실행시키는 것으로 구성하였다. 아래는 3대의 노드를 롤링 리스타트 하는 과정의 일부 스냅샷인데 3대를 각각 롤링하여 재시작하는 과정이다.
장비 1대씩 내렸다 올려서 클러스터가 Green(노드 복구 완료)가 되는것을 기다린 다음 다음 장비를 진행하는 형식으로 Ansible 스크립트가 정상동작 하는것을 확인 할 수 있다.