Slide
SlideShare에 올려놓은 슬라이드 버전은 아래와 같습니다.
Content
- Plain Backpropogation (BP)
- Gradient Descent for MLP
- BP with Momentum
Recall: Supervised Learning
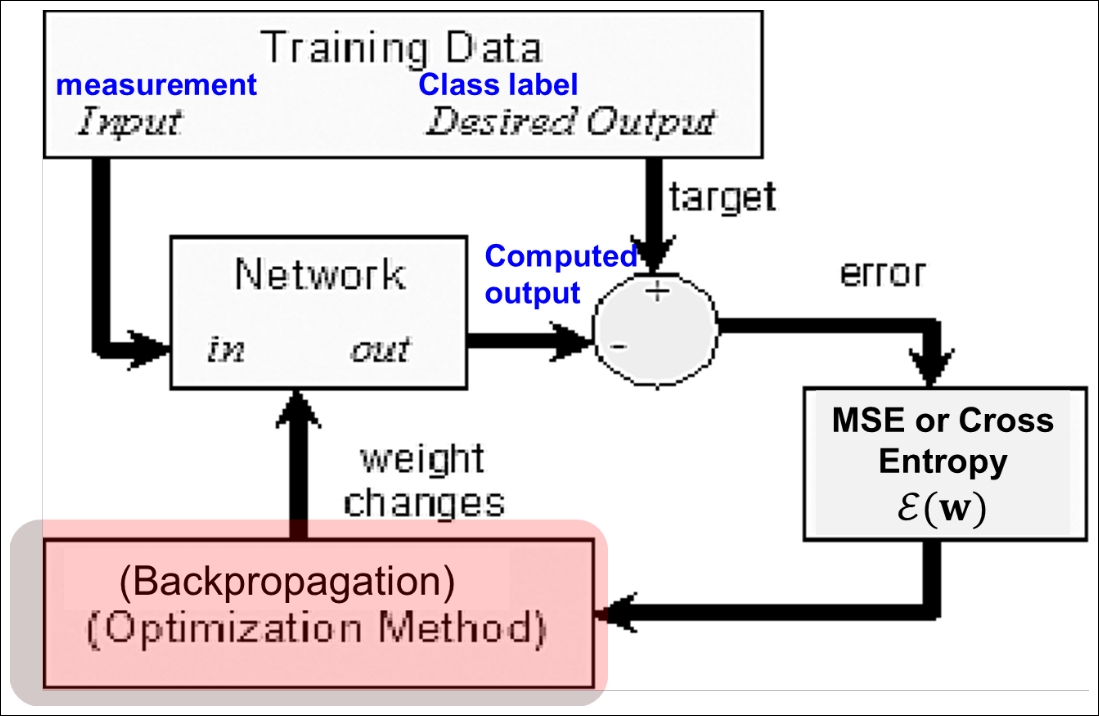
Recall: Error Function
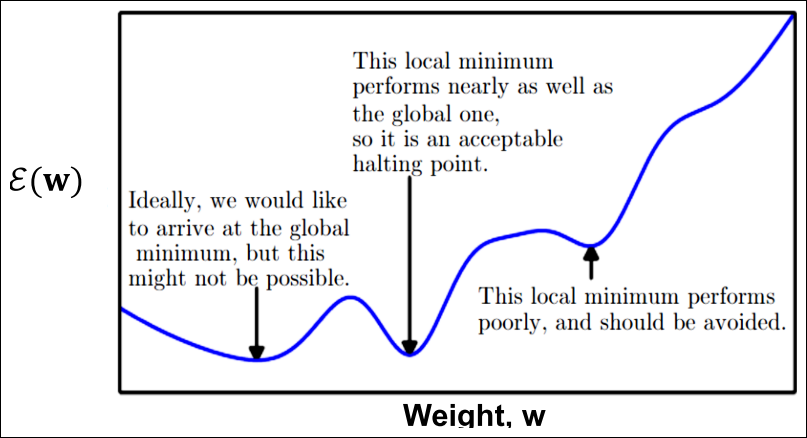
- Error function epsilon(w)는 못생김
- 매우 높은 차원
- non-linear
- global minima는 도달 불가능할 수 있음
- local minima는 bad or good
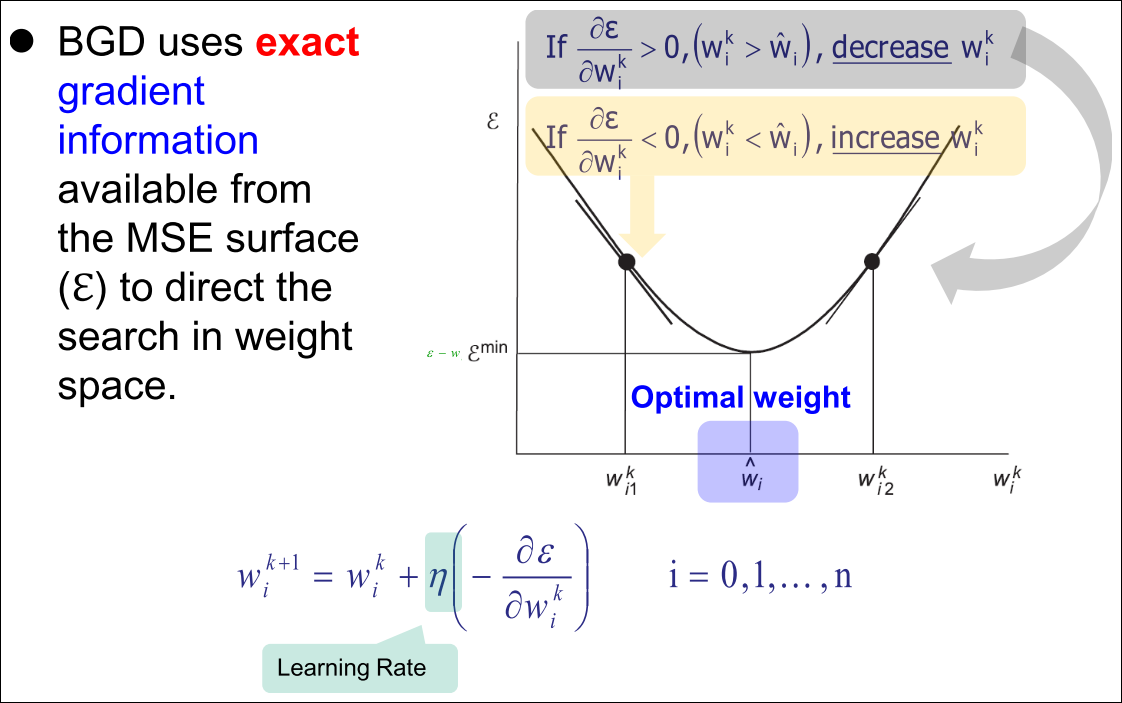
Recall: Gradient Descent
Backpropagation
-
Q개의 데이터셋이 존재함
-
Forward Pass
-
Error Computation : 출력 뉴런의 에러를 계산
-
compute Weight Changes : 출력 레이어부터 역순으로 가중치 업데이트
-
네트워크의 모든 가중치 업데이트
-
1~5를 global error function이 원하는 임계치에 도달할때까지 반복
Backpropogation: Illustration
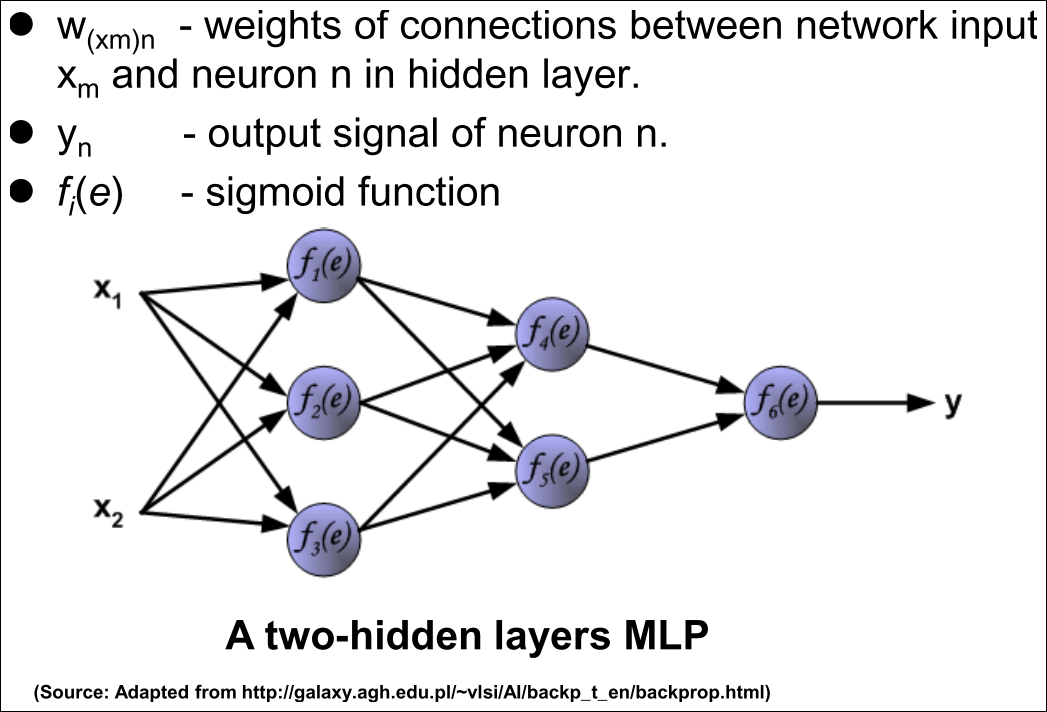
Forward pass: Input Layer
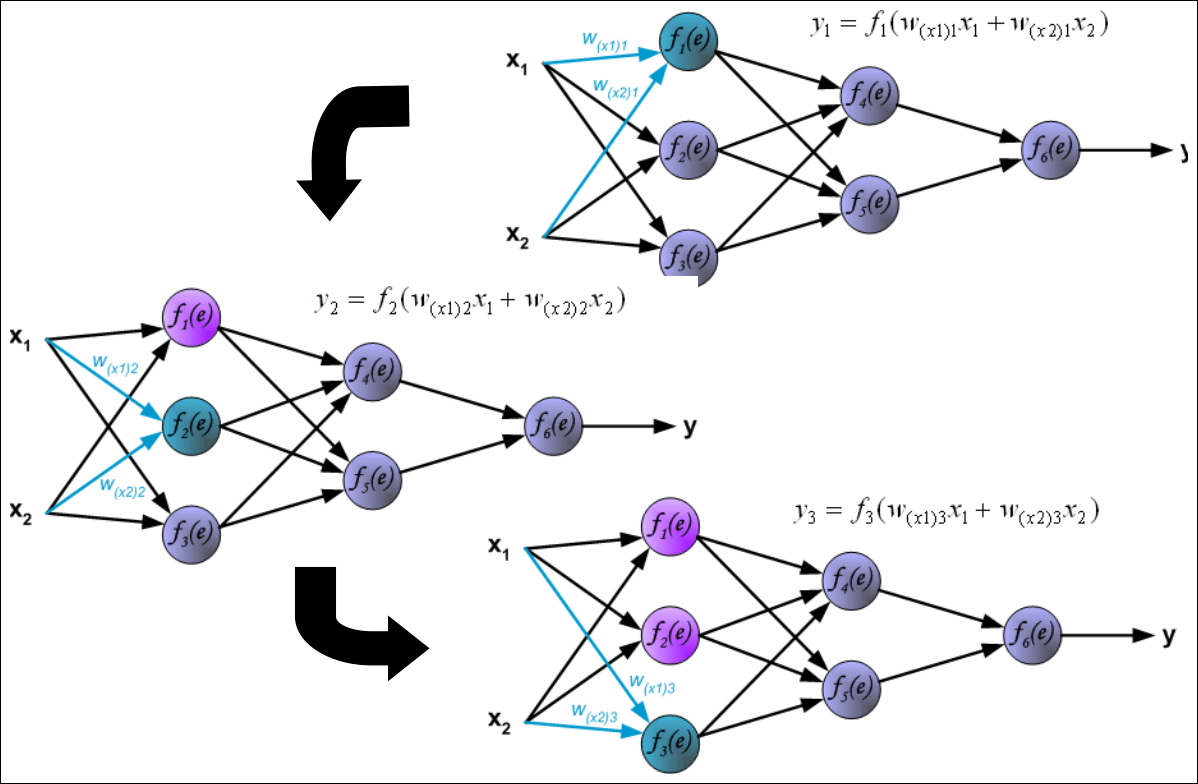
Forward pass: Hidden Layer
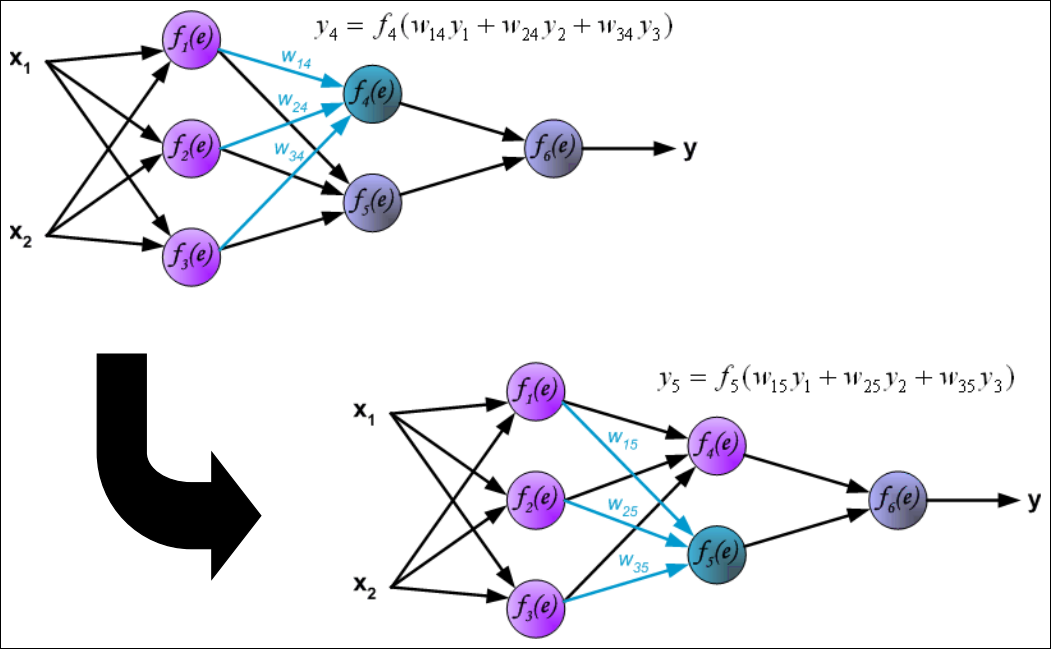
Forward pass: Output Layer
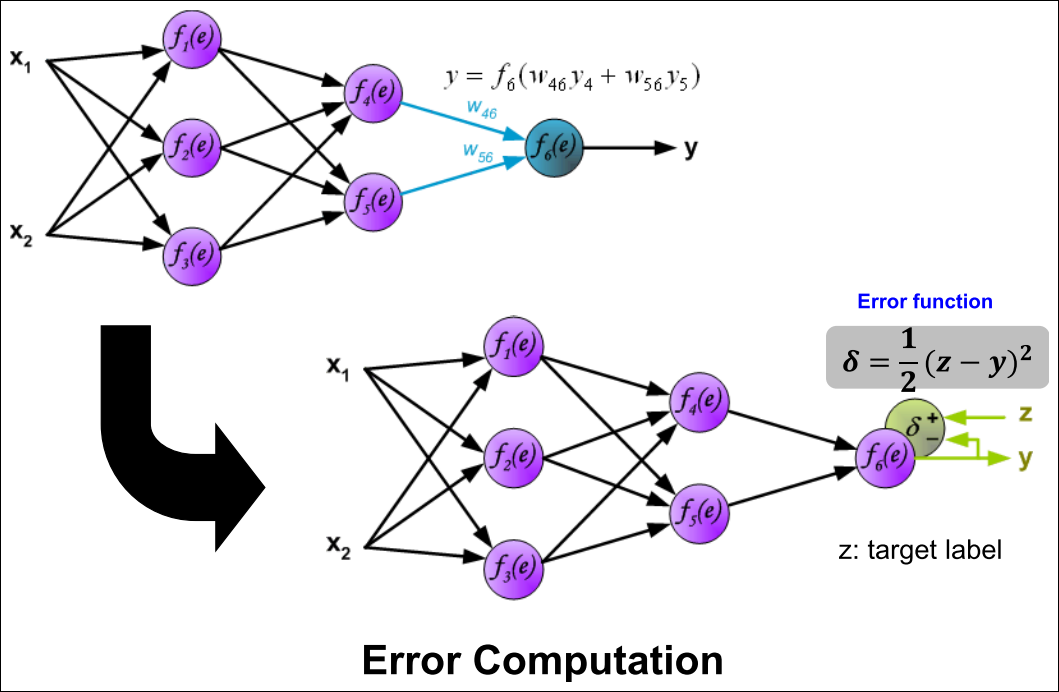
Backward pass : Output Layer
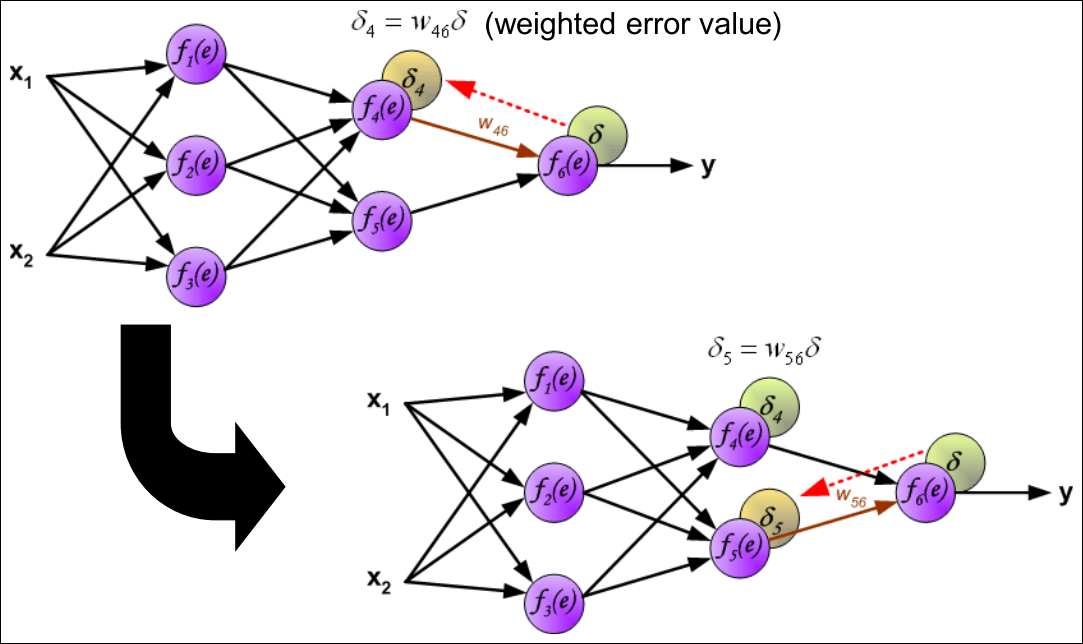
Backward pass : Hidden Layer
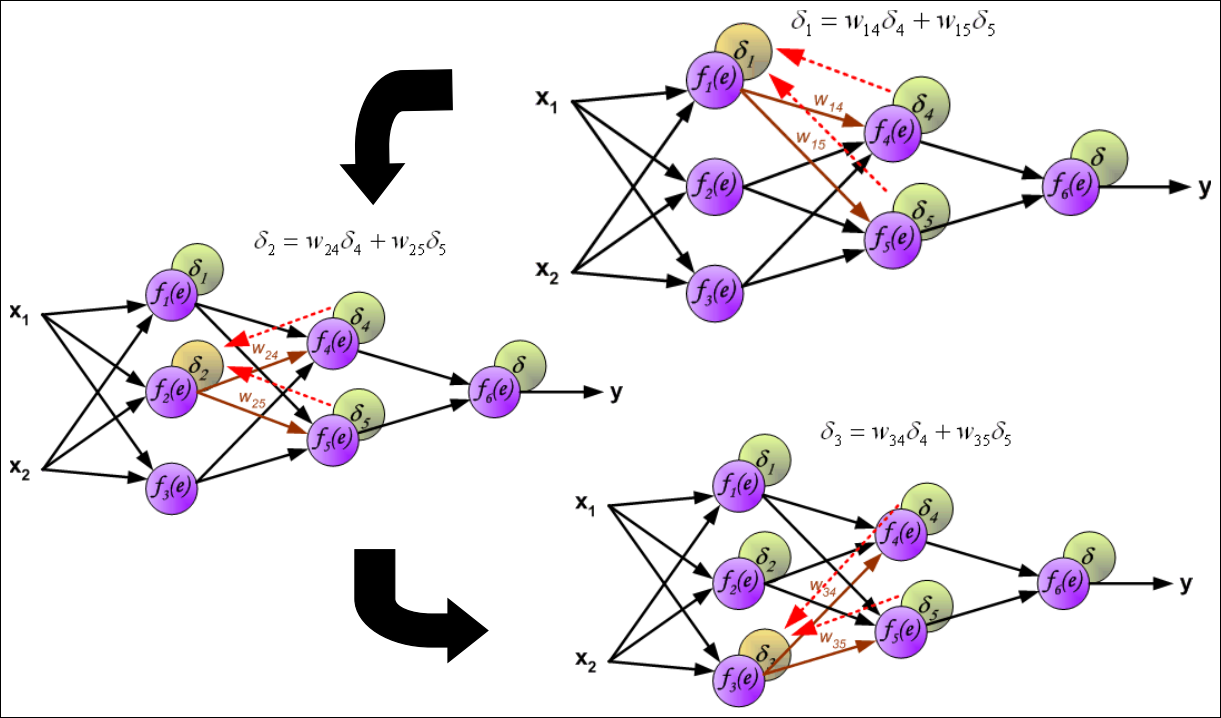
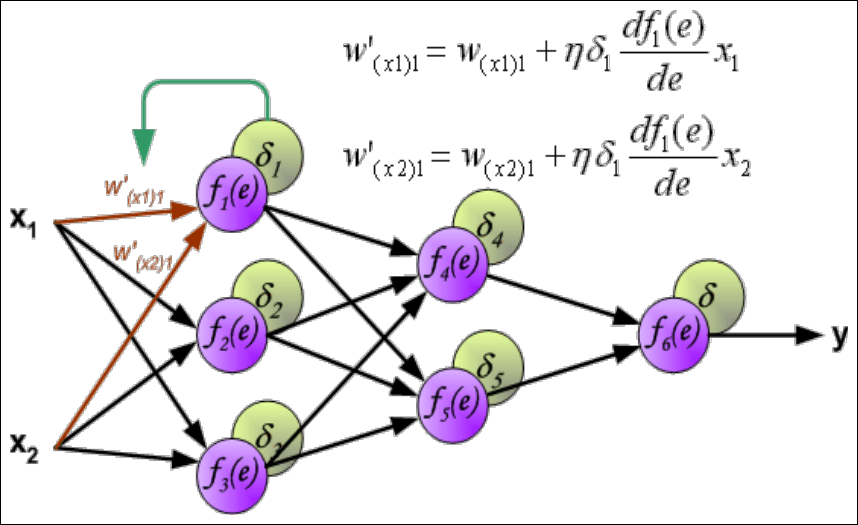
Weights Updating (1/3)
Weights Updating (2/3)
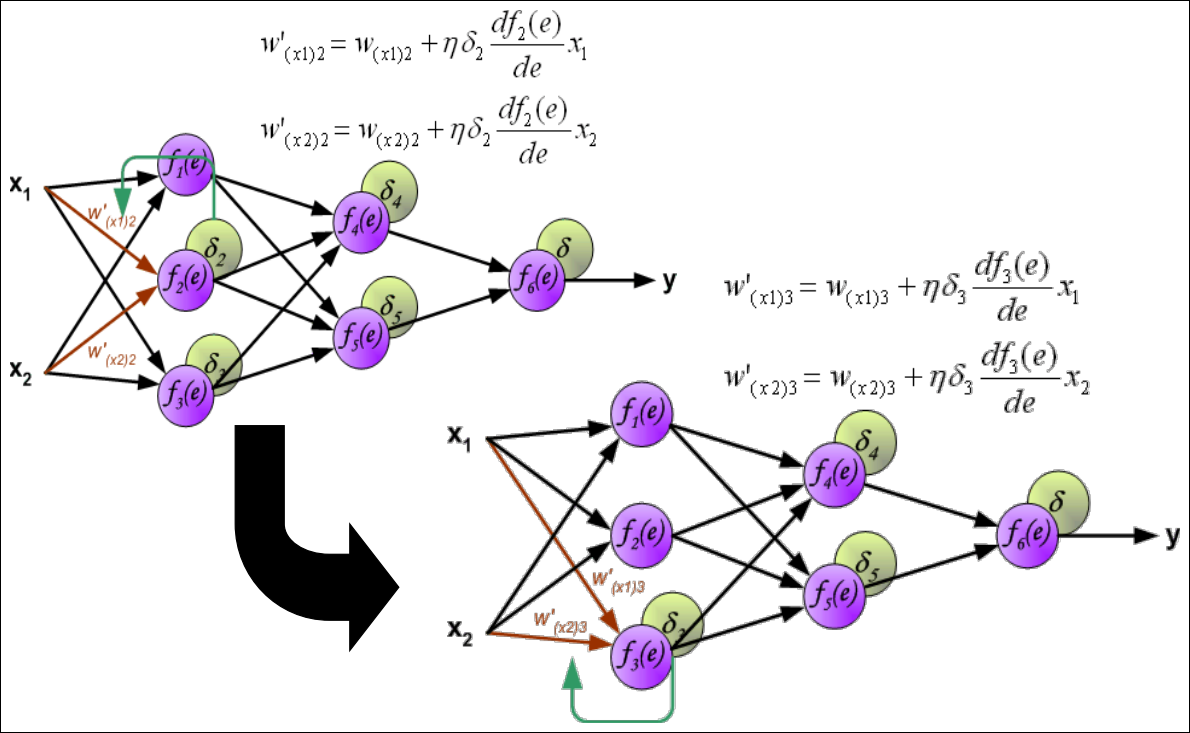
Weights Updating (3/3)
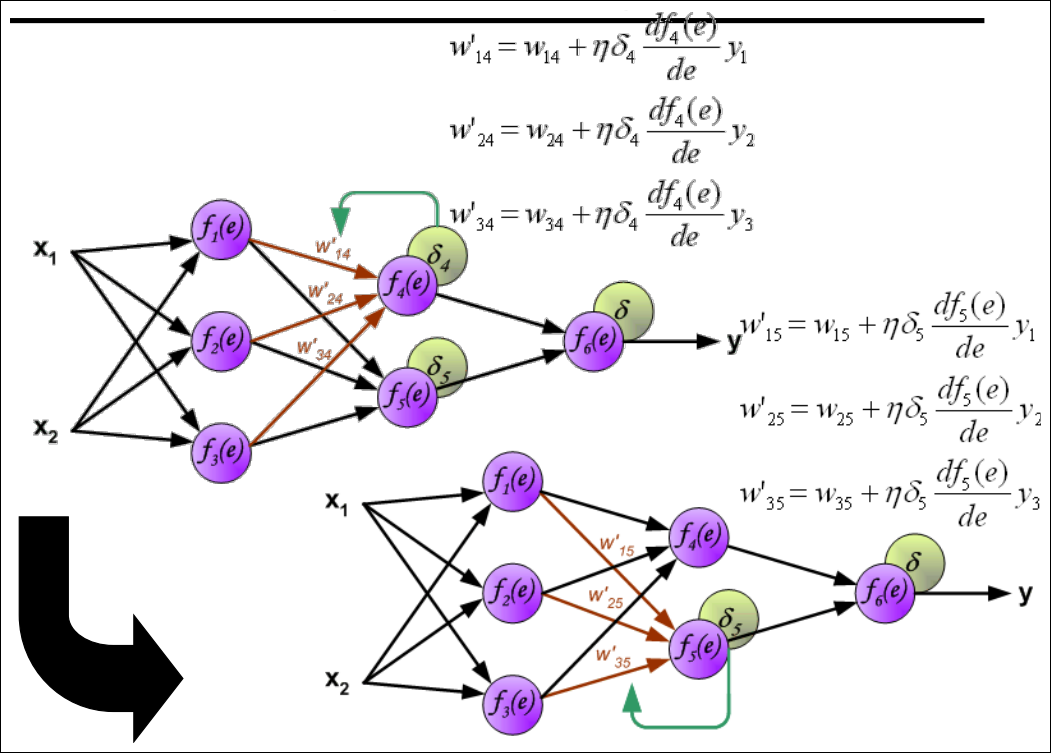
Finally … Done
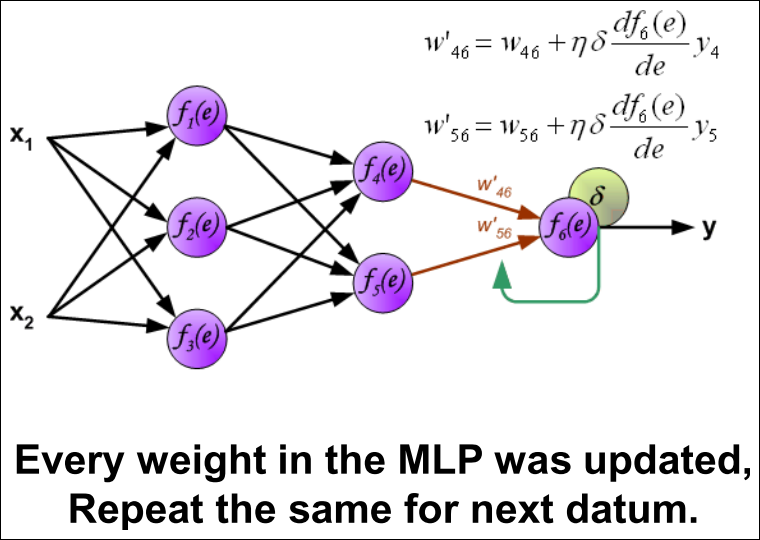
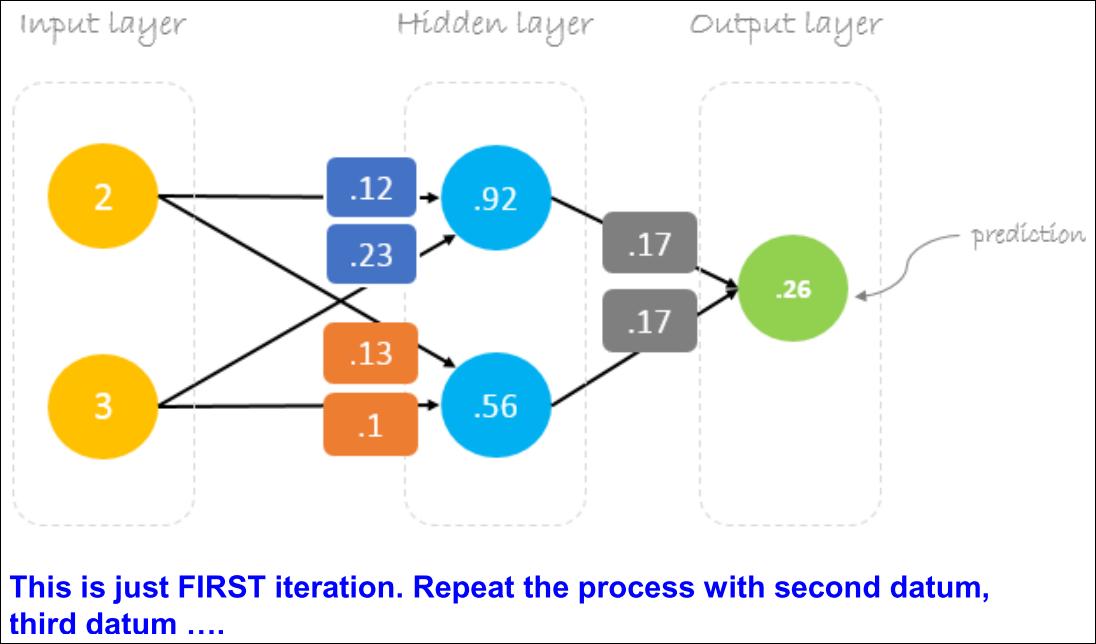
Iteration

A Numerical Example
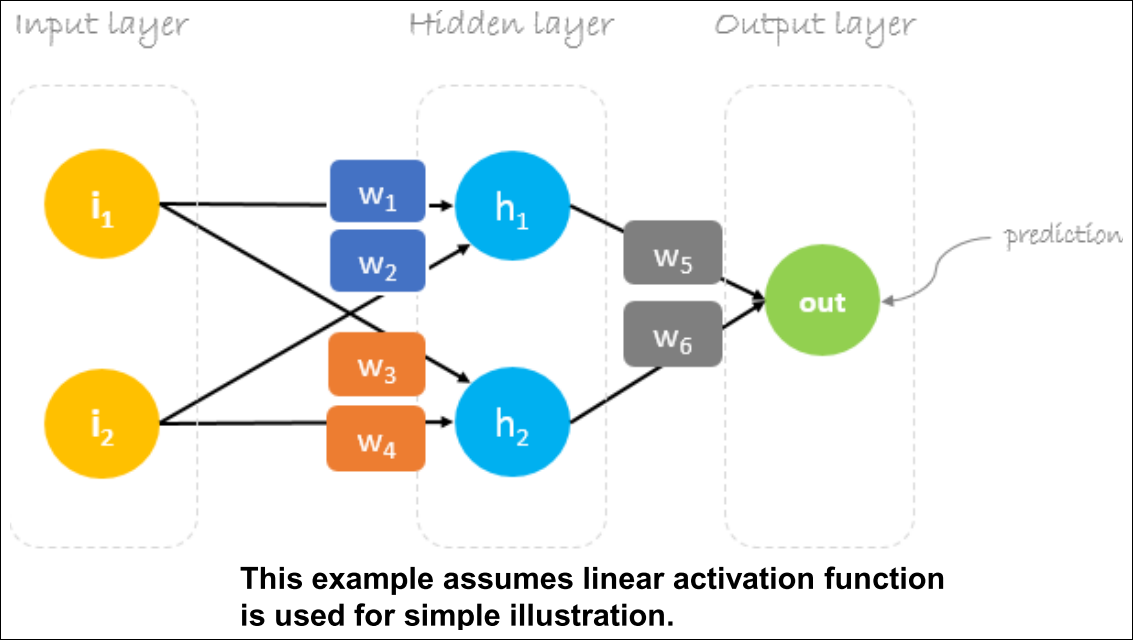
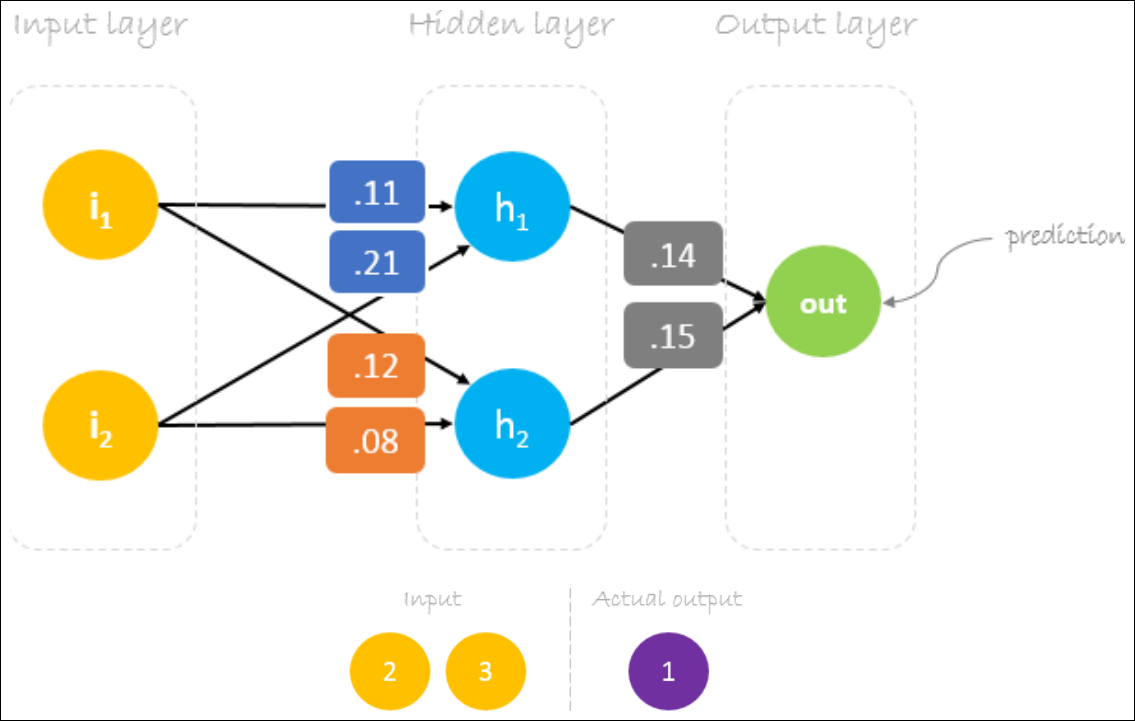
Weights Initialization
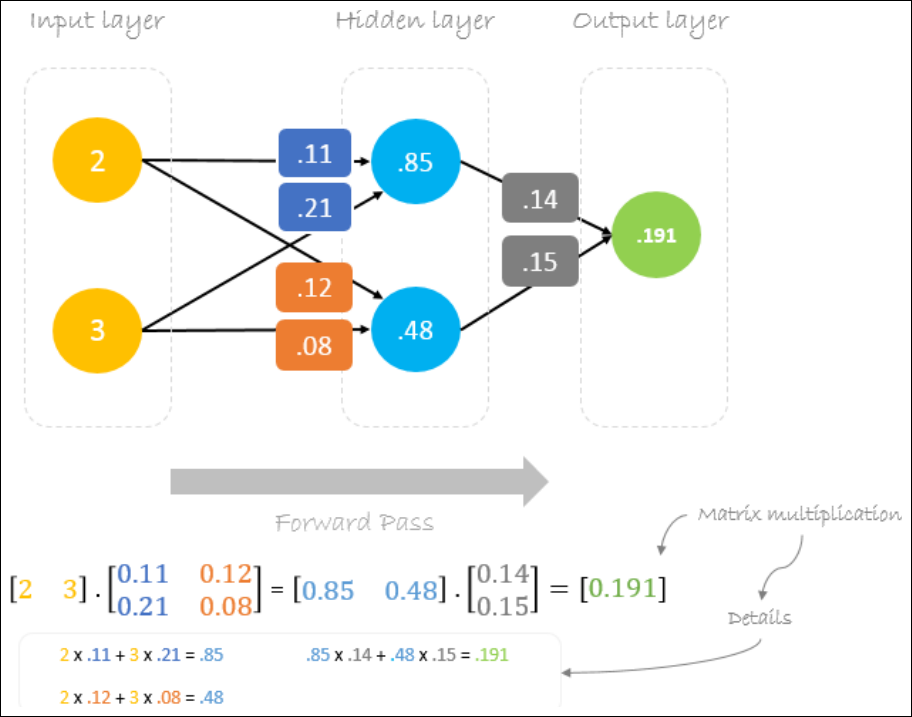
Error Computation

Weights Update
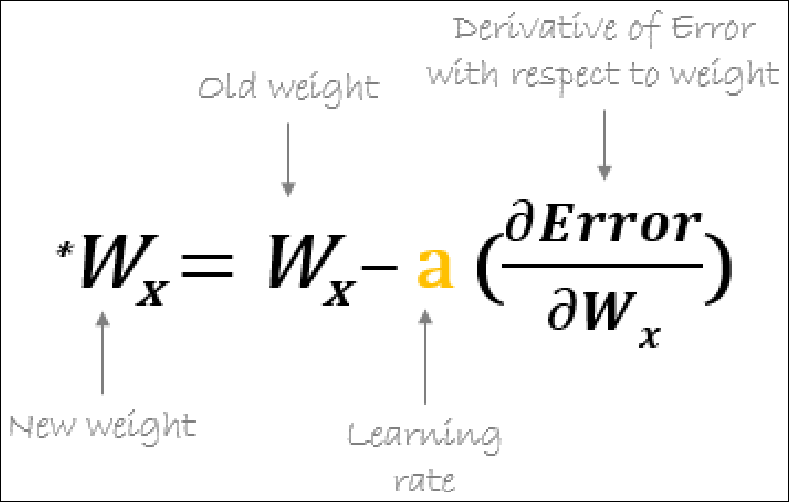
Gradient Error Computation (1/2)
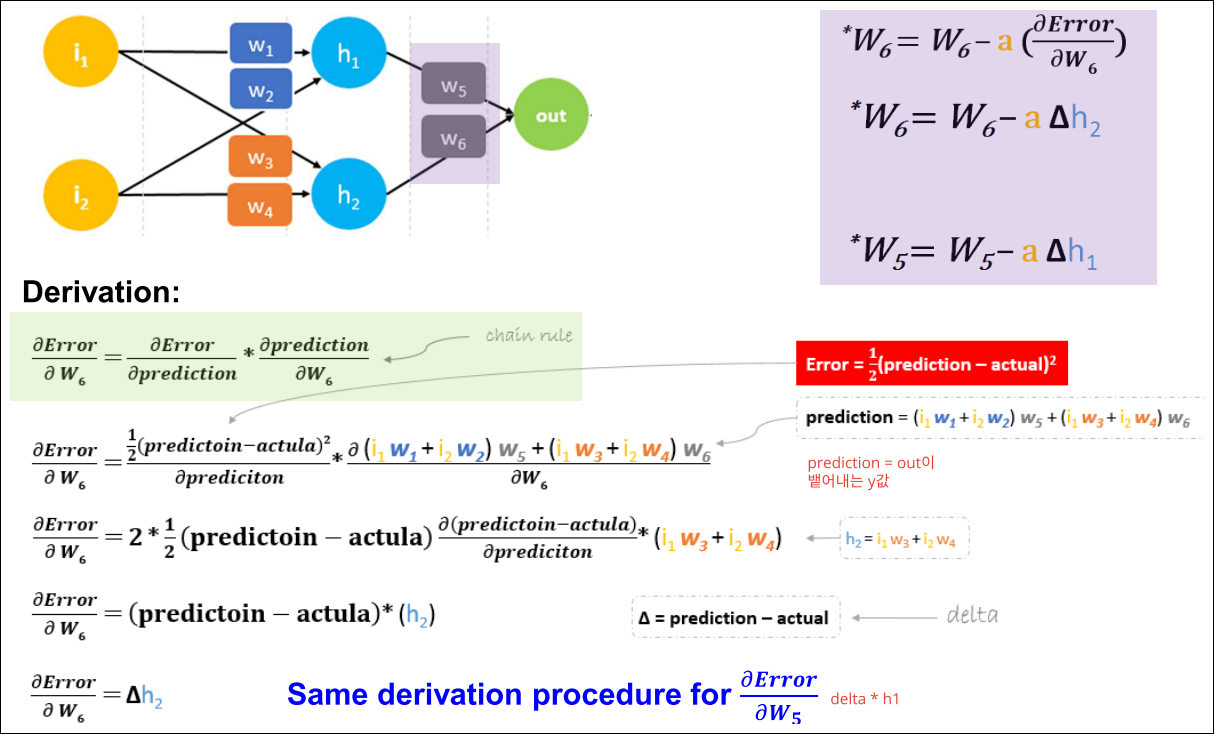
Gradient Error Computation (2/2)
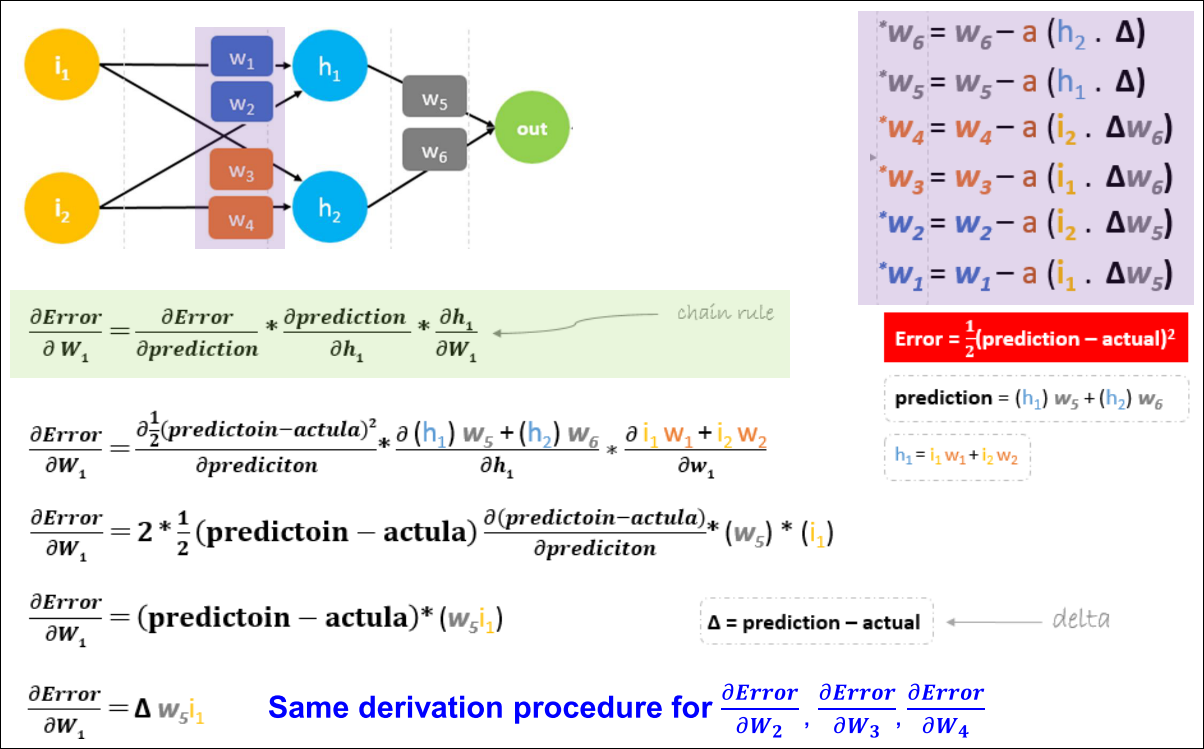
Weights Update (1/2)
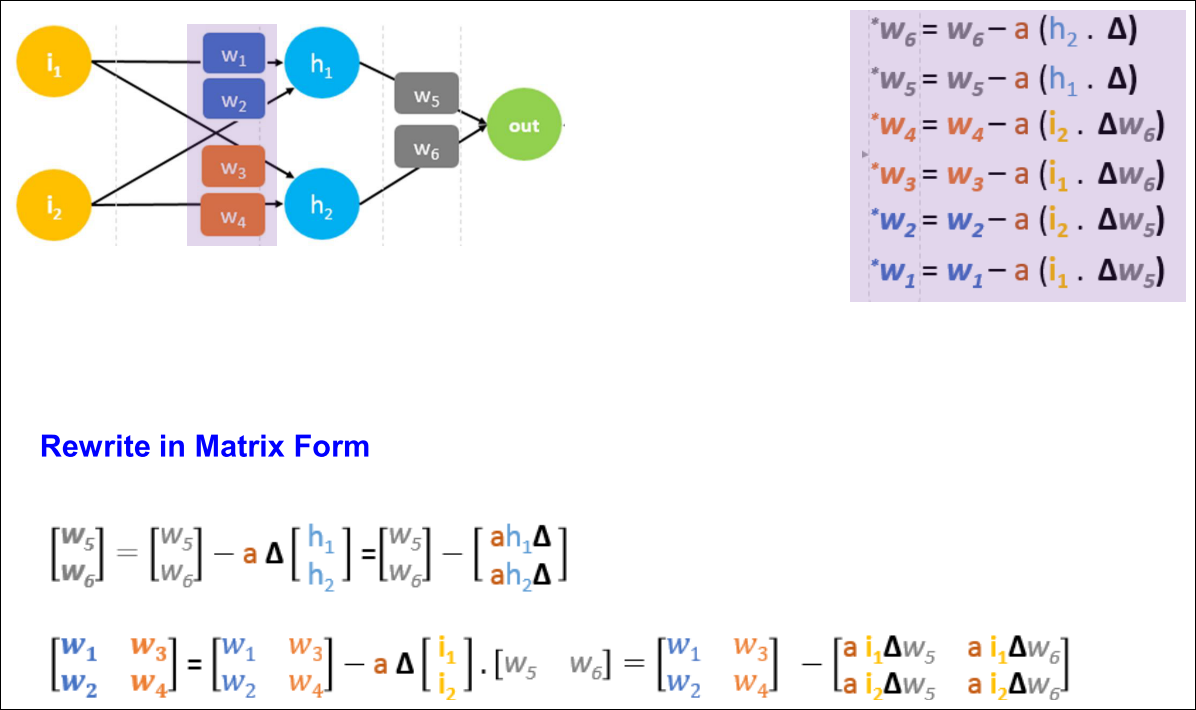
Weights Update (2/2)

All Weights Updated!
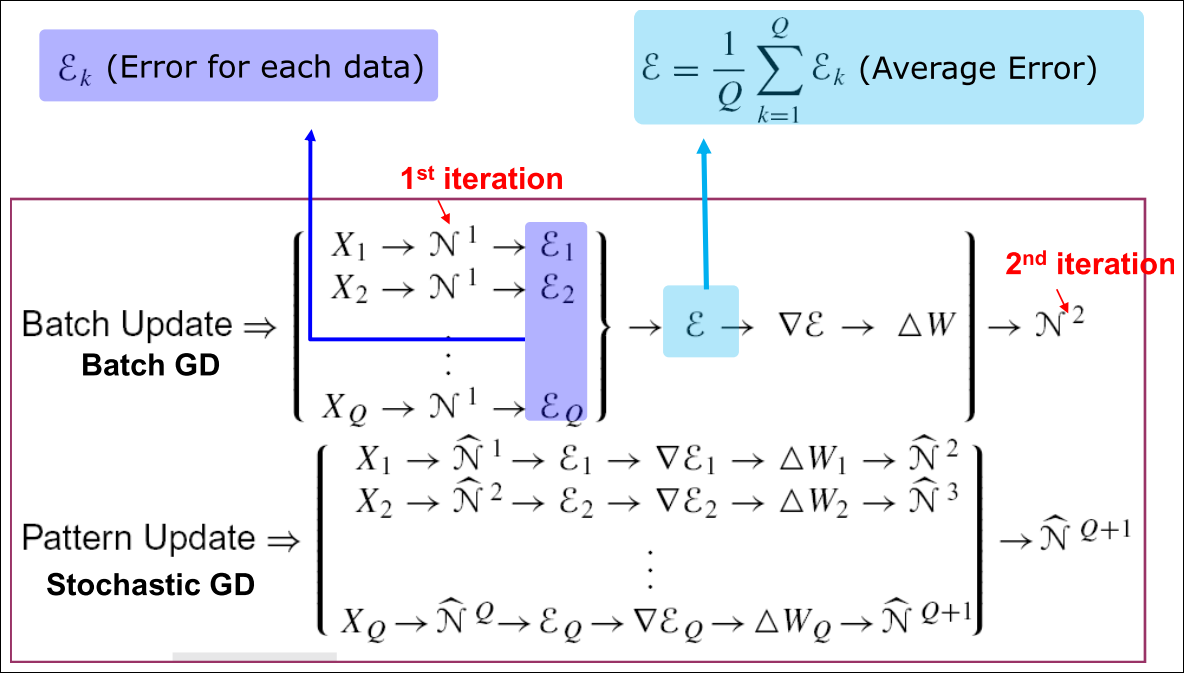
Batch, Stochastic and Mini Batch Mode Training
- Stochastic (Pattern) mode:
- 단일 패턴이 존재
- local error gradient 계산
- 네트워크 weight 변경

- Batch mode:
- global error gradient를 전체 epoch에 대해 수집
- 최초 네트워크 N0의 가중치를 한번에 업데이트
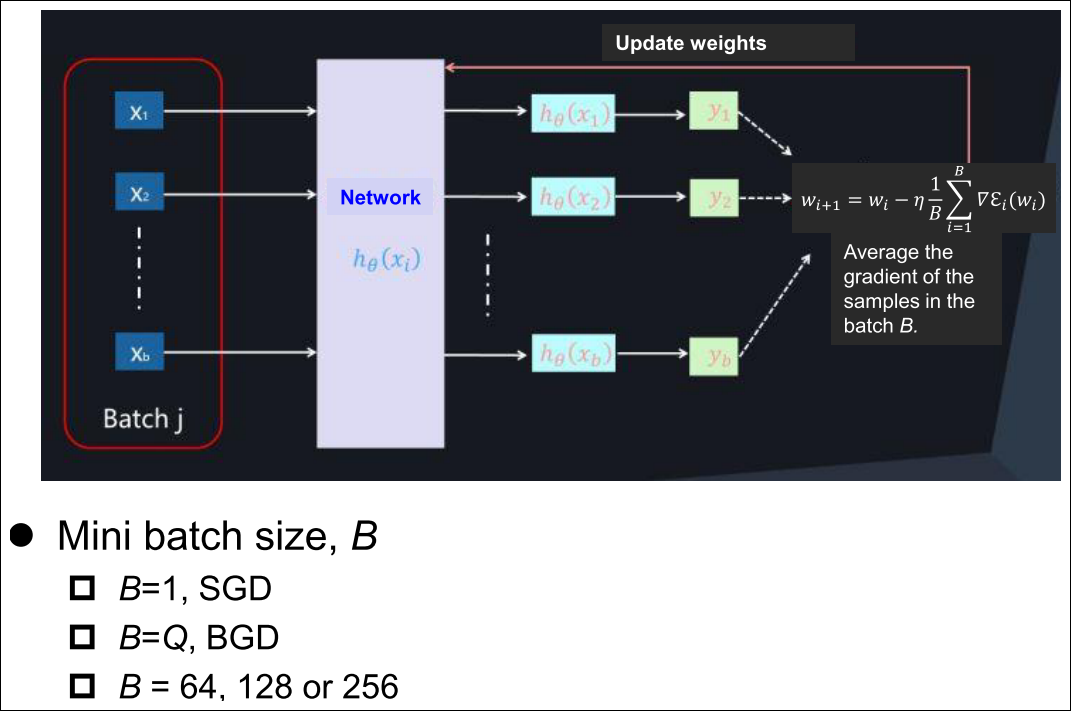
Batch, Stochastic and Mini Batch Mode Training
Batch, Stochastic and Mini Batch Mode Training
Next Lecture
- MLP의 이론과 알고리즘을 배웠다.
- 그러나 MLP를 이용하에 실전 문제에 어떻게 이용할까?
- 이 tool을 최적화하는데 응용할수 있는 trick이 무엇일까?