개요
data lake에 있어 어떤 기술로 ETL을 수행하는지는 편의성, 신뢰성, 성능 등과 관련이 있고 한번 정하면 다시 되돌리기 어렵기 때문에 신중한 선택이 필요한 영역이라 생각한다.
오버뷰 글에 이어 이번 시간에는 Glue와 관련되어 세운 아키텍처에 대해 알아보자. 쪽은 어떤 고민과 설계가 투영되었는지 알아보자.
기술 선정
스토리지
수많은 레퍼런스와 안정성을 가진 S3를 사용하기로 결정했고 실제 빅데이터 ETL에 필요한 데이터는 On-Prem으로 부터 CSV 형태로 통일해서 적재했다. 이는 아직 클라우드 쌓인 데이터가 없기 때문에 가능했다.
빅데이터 SQL 엔진
지금의 데이터 크기 및 앞으로의 확장성을 고려했을때 사실상 serverless presto 엔진인 athena 만으로 충분할꺼라 판단했다. MySQL Replication, Aurora 등의 대안이 있었으나 컬럼 기반 분산형 엔진에 Lake Formation 연동이 가능한 spec으로는 athena가 가장 적절했다고 생각했다. DB엔진은 종류별 장/단도 있겠지만 구축/운영하는 사람의 전문성이 중요한데 필자의 경우 presto를 오랫동안 쓴 경험이 있어 이게 주효했다.
Workflow 관리
이 글에서는 크게 다루지 않겠지만 batch job, event trigger 등의 목적으로 Airflow를 그것도 관리형인 MWAA로 도입했다.
적재 파일 포맷 및 테이블 포맷
적재 파일 포맷인 이제 거의 de facto로 자리 잡은 parquet를 자연스럽게 적용했고 추가로 iceberg 포맷을 적용하여 ACID를 비롯한 다양한 장점을 취하기 위해 적용하였다.
Glue ETL version
Glue ETL job은 크게 2가지의 모드를 지닌다. python shell 모드와 glue etl 모드인데 둘다 가장 최신 버전으로 적용하였다.
ETL Framework
Glue Crawler, Studio 등 다양한 선택지가 있지만 개인적으로 programatically ETL을 다루는게 가장 합리적인 방향이라 생각하기 때문에 glue script로 직접 ETL 하는 방식을 취했다. 다만, Framework를 제공하여 직접 개발하는 어려움을 최대한 보완하려고 했다.
최종 구성도
정리하자면 기본적으로 S3에 있는 CSV 파일을 Athena로 2가지 종류의 방법으로 ETL하는 것이다. 이 때 Workflow는 MWAA로 관리하게 된다.
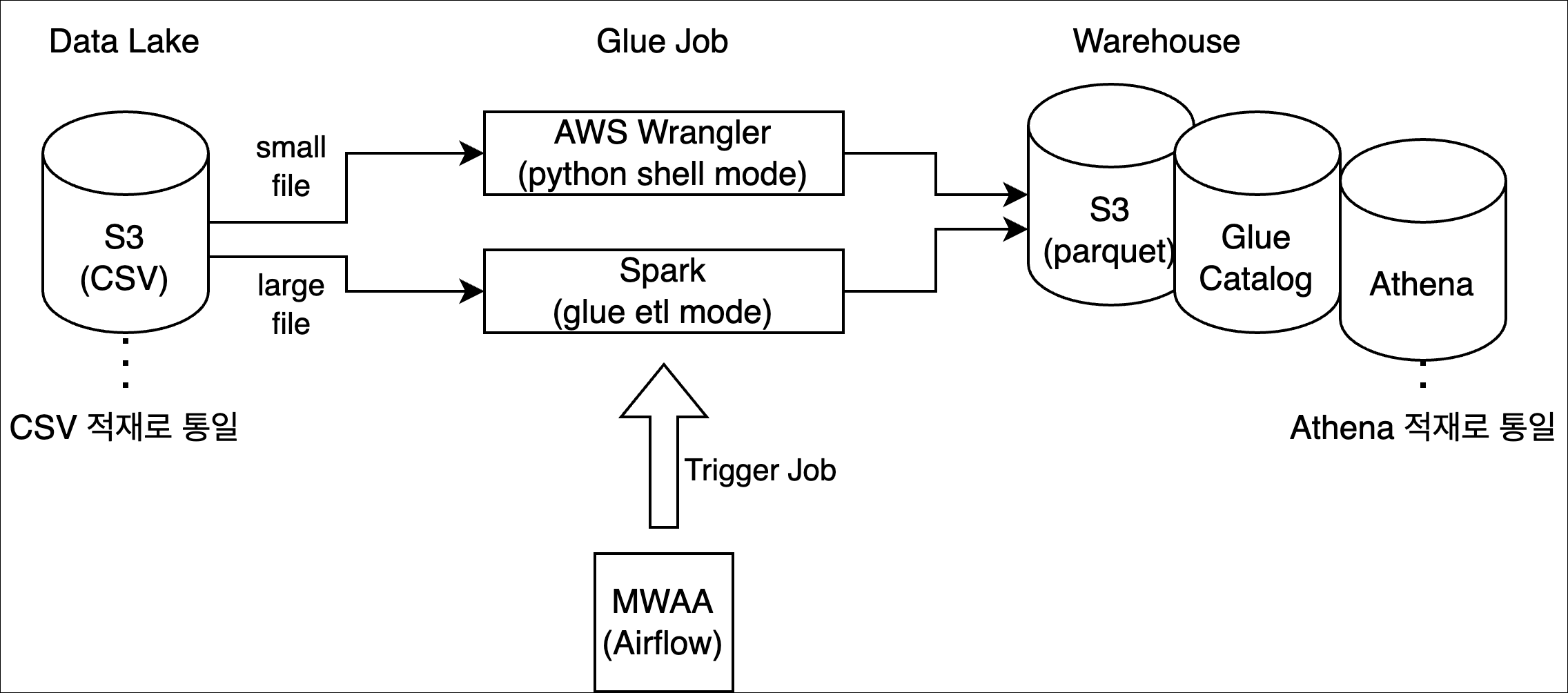
기술 특징점
왜 Wrangle와 Spark를 동시에 쓰나
기본적으로 이런 비교표를 작성하였다.
| 카테고리 | AWS Wrangler | Spark |
|---|---|---|
| ETL 엔진 | pandas | spark |
| ETL 용량 | 소용량, single machine 처리에 적합 | 대용량, 분산 처리에 적합 |
| DPU Capacity | 1/16 ~ 1 DPU | 2+ DPU |
| bootstrap | 거의 없음 | 오래 걸림 |
| 데이터 사이언티스트 친숙도 | 높음 | 비교적 어려움 |
| 분산 처리 용이성 | 없음 | RDD로 분산에 특화된 구조 |
그러나 결정적인 것은 대략 4GB 정도의 CSV 파일의 경우 AWS Wrangler를 사용한 방식이 Spark 대비 7.5배 정도 ETL 속도가 더 빨랐다.
이때 Wrangler는 1 DPU를 사용하고 Spark는 2 DPU를 썼으니 실제 비용차이는 약 15배가 발생하는 것을 알 수 있다.
모든 케이스를 다 측정해 본게 아니라 일반화 한것은 아니지만 사용한 DPU 수 * 수행시간 이 성능이자 비용으로 직결되는데 회사에 가진 데이터가 생각보다 4GB 미만 ETL 할일이 많아서 4GB 정도를 기준으로 Wrangler와 Spark로 이원화 하여 ETL이 진행되게 만들어 성능/비용 효율을 추구하였다.
지금은 데이터 크기에 따라 2 트랙으로 쓰긴 하지만 Glue On Ray 가 한국출시를 할것을 희망하며 선정해두었다. 이게 되면 ETL 측면이든 특히 전처리 측면이든 데이터 사이언티스트에게 보다 친숙하고 러닝 커브가 적은 Pandas를 활용할 수 있다는 큰 장점이 생길것을 기대한다.
인프라 측면 구성
data lake는 개발과 운영을 단 2개의 phase로 이원화 하였다. 실제 데이터는 On-Prem에서 넘어 온 뒤 beta에서는 1% sampling 하여 최대한 빨리 ETL이나 ML training 시 데이터 규격이나 최소의 데이터에서 오류가 나는것을 Fast Fail 할 수 있게 만들었다.
더불어 사용할수 있는 KMS 암호화는 모두 적용하였고 phase별로 KMS 키를 분리하여 보안 각 데이터가 isolation 되게 만들었다.

이후 CDK로 모듈화 하여 phase가 추가될 때 마다 최소한의 변수만 바꾸면 glue 관련 인프라가 1벌 생길수 있게 표준화 하였다.
import os
import sys
from aws_cdk import App
from aws_cdk import Environment
from aws_cdk import DefaultStackSynthesizer
from core.s3 import S3Stack
from core.kms import KMSStack
from core.dl_iam import IAMStack
from core.security_configuration import SecurityConfiguration
app = App()
cdk_environment = Environment(
account=app.node.try_get_context("ACCOUNT_ID"),
region=app.node.try_get_context("REGION")
)
dl_s3_kms = KMSStack(
app,
id=f'{app.node.try_get_context("DATALAKE_PHASE")}-s3-kms',
env=cdk_environment,
synthesizer=DefaultStackSynthesizer(file_assets_bucket_name=app.node.try_get_context("file_assets_bucket_name"))
)
dl_s3 = S3Stack(
app,
id=f'sli-dst-{app.node.try_get_context("DATALAKE_PHASE")}',
key=dl_s3_kms.key,
env=cdk_environment,
synthesizer=DefaultStackSynthesizer(file_assets_bucket_name=app.node.try_get_context("file_assets_bucket_name"))
)
glue_cw_kms = KMSStack(
app,
id=f'{app.node.try_get_context("DATALAKE_PHASE")}-cloudwatch-kms',
env=cdk_environment,
synthesizer=DefaultStackSynthesizer(file_assets_bucket_name=app.node.try_get_context("file_assets_bucket_name"))
)
security_conf = SecurityConfiguration(
app,
id=f'{app.node.try_get_context("DATALAKE_PHASE")}-securityconfiguration',
cloudwatch_kms_key_arn=glue_cw_kms.key.key_arn,
gluecatalog_kms_key_arn=dl_s3_kms.key.key_arn,
env=cdk_environment,
synthesizer=DefaultStackSynthesizer(file_assets_bucket_name=app.node.try_get_context("file_assets_bucket_name"))
)
iam = IAMStack(
app,
id=f'{app.node.try_get_context("DATALAKE_PHASE")}-developer-role',
env=cdk_environment,
synthesizer=DefaultStackSynthesizer(file_assets_bucket_name=app.node.try_get_context("file_assets_bucket_name"))
)
app.synth()
Framework의 개발
Enterprise 환경으로 Glue ETL을 써본 사람들은 알겠지만 생각보다 Glue Job 하나를 만들기 위해 설정한 값들이 너무나 많다. Security Conf, script 위치 등등 정할게 많다.
또한 CSV를 Athena 테이블로 ETL 하는 과정에서 각 테이블의 스키마 정보 외에는 코드가 거의 정형화 되어 있는 경우가 많다. (적어도 이번에는 그랬다.)
따라서 Framework를 만들어 실제 ETL 하는 사람들은 극단적으로 심플하면서 직관적으로 ETL 코드를 수행할 수 있게 만들었다.
예를 들어 아래의 예제 코드를 보자.
import os
from wrangler_helper import WranglerHelper
wh = WranglerHelper(os.path.basename(__file__))
args = wh.get_arguments()
table_name, year, month = args['table_name'], args['year'], args['month']
wh.from_csv_to_glue_catalog(
csv_path=wh.get_monthly_csv_path(year, month, table_name),
to_table_name=table_name,
is_dir=True)
코드에서는 파라미터를 가지고 온 뒤 이를 통해 csv에 있는 데이터를 athena로 iceberg type으로 etl을 수행 한 뒤 glue catalog에 등록한다. 이 때 AWS Wrangler를 활용한다.
(Airflow에서 Glue를 호출 할 떄 필요 시 파라미터를 전달한다.)
이때 위 코드는 아래의 사항들을 내포한다.
Naming Convention 처리
glue job file명 으로부터 s3 csv 위치, glue catalog 등록 db 및 table명, phase 등을 모두 알 수 있다.
이는 data lake를 구축하며 on-prem에만 있던 데이터를 클라우드에 옮기는 위치 및 규격을 고정하고 athena table로 만드는 규칙성 또한 만들었기에 가능한 부분이었다.
부가적으로 Framework에서는 naming convention으로 버킷명, security conf 등도 모두 파악하여 자동 설정한다.
테이블 스키마 자동 로드
table/column info를 규격화 하여 s3 특정 위치에 업로드 한 뒤 Framework에서는 ETL하기를 원하는 csv, 테이블명을 입력하면 info에서 찾아서 자동으로 csv의 데이터 타입, athena target 데이터 타입을 채워넣는다.
csv는 inference 기본 있지만 일부 숫자값들이 잘못 inference 되는 케이스가 있어 이부분은 명시적으로 관리하였다. 예를 들어 0000123의 경우 숫자가 아닌 string으로 유지해야 padding을 유지할 수 있었다.
파일명 기반 Job 생성
Glue Job이름도 마찬가지로 filename과 동일하게 맞추어 유지보수/개발 할 떄 직관적으로 job을 찾을 수 있게 하였다.
Iceberg 지원
Iceberg를 도입한 가장 큰 이유는 크게 3가지다. 자동 partitioning 기능과 ACID 연산지원, optimize 이다.
partition을 명시해야 하는 ETL 구조에서는 partition 변화가 일어날때 사실상 테이블을 새로 만들어서 옮겨 쓰거나 아니면 alias trick 같은걸로 같은 이름의 사실상 새 테이블을 만들어 써야 한다.
이는 좀 더 운영해봐야 더 실질적은 pros & cons를 파악할 수 있을것 같긴 한데 manifest 구조에 기인한 설계 spec을 보았을때 나쁘지 않을것 같긴 하다.
ACID 연산이 지원됨에 따라 ETL 시에 더 다양한 요구사항에 손쉽게 대응할 수 있는것도 장점이고 더불어 증분 ETL이 가능하기 때문에 성능/비용 효율적으로 ETL이 가능해진 부분도 있다.
끝으로 optimize/vacumm 기능을 통해 새벽 시간대에 테이블을 정리 할 수있게 만들어 파티셔닝 진화나 unused manifiest 등을 정리할 수 있는 구조도 좋은것 같다.
Spark ETL
Spark 버전의 경우에도 AWS Wrangler와 거의 동일하게 API를 쓸 수 있게 만들어 실제 ETL를 진행하는 사람들의 직관적 이해 및 편의를 고려하였다.
import os
from glue_helper import GlueHelper
gh = GlueHelper(os.path.basename(__file__))
gh.from_csv_to_glue_catalog(csv_path='path',
to_db_name='sample',
to_table_name='movielens')
맺음말
지금까지 간단히 Glue와 관련된 Data Lake의 기술적 구성도 및 특징에 대해 알아보았다. Athena를 쓰는 이상 In Memory DB의 장점을 오롯이 누리긴 어렵지만 위 아키텍처로 테라바이트 단위 ETL까지는 충분히 가능할꺼라 생각한다.
또한 아직 오픈하지 않은 Glue On Ray로의 확장성을 고려했을때 앞으로 더 재밌어질것을 기대한다.
