1. 개요
약 2년간 구축한 금융권 데이터 레이크를 회고해 보고자 한다. 간단히 어떤 목표로 구성을 하였으며 어떤 기술적인 특징이 있는지 알아 본 뒤 얻은점과 아쉬운 점을 나열해보고자 한다.
2. 요구사항 및 현황
요구사항은 매우 심플 하다고 볼 수 있었다.
- 크게 보면 빅데이터 분석과 MLOPS 역할을 하는 클라우드 데이터 레이크 시스템이 필요
- 기술 선정은 자유
- 데이터 레이크 경험 인력은 전무
- 개인정보를 다룰 수 있는 금감원 인가 클라우드 중요 시스템으로 등록
3. 목표
위 요구사항을 바탕으로 아래의 목표를 설정 하였고 그 이유를 간단히 적어보겠다.
3.1. 수직적 통합
클라우드/Data Lake/빅데이터 분석/머신러닝 등의 장점을 확실히 취하기 위해서는 하나의 View로 각 요소들의 최적화 되는 동시에 유기적으로 연결이 되어야 한다고 판단했다. 특히 맨파워가 부족한 지금의 조직 구조에서는 더더욱 한 곳에서 기술적으로 완성하여 전사에 전파하는것이 실용적인 전략이라 생각했다.
테슬라가 하드웨어/스포트웨어를 통합하고 필요에 따라 FSD나 배터리 조차 직접 생산하듯이 Data Lake에서는 IAAS 형태로 On-Prem을 의미는건 전혀 의미가 없으며 인프라 스트럭처와 Framework가 유기적으로 구성되어야 된다고 생각했다. 실제로 이를 통해 후술할 여러 장점들을 취할 수 있었다.
3.2. 성능 확보
성능을 얘기하려면 Data Lake에서 필요한 성능의 정의가 무엇인지 부터 정해져야 하지 않을까 싶다. 여러 요소가 있겠지만 ETL 실시간성, 개별 ETL 속도, 빅테이블 쿼리 속도, ML training/inferencing TPS 정도가 아닐까 싶다. 클라우드에서는 성능이 곧 비용으로 직결되기 때문에 성능을 확보하면 FIN OPS는 자연스레 따라온다고 생각한다.
3.3. 운영 최소화 및 기술 난이도 경감
인력의 거의 전무한 상태에서 1인 스타트업 처럼 구축을 시작해야 했다. 일부 주니어들이 합류하기 시작했지만 여전히 운영에 필요한 경험치가 현저히 부족한 상황이었다. 따라서 운영성 업무를 애초에 최소화 시켜놓거나 AWS 서비스를 활용하여 위탁할 수 있는 형태를 고려하였다.
마찬가지 맥락에서 구축/운영의 Risk를 줄이기 위해서 구조를 단순화 하거나 Framework 코드를 제공하는 방식으로 기술 난이도를 낮추고자 노력했다. 예를 들자면 10년차 개발자가 이해하고 개발할 수 있는 수준을 5년차로, 5년차의 그것은 1~2년차가 소화 할 수 있게 의도했다.
3.4. 주니어 엔지니어 육성
데이터 엔지니어가 되고 싶으나 기회가 닿지 않았던 주니어 엔지니어들이 빅테크 방식으로 엔지니어들이 어떻게 일을 효율적으로 하는지를 일을 통해 성장 시키고자 했다.
4. 경과 요약
21년 9~12월 시스템 구축 → 22년 6월 비 중요 시스템 오픈 → 23년 4월 중요 시스템 오픈 → 데이터 적재 및 분석중
5. 구성환경
실제 구성은 아래 구성도를 설명한 링크와 매우 유사한 구조로 핵심이 되는 기능은 아래의 기술들로 구성된다.
- airflow
- athena
- sagemaker
- glue etl
- eks
- s3

6. 기술적 특징
6.1. AWS Built In Serverless Architecture
AWS Serverless의 핵심은 server (management) less 라고 생각한다. 이를 통해 크게 2가지 장점을 얻을 수 있는데 첫째, 항상 켜져있는 서버로 인해 수반되는 프로비저닝, 데몬 관리, disk 관리 등등의 업무로 부터 자유로워 진다는 점이고 둘째, 자원을 빌려 쓰는 클라우드의 특성 상 Idle 비용이 제거되어 비용이 최소화 된다는 점이다.
이번 기회에 데이터 레이크를 구축하며 serverless 기술을 최대한 도입하였다. EMR 대신에 Glue ETL과 Athena를 활용하였고 EKS는 Fargate worker를 일부 활용하고 Airflow는 serverless는 아니지만 MWAA를 통해 운영 비용을 최소화 하였다.
이중 Glue ETL은 Spark mode 뿐 아니라 Python Shell 모드를 적극 활용하여 Lambda 대신 AWS Wrangler SDK를 활용하여 가벼운 ETL이나 전처리 업무에 비용효율적으로 활용하였다.
6.2. Dev OPS
CDK를 사용하여 모든 인프라 생성을 코드로 작성하였다. VPC, MWAA, Sagemaker, S3등 모든 코드를 파이썬 CDK로 작성하였다. 장점은 유사한 리소스와 Policy가 에러없이 템플릿화 될 수 있고 인프라의 변화가 코드로 다 관리된다는 장점을 얻었다. 나아가 CF 대비 장점은 필요 시 programatically 하게 코드를 끼워넣을수 있기 때문에 개발자 입장에서 인프라를 구축/운영하는데 장점으로 느껴졌다.
또한 GitOPS를 지원하기 위해 code build, code pipeline을 조합하여 Airflow Dag나 Glue Job등이 코드리뷰 후 Code Commit에 push되면 자동으로 필요한 S3에 적재되어 Dag나 Job이 Sync되게 만들었다.
6.3. 최적화
최적화를 위해 Naming Convention부터 고민하였다. Airflow, Glue ETL 등의 Job 이름, 파일이름 등을 모두 정의할 수 있는 선택권 덕분에 S3/Airflow/Glue/Athena를 관통하는 Naming Convention을 정의하고 이를 통해 불필요하게 발생할 수 있는 코딩 양을 줄였다. (특히 하드코딩)
이 케이스도 수직적 통합 관점으로 불 수 있을것 같은데 유연성을 일부 제한하는 대신 통일성을 더 강조하였다. Naming Convention 에 Glue 카탈로그명, 개인정보 수준, ETL 유형 등을 기술하여 이름 만으로도 직관적으로 어떤 역할을 하는지 데이터가 어디서 어디로 흘러가는지를 알 수 있게 만들고자 노력했다.
이후 Airflow와 Glue를 위한 Framework를 만들었다.
Airflow 쪽은 필요에 따라 기존 Operator, Sensor를 수정한 커스텀 코드를 개발했고 Framework는 dag 파일명 만으로 dag 및 glue job으로 연결될수 있게 만들었다. 나아가 glue job dag가 호출되면 Glue Job이 Create or Update되게 동작한다.
Glue 쪽은 AWS Wrangler를 활용한 pandas 기반 Framework와 PySpark Framework로 이원화 하여 만들었으며 별도 s3에 올려둔 table definition csv로 부터 source csv 및 target csv의 이름, data type등을 알아내어 자동으로 Athena ETL이 동작하게 만들었다. 두 종류 모두 Table Format은 Iceberg로 통일하였다.
ETL Framework를 이원화 한 이유는 PySpark ETL은 대용량 데이터에서 좋은 성능을 발휘하지만 매우 작은 small csv file들 에서는 비효율적이라 관측 후 판단하였다. 이유는 serverless라고 하더라도 Spark Driver의 Bootstrap에 준비되는 warm up 시간이 존재하고 구조 자체가 S3에 있는 small file fragment를 분산형 엔진으로 돌리는것 보다 Single Machine에서 pandas로 빠르게 bootstraping 없이 ETL은 넣는게 시간이 적게 걸렸기 때무이다. 따라서 DPU 사용시간으로 계산되는 ETL 비용을 고려했을 때 대용량은 Glue, 소용량은 Wrangler를 이용하는 2 track 전략을 설정하였다. 참고로 ETL Framework가 다르다고 하더라도 결과물은 Iceberg format의 Athena로 적재되는 동일한 결과를 얻는다.
끝으로 Athena는 Iceberg Format을 도입함으로써 명시적으로 파티셔닝을 지정하는 전통적인 ETL 방식에서 벗어나 Dynamic Partitioning이 될 수 있게 바뀌었고 ACID 트렌젝션을 지원하기 때문에 ETL 자유도 및 증분 적재에서 분명한 장점이 생겼다. 끝으로 Postgres와 유사하게 vacumm, optimize 기능을 통해 manifest 방식의로 발생 할 수 있는 deprecated file/metadata를 daily로 정리하며 파티셔닝 변경, 일부 사전 집계의 업데이트가 일어날 수 있게 최적화 하였다.
6.4. 중요/비중요 시스템 직접 전환
22년에 비중요 시스템, 23년에 중요 시스템으로 주니어 엔지니어들과 의기투합하여 수행사 없이 직접 필요한 인프라를 구축하고 Paper Work을 진행하였다. 힘들긴 했지만 금융사에서 필요한 금감원의 조치 가이드를 파악하고 법적 신고까지 끝냈다는데 뿌듯함을 느낀다.
6.5. 보안
금융사에서는 보안 그중에서도 개인정보 취급에 보안 조치 만큼 중요한게 없다라고 해도 과언이 아닐 정도라고 생각한다. 직접 Data Lake를 구축하는 장점을 십분 활용하여 보안에는 각별히 신경을 썼다.
VPC 레벨에서는 Security Group, NACL을 CDK로 관리하여 항상 update가 되게 의도하였다.
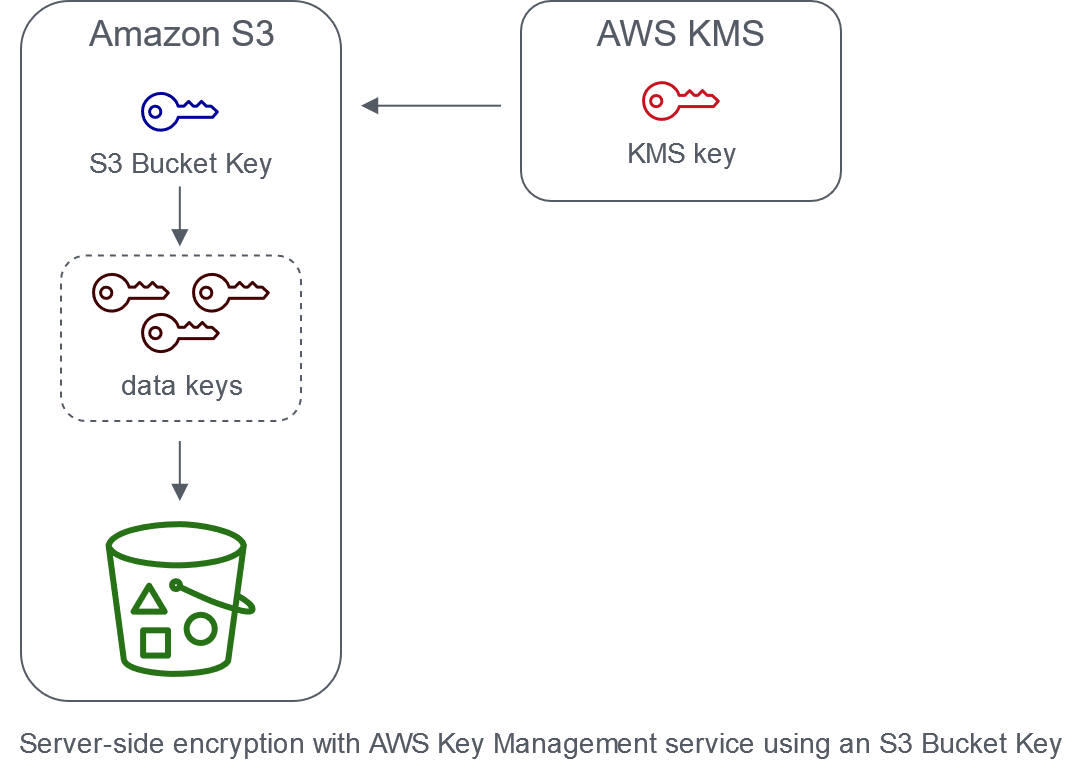
S3는 모두 버킷별로 KMS Key를 따로 만들었고 Bucket Key 방식으로 적용하였다. 버킷별로 키를 따로 만든 이유는 Worst Case로 생각했을때 탈취되는 데이터를 Isolation 하기 위함이었다. 또한 이는 On-Prem과 달리 데이터 센터 파기/출구 전략을 논할때 모든 장비를 파기하고 빠져나가는것이 물리적으로 거의 불가능한 클라우드 환경에서 KMS Key만 지워버리는 것으로 데이터 복호화를 불가능케해 간접적으로 데이터를 파기하는 효과를 만들어 낼 수 있다.
Glue는 개발 phase(예: dev/qa/prod와 같은 구분) 별로 Security Conf를 구성하여 필요한 만큼의 버킷, KMS 권한을 가지게 만들었다.
Sagemaker는 private vpc mode로 구축하여 serverless 영역의 operation도 모두 직접 생성한 vpc 내 network로 간주되어 flow log 추적, public 망과의 분리를 구현하였다.
Athena는 parquet가 저장된 S3를 포함하여 Lake Formation을 적용하였고 개략적으로 설명하자면 개인정보 수준에 맞게 등급을 나눠 필요한 만큼만 필요한 Role을 가진사람이 필요한 데이터에 접근할 수 있게 만들었다.
끝으로 중요시스템 및 금융권의 보안을 챙기기 위해 Security Hub를 활성화 하고 미국 위주긴 하지만 필요한 Guide Line들을 최대한 다 활성화 하여 보안 이슈들을 발견한 뒤 해결하고 Resolve 하는 식으로 보안을 강화 하였다.
7. Data Lake 구축으로 얻은점
SAS만 쓰는 회사에서 보안 허용 범위 내에서 Github, Pypi가 사용 가능한 Sagemaker를 얻었고 Athena 쿼리 분석 및 필요할때 Sagemaker EFS로 데이터를 dump떠서 학습할 수 있게 되었다.
나아가 인프라 스트럭처든 Framework든 표준화, 최적화가 되어 있어 유사한 인프라 리팩토링 및 기능 추가에 등을 안전하면서도 빠르게 진행할 수 있게 되었다. 보안까지 항상 준수하면서 말이다.
또한 Data Lake 구축 운영에 필요한 커뮤니케이션, AWS 사용료, 구축/운영 비용 모두 수행사를 통하는것 대비해서는 효율적으로 진행되었다고 생각한다.
끝으로 직접 엔지니어들을 성장 시키며 Product를 만들었기 때문에 기술도 중요하지만 같이 성장하고 나아가며 우리만의 개발 문화와 구체적인 결과로 얻었다는 점에서 보람을 느낀다.
