개요
Ada Boost에 대해 알아 본 뒤 정리해둔다.
컨셉
strong model vs weak model
- weak 모델은 랜덤 추측보다 조금 더 잘하는것
- weak 모델은 strong model 까지 부스팅 될 수 있음
boosting 컨셉
ㄱ,ㄴ,ㄷ,ㄹ,ㅁ 가 모델이고 B alpha, beta, …이 데이터라 가정하자.
이걸 더 단순화 해서 공부에 대입하면 ㄱ~ㅁ 의 사람이 B alpha 등등의 문제지를 푼다고 가정하자.
ㄱ보고 B alpha플 풀게 해보니 과학은 잘 맞추면 그건 넘어가고 잘 못하는 예술 역사 문제들로 집중해서 다음 ㄴ에게 풀게 만든다.
왜냐면 과학은 ㄱ이 이미 잘 풀기 때문이다.
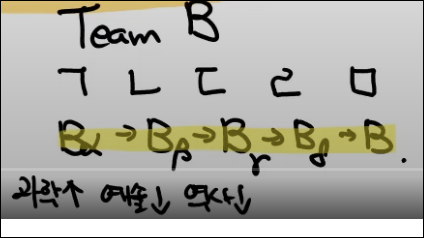
Ada Boost 학습 진행 방법
- 학습데이터셋 준비
- get some rule of thumb(weak model)
- 앞선 모형이 잘 풀지 못하는 문제에 한해 학습데이터셋에 대한 가중치를 다시 결정
- 다시 새로운 rule of thumb을 유도해냄
- … 반복하면
- 지금 까지 찾아낸 규칙을 조합해 하나의 합쳐진 strong model을 만듦
idea
- 모델 트레이닝을 순차적으로 진행함(한턴에 하나의 모델을 학습)
- 오분류된 example을 찾아다가 새로운 트레이닝 셋에 대해서는 더 많이 나올수 있게 가중치를 조절
- 앞선 모델의 큰 에러는 다음 모델에서 데이터를 더 많이 학습하게 되어 줄어들게 만듦
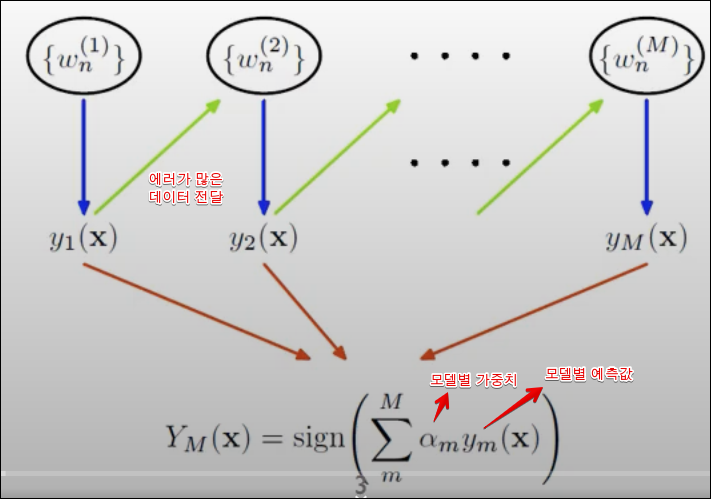
수도코드
Ada Boost의 수도코드를 정리해본다.

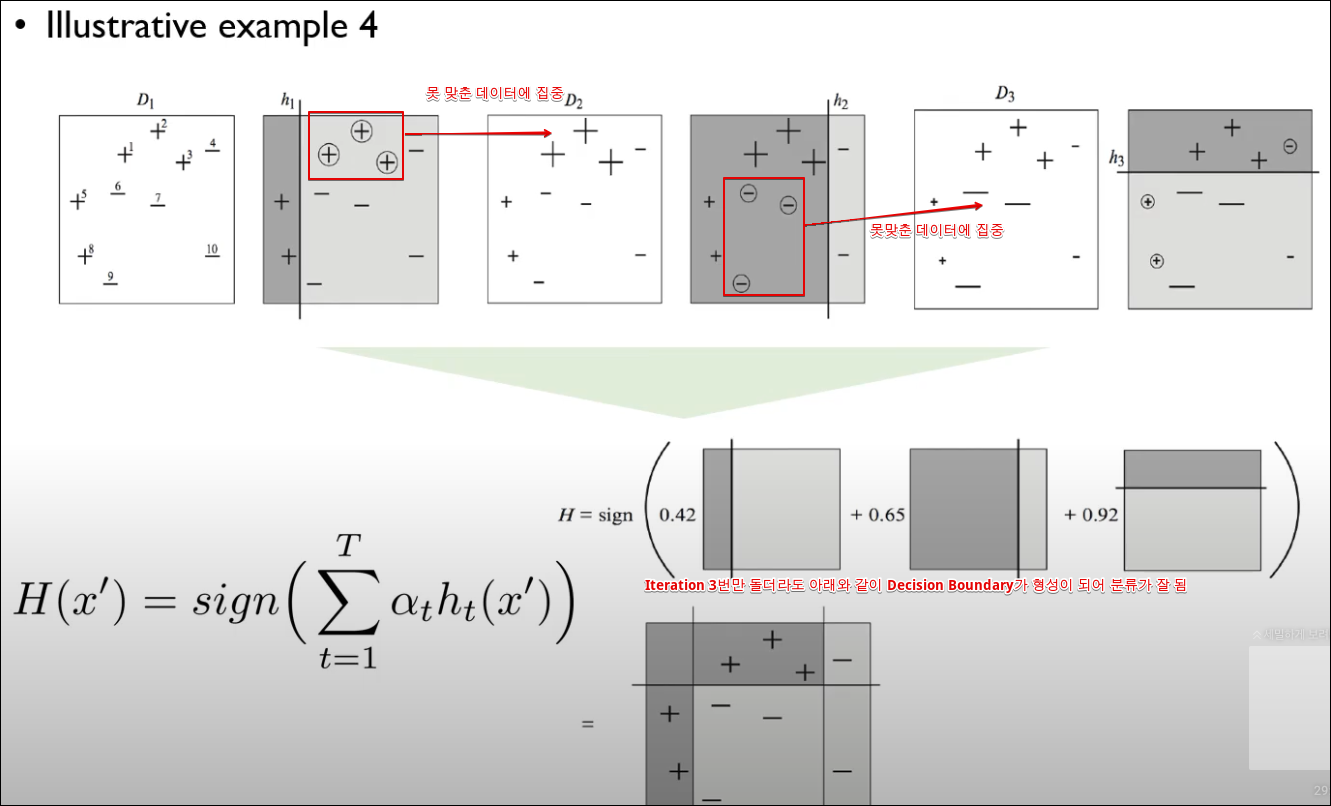
데이터 예시
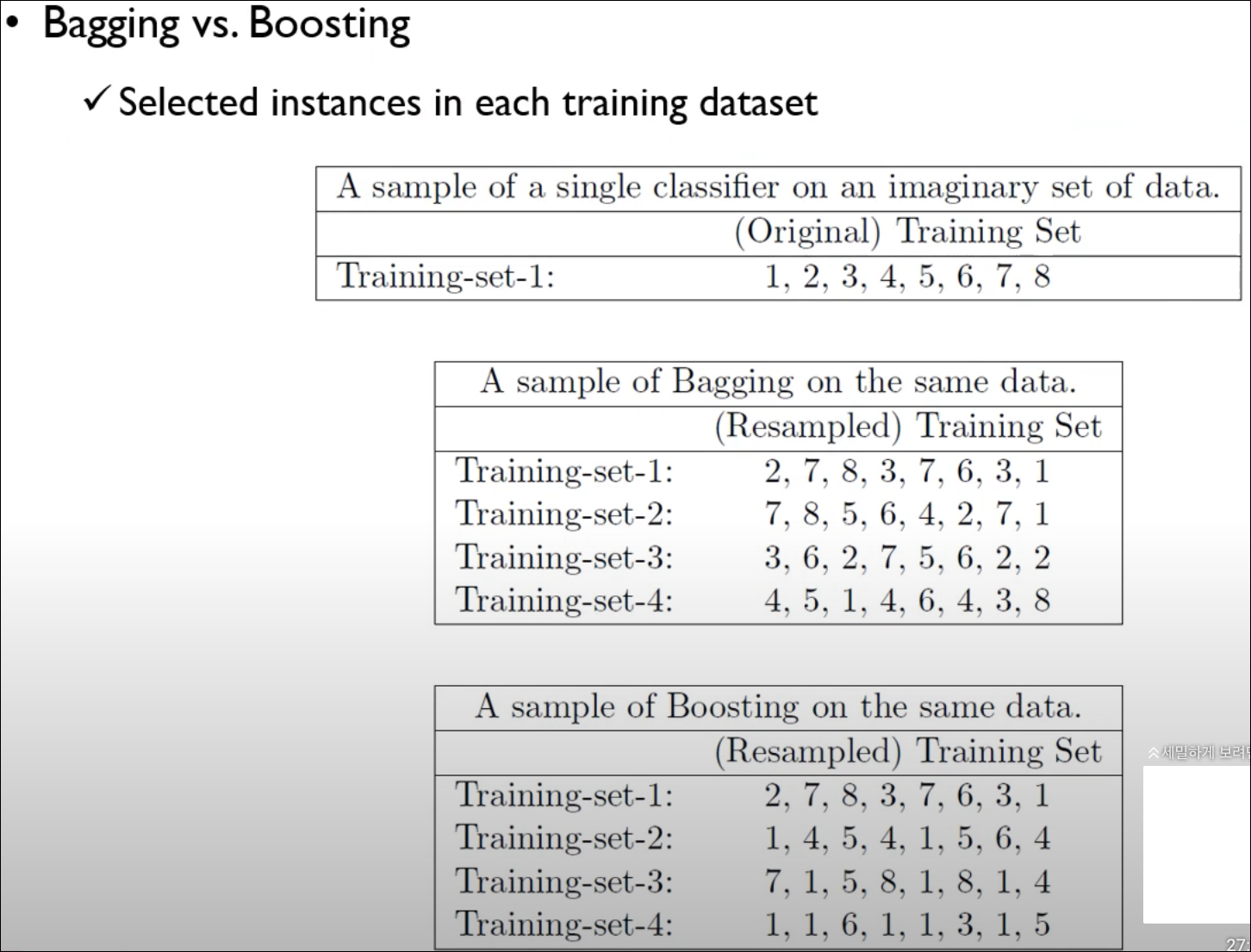
Bagging vs Boosting
아래와 같은 차이를 지닌다.
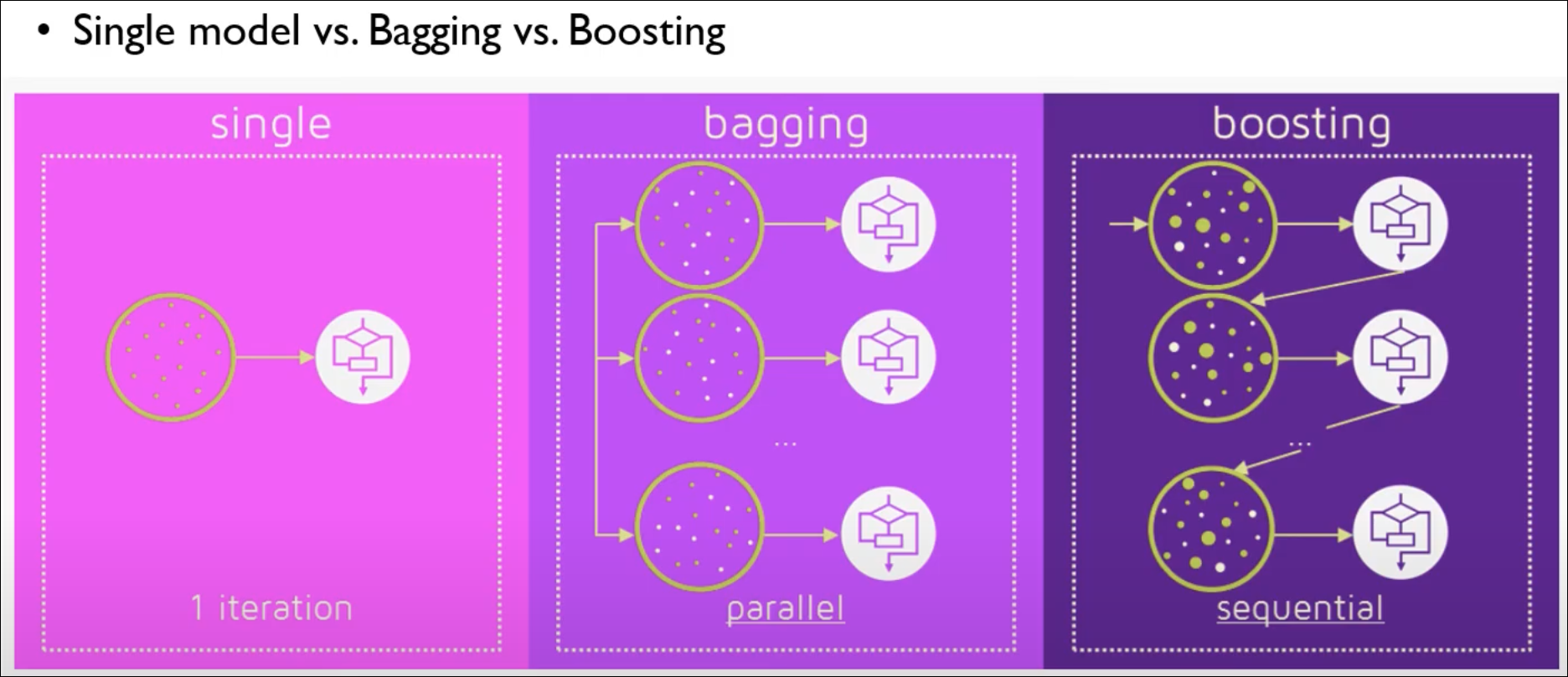
데이터 샘플을 뽑는 과정을 보면 Bagging/Boosting의 차이가 더 커진다.
Reference
- https://www.youtube.com/watch?v=HZg8_wZPZGU&list=PLetSlH8YjIfWMdw9AuLR5ybkVvGcoG2EW&index=25
