개요
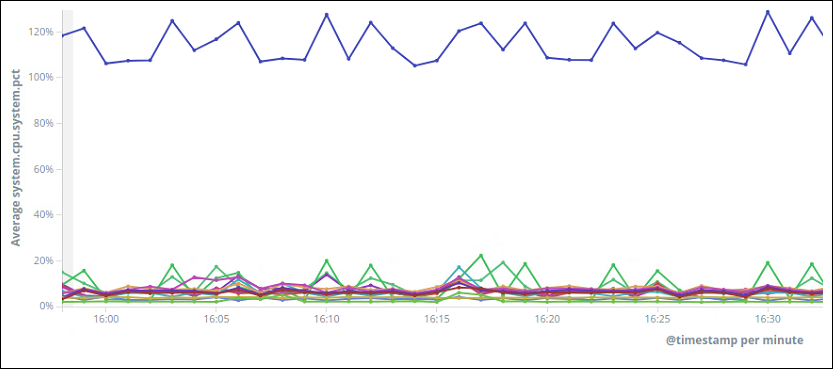
ES를 운영하는데 아래 그림과 같이 특정 노드가 CPU가 치솟는 현상이 발생하였다.
따라서 이부분에 대한 원인을 찾아보고 해결한 방법을 정리해둔다.
문제 접근
우선은 특별히 설정이 바뀐것이 없는데 특장 장비만 CPU가 치솟는게 이상해서 아래와 같이 원인을 분석해 보기로 한다. 이분석에서 변수를 없애기 위해 NRT로 진행되는 색인은 멈추었고 주말에 진행하여 클러스터 사용이 없는 상태에서 진행하였다.
- cluster health 체크
- hot thread 찾아보기
- 물리 장비 procss top 분석
이 부분을 각각 들여다 봤더니 결과는 아래와 같았다.
시도 1 : cluster health 체크
cluster모두 green상태로 정상동작 중이었다.
마스터/데이터/클라이언트 노드 모두 정상동작 중이었다.
시도 2 : hot thread 찾아보기
5분정도 살펴본 결과 이또한 CPU가 저렇게 치솟는데 ES 안에서는 이슈가 없는것으로 나왔다. CPU 지표는 계속 높은 수치를 기록하는데 ES 내부에서 관측되는 장비의 높은 워크로드가 없는것이 의심스러웠다.
시도 3 : process top 들여다보기
top을 5분정도 들여다 보니 아래와 같이 ES가 구동되는 java process 이외에 kswapd1이 지속적으로 높은 프로세스 점유율을 보여주고 있었다.
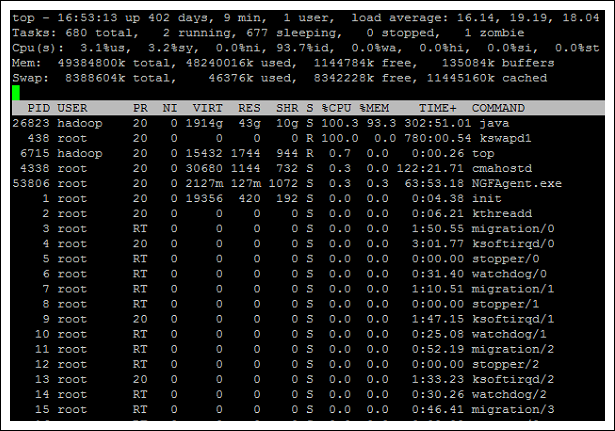
따라서 2번과 3번을 조합해 보았을때 메모리/디스크 swap으로 이슈가 발생하는 것이 원인이라고 판단했다. 이에 따라 ES의 swapping관련된 가이드를 찾아보기로 한다.
해결책
ES의 Swapping에 관련된 가이드를 보면 ES는 보통 물리 장비에 JVM위에 동작하기 때문에 swap이 필요치 않다고 한다.
또한 이미 ES 설정파일에 아래의 옵션을 사용하여 ES 프로세스가 메모리 만으로 한정되게 설정을 해주었었다.
하지만 이것만으로도 문제가 발생하였으므로 가이드에 나와있는 방법을 더 시도해보기로 한다.
그래서 찾은것이 물리장비의 swap을 아예 disable해버리는 아래의 명령어이다.
또한 swap관련 설정을 영원히 비활성화 하기 위해 문서에서는 /etc/fstab에 swap관련 설정이 있으면 모두 지우거나 주석처리하라고 되어있다.
검증
위의 명령어를 수행하고 얼마있다 추이를 지켜보니 기분좋게도 문제가 발생했던 노드의 cpu가 정상범위로 떨어지는 것을 알 수 있었다.
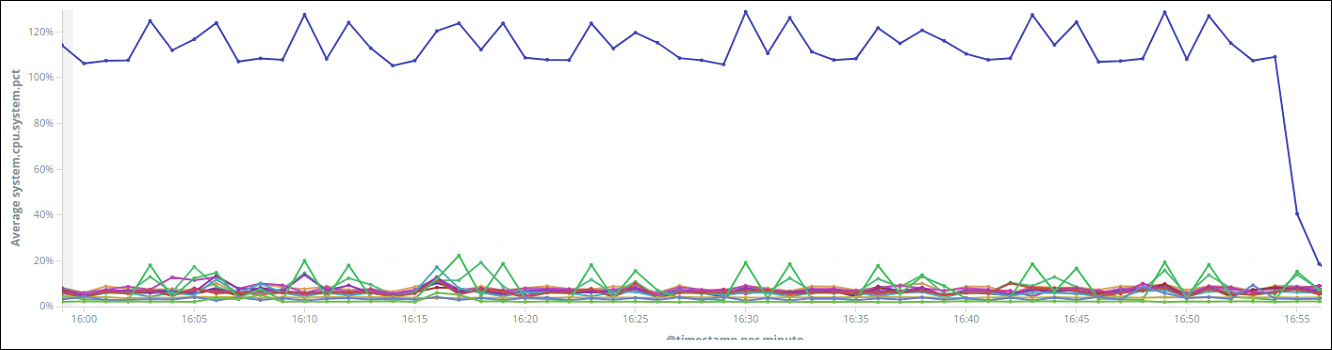
여기서 효과를 보았고 공식 문서에서도 swap이 비활성화 되기를 권장하니 전체 클러스터에 이 해결책을 적용하였다.
