개요
Apache Atlas 1.0.0-SNAPSHOT 기준으로 hive metadata를 import하는 방법을 정리해둔다.
binary 확보하기
binary는 아래 Maven 빌드로 만들어진 atlas/distro/target/apache-atlas-1.0.0-SNAPSHOT-bin.tar.gz를 이용한다.
$ git clone https://git-wip-us.apache.org/repos/asf/atlas.git atlas
$ cd atlas
$ mvn clean -DskipTests package -Pdist
import-hive.sh에 환경변수 지정
아래 내용을 import-hive.sh에 지정해주자.
hive-env.conf 수정
hive/conf/hive-env.conf에 아래 사항 추가한다. Atlas Hook용 library dependency를 추가해주는 작업이다.
atlas-application.properties 복사
atlas/conf/atlas-application.properties를 hive conf로 복사한다.
atlas-application.properties 수정
atlas hive hook은 하이브 metadata를 읽어 REST로 atlas WAS에 전송한다. 이를 위한 주소 설정을 atlas-application.properties에서 지정해준다.
jsersey 관련 jar 복사
실제로 import-hive.sh를 실행해보니 아래의 jar들 class not found exception이 떠서 이 클래스들을 복사해준 뒤 해결하였다.
atlas/distro/target/apache-atlas-1.0.0-SNAPSHOT-bin/apache-atlas-1.0.0-SNAPSHOT/server/webapp/atlas/WEB-INF/lib/jersey*.jar 복사해서 atlas/hook/hive/atlas-hive-plugin-iml 밑으로 복사
import-hive.sh 실행
atlas/bin/import-hive.sh를 실행한다. 기본 비번은 admin/admin이다.
아래와 같이 입력하면 쉘이 정상 실행된다.
$ ./bin/import-hive.sh
Using Hive configuration directory [/home/hive/hive/conf]
Log file for import is /home/hive/atlas/logs/import-hive.log
log4j:WARN No such property [maxFileSize] in org.apache.log4j.PatternLayout.
log4j:WARN No such property [maxBackupIndex] in org.apache.log4j.PatternLayout.
Enter username for atlas :- admin
Enter password for atlas :-
검증하기
Shell Script를 돌린 후 Atlas에 접속해보면 hive MetaData가 정상적으로 import 된것을 확인 할 수 있다.
hive-hook 추가
hive-site.xml에 추가해준다.
필자의 경우 또한 atlas 관련 jar가 로드가 잘 안되어서 hive/lib 밑으로 atlas 관련 jar를 옮겨주었다.
<configuration>
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>
</configuration>
hive-hook 관련 프로퍼티
hive-hook 관련 설정이다.
- atlas.kafka.zookeeper.connect=localhost:9026
- atlas.kafka.bootstrap.servers=localhost:9027
- atlas.hook.hive.synchronous – boolean, true to run the hook synchronously. default false. Recommended to be set to false to avoid delays in hive query completion.
- atlas.hook.hive.numRetries – number of retries for notification failure. default 3
- atlas.hook.hive.minThreads – core number of threads. default 1
- atlas.hook.hive.maxThreads – maximum number of threads. default 5
- atlas.hook.hive.keepAliveTime – keep alive time in msecs. default 10
- atlas.hook.hive.queueSize – queue size for the threadpool. default 10000
검증하기
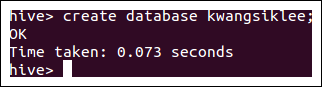
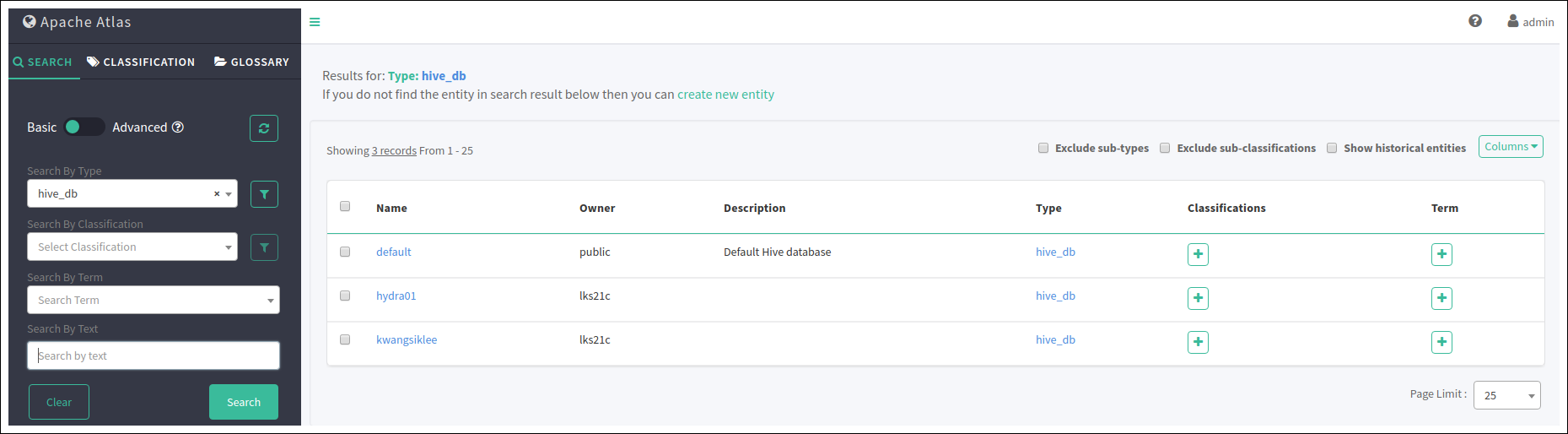
아래와 같이 hive에서 새로운 database를 만들고 나면 hive-hook에 의해 Apache Atlas로 자동으로 새로운 db가 추가되는 것을 확인 할 수 있다.
Data Lineage 테스트
데이터 리니지 기능을 테스트하기 위해 아래와 같이 쿼리를 수행해보자.
use kwangsiklee;
create table abc (name string);
create table fruits_new (name string, price int) row format delimited fields terminated by ',';
load data local inpath 'fruits.txt' overwrite into table fruits_new;
fruits.txt는 아래와 같이 기재되어 있다.
select를 해보자.
hive> select * from fruits_new;
OK
apple 150
mango 80
orange 60
pineapple 50
create view fruits_new_v as select * from fruits_new;
create view fruits_new_v2 as select * from fruits_new_v;
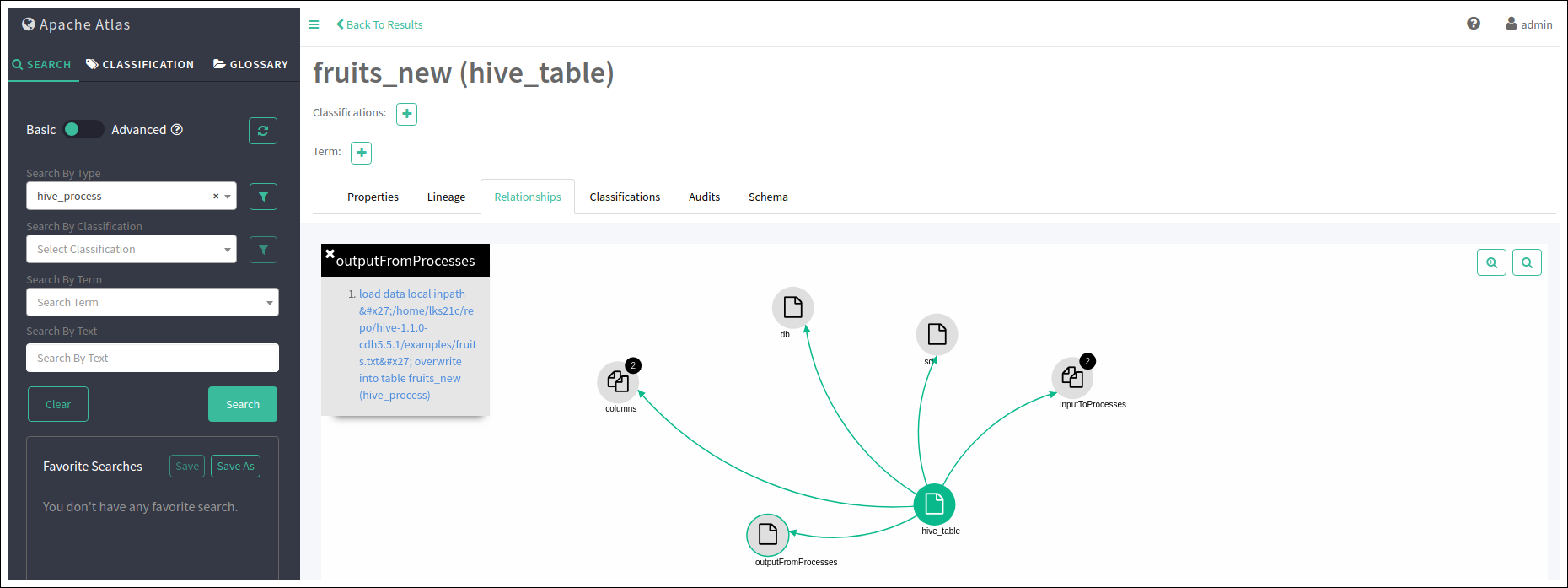
위의 쿼리에 의해 어떤 테이블로 부터 view가 만들어졌는지 등을 Lineage로 확인 할 수 있다.
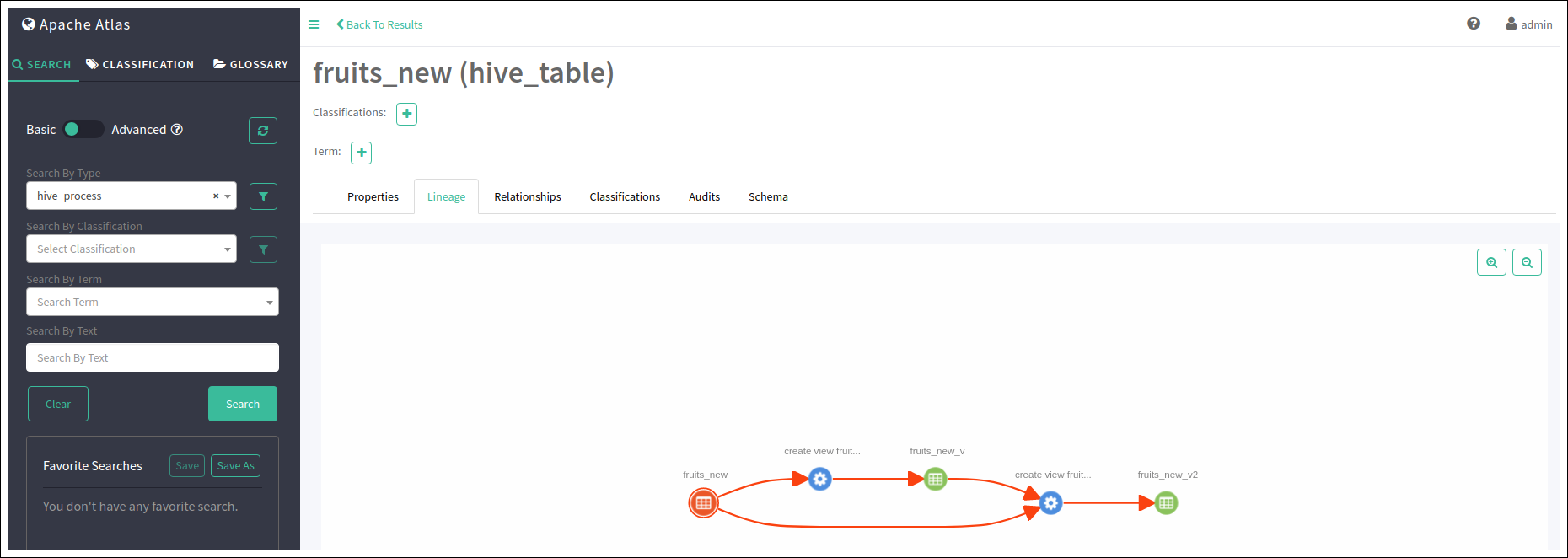
또한 테이블 생성과 쿼리의 관계를 파악하여 fruits_new 테이블의 데이터가 file로 부터 load되었다는 것도 파악되었다.