개요
TensorFlow Wide & Deep Learning Tutorial를 읽어보고 중요한 부분을 정리해둔다.
목적
이 튜토리얼에서는 tf.estimamtor API를 이용하여 어떻게 wide linear model과 deep feed-forward 뉴럴 네트워크를 학습 시키는 방법을 소개한다. 거대한 regression과 Classification 문제를 sparse한 입력 geature를 가지고 학습시키는데 유용하다. 더 자세한 내용은 논문을 참고한다.
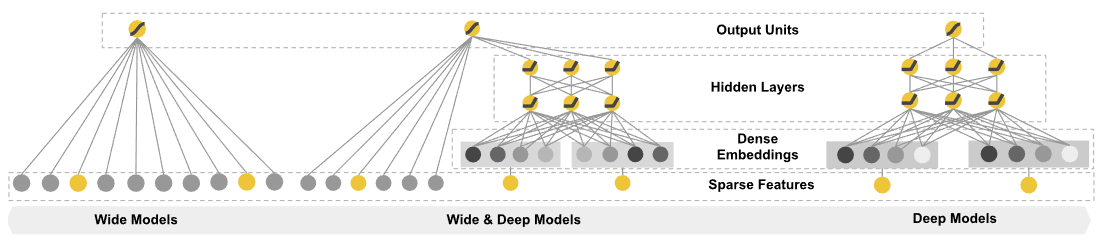
네트워크 구조
각각의 모델에서 사용하는 feature는 아래와 같이 정의하고 있다.
- Select features for the wide part: Choose the sparse base columns and crossed columns you want to use.
- Select features for the deep part: Choose the continuous columns, the embedding dimension for each categorical column, and the hidden layer sizes.
- Put them all together in a Wide & Deep model (DNNLinearCombinedClassifier).
코드 실행법
- 튜토리얼 코드 clone
- 아래와 같이 코드 실행
코드를 아래와 같이 실행하면 된다.
Base Feature 칼럼
기본 feature들은 wide 모델이든 deep 모델이든 사용한다.
import tensorflow as tf
# Continuous columns
age = tf.feature_column.numeric_column('age')
education_num = tf.feature_column.numeric_column('education_num')
capital_gain = tf.feature_column.numeric_column('capital_gain')
capital_loss = tf.feature_column.numeric_column('capital_loss')
hours_per_week = tf.feature_column.numeric_column('hours_per_week')
education = tf.feature_column.categorical_column_with_vocabulary_list(
'education', [
'Bachelors', 'HS-grad', '11th', 'Masters', '9th', 'Some-college',
'Assoc-acdm', 'Assoc-voc', '7th-8th', 'Doctorate', 'Prof-school',
'5th-6th', '10th', '1st-4th', 'Preschool', '12th'])
marital_status = tf.feature_column.categorical_column_with_vocabulary_list(
'marital_status', [
'Married-civ-spouse', 'Divorced', 'Married-spouse-absent',
'Never-married', 'Separated', 'Married-AF-spouse', 'Widowed'])
relationship = tf.feature_column.categorical_column_with_vocabulary_list(
'relationship', [
'Husband', 'Not-in-family', 'Wife', 'Own-child', 'Unmarried',
'Other-relative'])
workclass = tf.feature_column.categorical_column_with_vocabulary_list(
'workclass', [
'Self-emp-not-inc', 'Private', 'State-gov', 'Federal-gov',
'Local-gov', '?', 'Self-emp-inc', 'Without-pay', 'Never-worked'])
# To show an example of hashing:
occupation = tf.feature_column.categorical_column_with_hash_bucket(
'occupation', hash_bucket_size=1000)
# Transformations.
age_buckets = tf.feature_column.bucketized_column(
age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
The Wide Model: Linear Model with Crossed Feature Columns
wide 모델은 sparse와 crossed feature 칼럼을 사용한 linear 모델이다.
base_columns = [
education, marital_status, relationship, workclass, occupation,
age_buckets,
]
crossed_columns = [
tf.feature_column.crossed_column(
['education', 'occupation'], hash_bucket_size=1000),
tf.feature_column.crossed_column(
[age_buckets, 'education', 'occupation'], hash_bucket_size=1000),
]
Wide 모델을 사용한 crossed feature 칼럼은 feature간의 상호작용을 효과적으로 기억할 수 있다. 이에 반해 crossed feature 칼럼의 한가지 제약은 이것을 통해서 학습 데이터에서 나타난 적이 없는 feature 조합을 일반화 할수 없다. 이부분은 deep 모델의 임베딩을 통해 해결해보자.
The Deep Model: Neural Network with Embeddings
deep 모델은 feed-forward 뉴럴 네트워크 이다. 각 sparse하거나 고차원의 카테고리 feature는 우선 저 차원과 dense한 실수 벡터로 변한된다. 이를 종종 임베딩 벡터라 부르기도 한다. 이 저차원 dense 임베딩 벡터는 연속된 feature로 이어붙여지고 뉴럴넷의 히든 레이어로 feed forwarding된다. 임베딩 값은 랜덤하게 초기화되고 모든 다렌 모델 파라미터로 loss를 최소하하게 학습된다. 혹시 임베딩에 대해 더 궁금하다면 Vector Representations of Words 튜토리얼이나 Word embedding를 참고한다.
카토고리 칼럼을 표현하는 또다른 방법은 one-hot(or multi-hot) 인코딩으로 뉴럴넷에 feeding하는 것이다. 이것은 때로 적은수의 값을 가진 카테고리 칼럼을 다룰때 적절하다. 예를들어 예제 단어들을 one-hot 인코딩으로 나타내면 아래와 같다. 이것은 고정된 길이의 표현법으로 반면에 임베딩은 더 유연하고 계산도 학습시에 일어난다.
- “Husband” -> [1, 0, 0, 0, 0, 0]
- “Not-in-family” -> [0, 1, 0, 0, 0, 0]
category 칼럼을 이용한 임베딩을 embedding_column을 이용해 구현하고 이를 continuous 칼럼과 concat한다. 우리는 또한 **indicator_column **을 이용해 일부 카테고리 칼럼을 multi-hot 표현으로 구현한다.
코드는 아래와 같다.
deep_columns = [
age,
education_num,
capital_gain,
capital_loss,
hours_per_week,
tf.feature_column.indicator_column(workclass),
tf.feature_column.indicator_column(education),
tf.feature_column.indicator_column(marital_status),
tf.feature_column.indicator_column(relationship),
# To show an example of embedding
tf.feature_column.embedding_column(occupation, dimension=8),
]
위의 코드에서 deimension은 더 높은 차수를 부여해 줄수록 모델은 더 높은 자유도를 가지고 학습을 진행한다. 간단하게 얘기하자면 dimesion 8은 모든 feature의 칼럼이다. 경험적으로 dimension 값을 정할때 $ log_2 (n)$이나 $k\sqrt[4]n$으로 $n$은 feature의 cardinality값이고 $k$는 $n$보다 작은 상수값이다.
dense 임베딩을 통해 학습데이터에서 본적이 없는 데이터도 deep 모델이 일반화를 더 잘 수행하고 feature의 쌍에 대해 예측을 더 잘 수행한다. 하지만, 두 feature 칼럼이 sparse하고 고차원일 경우 상호간의 interaction matrix(이를 테면 공분산 행렬 같은게 아닐까)에 잠재되어있는 관계를 저차원으로 효과적으로 임베딩하는게 어렵다. 이 경우 대부분의 feature 쌍의 상호관계는 몇몇을 제외하고 모두 0이지만 dense 임베딩에서는 모든 feature 쌍에 대해 0이아닌 값을 가지게 되므로 over-generalize 된다.(필자의 해석에 의하면 좀 under fit 되어 버리는 것이다.) 반면에, linear model의 경우 이런 예외 룰을 적은 파라미터로 효과적으로 기억한다.
이제 이때까지 배운 wide와 deep모델을 조합하여 서로의 강점과 약점을 보완해보자.
위 부분의 필자의 해석은 아래와 같다. 예를 들어 직업 및 학력에 대한 조합으로 feature를 만든다면 feature의 표현은 아래와 같을 수 있다. 예를 들어 학사에 프로그래머일 경우 아래와 같이 나타낸다.
이때 deep 모델의 장점은 전혀 등장한 적이 없는 학사에 디자이너의 경우도 적어도 비스무리하게 0.1 [0.1 0.1 0.1 0.9 0.5] 뭐 이런식으로 임베딩 될 여지가 있어서 모델 성능 일반화에 도움이 된다는 것이다. 반면 deep 모델의 단점은 학사에 프로그래머 이런 경우도 깔끔하게 크게 영향이 없는 0에 가까운값도 0이 아닌 작은 값으로 표현되기 때문에 확실히 관계가 없는 feature들도 interaction이 단절되지 않아 모델 성능에 도움이 안될 여지가 있다.
또한 linear 모델의 장점은 서로 관계가 없는 interaction은 확실히 0을 만들어 쓸데없는 관계로 인해 모델성능이 떨어질 일이 없다는 것이고 linear 모델의 단점인 학습에 등장한 적이 없는 feature가 등장했을때는 아예 모델이 예측을 못하는 일이 발생하는 것이다.
- linear model -> 0 0 0 0 1 1 (2조합의 합의 one hot 인코딩)
- deep model -> 0.1 0.1 0.1 0.1 0.7 0.9
따라서 위의 2가지 장점은 취하고 2가지 단점은 상호 보완하게 만드는 것이 wide & deep 모델의 목표이다.
Combining Wide and Deep Models into One
wide and deep 모델은 2가지의 최종 출력 로그의 예측률을 합친다. 그리고 이것을 로지스틱 loss 함수로 feeding한다. 사용자는 DNNLinearCombinedClassifier를 사용하는 것만으로 모든 그래프 정의와 변수 할당은 처리등을 자동화할수 있다.
model = tf.estimator.DNNLinearCombinedClassifier(
model_dir='/tmp/census_model',
linear_feature_columns=base_columns + crossed_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[100, 50])
Training and Evaluating The Model
모델을 학습시키기 전에 Census dataset에 대한 정보는 [튜토리얼 정리] 텐서플로우 Linear Models를 참고하자.
아래 코드를 통해 train과 evaluate가 가능하다.
# Train and evaluate the model every `FLAGS.epochs_per_eval` epochs.
for n in range(FLAGS.train_epochs // FLAGS.epochs_per_eval):
model.train(input_fn=lambda: input_fn(
FLAGS.train_data, FLAGS.epochs_per_eval, True, FLAGS.batch_size))
results = model.evaluate(input_fn=lambda: input_fn(
FLAGS.test_data, 1, False, FLAGS.batch_size))
# Display evaluation metrics
print('Results at epoch', (n + 1) * FLAGS.epochs_per_eval)
print('-' * 30)
for key in sorted(results):
print('%s: %s' % (key, results[key]))
최종 출력 정확도는 약 85.5%가 나올 것이다.
이 튜토리얼은 작은 데이터셋에 대해 API에 친숙해지기 위한 빠른 예제이다. Wide & Deep 모델은 대용량 데이터셋을 더 많은 sparse feature를 가지고 돌리더라도 강력함을 발휘한다. 다시한번 얘기하지만논문을 참고하면 어디에 이 모델을 적용하면 좋을지에 대한 더 많은 아이디어를 얻을 수 있다.
