개요
톰슨 샘플링(thompson sampling)에 대해 공부하여 개념을 이해한 후 핵심을 정리해둔다.
톰슨 샘플링이 왜 좋은가?
톰슨 샘플링을 이해하기에 앞서 과연 이 알고리즘이 내가 공부할 가치가 있는지 생각이 들 수 있다. 이부분에 있어서는 MAB 자체가 배너광고 시스템이나 추천 시스템에서 성능을 끌어올리는데(클릭율을 높이는데) 매우 중요한 역할을 한다는것을 공감해야 한다. 바꿔 얘기하면 MAB가 유용한가에 대해 먼저 공감해야 한다. 이부분 까지 설명하는것은 논점에서 벗어나는 것 같으니 이부분은 찾아서 이해를 하자. 이 전제가 공감이 된다면 여러 선택지가 있는데 이중에서도 톰슨 샘플링의 경우 Google Analytics와 Netflix에서도 적용하고 있다고 한다. 즉 배너를 노출하거나 추천 컨텐츠 중에서 선별해서 노출하는 등의 서비스에서 사용자의 CTR(Click Through Ratio) 로그를 취합할 수 있다면 NRT(준 실시간)로 사용자의 클릭을 끌어올리는데 주요한 역할을 하는것이 검증이 되었다. 따라서 필자는 이 알고리즘을 공부할 가치가 있다고 판단한다.
전제사항
개념을 이해하고 설명하는데 있어 송호연님 글 설명처럼 여러개의 배너광고 중 사용자에게 노출했을때 클릭확률이 제일 좋은 배너를 노출하는 MAB 문제를 해결하는 것으로 한다. 필자의 글을 읽기에 앞서 링크의 글을 먼저 이해하는것이 필요하다. 조금 더 Deep하게 들어가고 MAB 전반에 대한 이해가 필요하다면 전상혁님 정리자료가 좋다.
결론
톰슨 샘플링은 아래의 구조로 동작한다.
또한 여기에서 착안할 수 있는 것은 톰슨 샘플링은 매 클릭건 마다 평가할 것이 아니라 일정 주기로 batch로 돌아도 될것 같다는 것이다.
- 베타 분포 공간에 각 배너의 확률밀도함수(PMF)를 Draw
- 각 배너의 갯수만큼 random variate를 샘플링 -> 이값을 argMax()값을 비교하여 최대 값의 배너를 취함)
- argMax로 선정된 배너 노출
- 이후 클릭O/클릭X가 바뀐 값으로 다시 1번부터 실행
핵심만 추가 정리
언급하신 블로거분들이 잘 정리해주신 내용이라 필자는 필자가 이해하기에 부족했던 부분만 짚고 넘어간다.
핵심#1 샘플링 값
송호연님 글 설명에서 아래와 같은 상황에서의 베타분포 및 샘플링 값(Random Variate)에서 이 샘플링 값이 어떻게 구해지는지 개념이 안잡혔다.
- 배너1 : 3번 클릭O, 2번 클릭X
- 배너2 : 2번 클릭O, 3번 클릭X
- 배너3 : 2번 클릭O, 2번 클릭X
이부분은 직접 코드를 통해 개념을 이해하다 보니 매번 실행 될때 마다 샘플링 값은 바뀔 수 있고 이게 확률분포에 영향을 받긴 하지만 아직 PMF가 특정 상태로 수렴하기 전에는 꼭 1에 더 가까운 방향의 배너가 선택되는것은 아니란 것을 알 수 있었다.
더 예를 들자면 같은 밀도함수인데 3회 실행을 했을때 구해진 샘플값을 보자.
- 배너 1 샘플값이 제일 높음
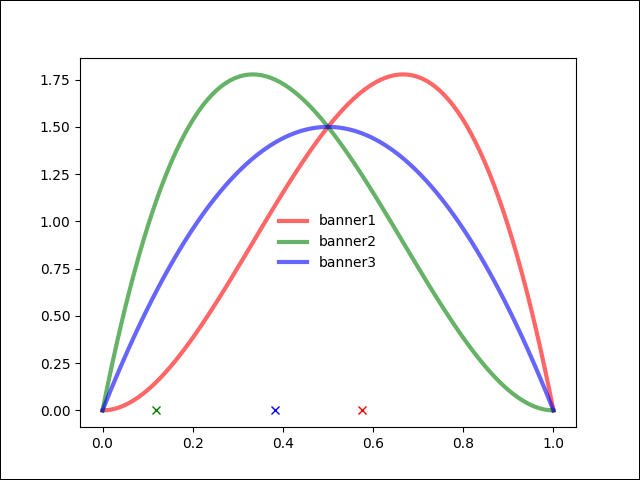
- 배너2 샘플값이 제일 높음
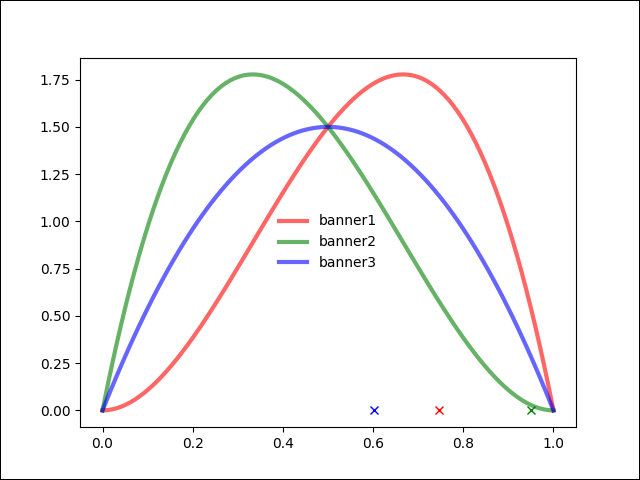
- 배너3 샘플값이 제일 높음
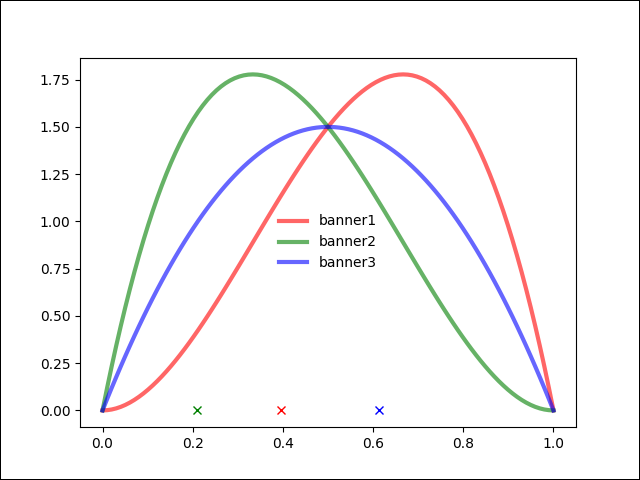
즉 아직 PMF가 수렴하기 전에는 샘플링에 의해 다른 배너가 선택될 여지가 있는 것이다.
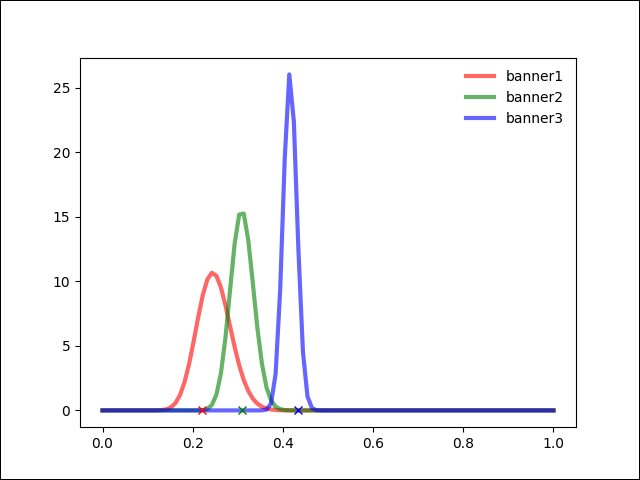
반면 여러 차례 수행에 의해 아래와 같이 PMF값이 어느정도 수렴에 가까워 질때는 샘플링 값을 여러 차례 구해 보아도 배너 그래프의 확률 분포가 우세한 배너 쪽으로만 계속 선택이 되는것을 발견했다.
자세히 보면 아래의 샘플링 값은 미세하게 다르지만 선택되는 배너는 같다.
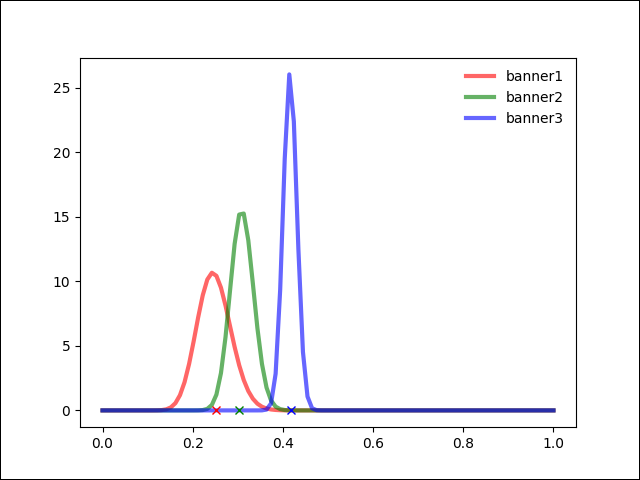
핵심#2 수도코드

위 알고리즘 수도코드를 보면 결국 베타분포 공간에서 각 배너의 S(클릭한 횟수)와 B(클릭안한 횟수)를 이용하여 학률밀도함수(PMF)를 Draw하고 여기서 값을 샘플링하여 이 값중 가장 큰 값의 배너를 선택한다.(argmax) 또한 이후 클릭율이 어떻게 바뀌었는지 다시 관측하고 클릭 성공(S)과 클릭 실패(F)를 기록하여 다시 톰슨샘플링을 반복한다.
