개요
1992년에 발표되었다는게 믿겨지지 않는 Techniques for Automatically Correcting Words in Text 논문을 분석하여 내용을 정리한다.
Introduction
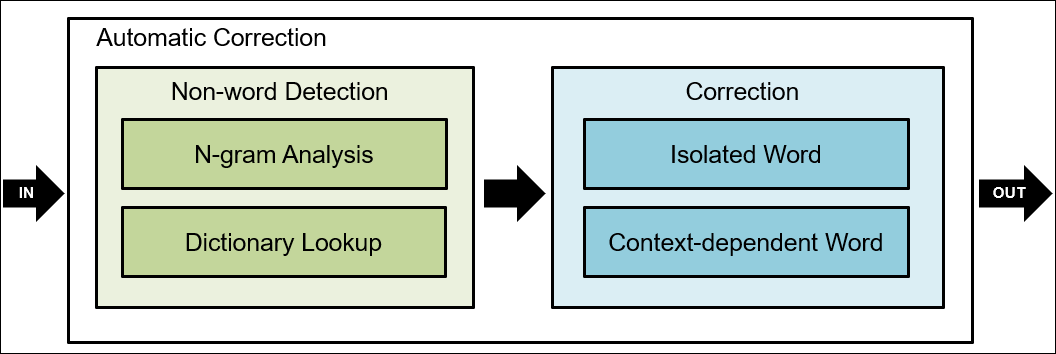
- Detection and Error Correction
- Interactive vs Automatic correction
- Focus on isolated words without taking context into account 예: context error correction
- form, from / minute, minuet
- ater : after, later, alter, water, ate
N-gram Analysis Techniques
- n-letter subsequences of words or strings
- unigrams, bigrams, trigrams
- Input string + precompiled table of n-gram
- statistics to ascertain either its existence or its frequency
- Better performance than OCR devices
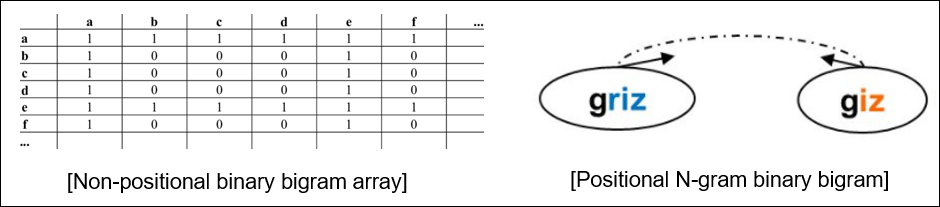
- Nonpositaional and Positional
- Nonpositaional는 위치 고려 없이 BOW처럼 0/1로 표현
- Positional은 위치를 고려함
Dictionary Lookup Techniques
- 사전에서 단어를 찾는 방법
- Simple?
- Depending on the size of the dictionary (25K~250K)
- 이 방법의 3가지 문제점
- 패턴 매칭 알고리즘
- 단어사전을 해시로 계산해놔서 실제로 해시로 lookup함
- Dictionary-partitioning schemes
- 자주 사용하는 단어를 캐시에 올리고 그 다음은 조금 더 느린 캐시를 쓰는 방법
- 형태소 처리 방법(Morphological-processing techniques)
- 단어를 원형으로 저장해놓고 이를 활용하여 lookup
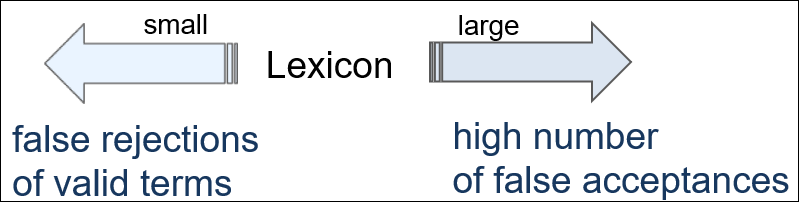
Dictionary Construction Issues
- Small Lexicon vs Large Lexicon
The Word Boundary Problem
- 단어의 경계 = 공백문자
- 공백으로 인해 오타가 났는데 2개 이상의 부분 단어가 말이 되는경우 예를 들어 understandhme는 under/stand/me 모두 형식상으로는 맞는 단어이다.
- ofthe, understandhme
- Sp ent, th ebook
- In form -> inform
- Forget -> for get
- 오타 수정 연구에 있어 아직 확연히 풀리지 않은 문제중 하나로 남아있음
Isolated word Error Correction
- 단순하게는 오타를 detecting 하는것만으로도 의미가 있다고 생각할수 있으나 대부분의 어플리케이션에서는 오타 감지 많으로 충분치 않다.
- detected되고 corrected 되어야 함.
Spelling Error Patterns
- 기본 에러 타입
- insertion, deletion, substitution and transposition
- 단어 길이 효과
- 짧은 단어가 더 처리가 어렵다.
- First-Position Errors
- 첫번째 위치의 단어가 에러일 가능성이 상대적으로 거의 없다.
- Keyboard Effects
- 인접한 키들
- Error Rates
- 스펠링 에러가 아직 패턴을 규정하기에는 풍부하지 않다.
- 말뭉치의 크기/ entry mode(사용자가 어떤 입력을 했는지) / 언제 연구를 진행했는지
- 음성적 에러
- 익숙하지 않은 단어를 음성적으로 맞다고 생각하는데로 추측해서 타이핑 할때 발생
- Heuristic Rules And Probabilistic Tendencies
- 이번 논문에서는 분석결과 아래와 같은 오타의 특징이 있었다고 함
- 17개의 경험적 패턴, 12개의 잘못된 자음/모음의 사용
- 5개의 순서 조정
- 일반적이 오타
- 논문에서 이 패턴의 오타를 리스트업하였음
Techniques for Isolated-Word Error Correction
앞전까지 Detection에 대해 살펴보았다면 이제 Correction에 대해 알아보자.
isolated error correction은 아래의 세부문제로 나뉘어 질 수 있다.
- Detection of an error (discussed above)
- Generation of candidate corrections similarity key / rule-based techniques
- Ranking of candidate corrections MED ~ Neural Nets
오타 수정은 크게 나누자면 2가지 테크닉이 있음
- Geration 방식
- Similarity key techniques
- Rule-based techniques
- Ranking 방식
- Minimum edit distance
- N-gram based techniques
- Probabilistic techniques
- Neural nets
Similarity Key Tech. : SOUNDEX and its variants
-
Phonetic Algorithms
- NYSIIS
- Metaphone
- Double Metaphone
- Metaphone3
- Caverphone
-
SOUNDEX algorithm
- Problem: How can we find a list of possible corrections?
- Solution: Store words in different boxes in a way that puts the similar words together.
[Example] punc와 punk가 같은 발음이니 어떻게 Soundex로 처리되는지 알아보자.
- 첫글자를 수집함 예: punc 는 P를 획득함
- 각 문자열에 숫자를 맵핑함
- a, e, h, I, o, u, w, y -> 0 or drop
- b, f, p, v ->1
- c, g, j, k, q, s, x, z ->2
- d, t -> 3
- l -> 4
- m, n ->5
- r ->6 예: punc -> P052
- 모든 0을 drop하고 글자를 반복함 예: P052 -> P52
- 같은 박스안의 실제 단어를 살펴봄
- punk is also in the P52 box.
- 발음이 서로 다른 것을 아래와 같이 표기가 달라짐
- Robert : R163
- Robin : R150
Rule-Based Techniques
rule을 정해 오타를 수정함
- 자주 나오는 오타를 맞게 교정함 예: hte -> the
- Rules
- based on inflections:
- V+C+ing -> V+CC+ing [ where V = vowel(모음) and C = consonant(자음) ]
- occuring -> occurring
- 흔한 오타에 근거함 (예를 들어 키보드 타이핑 오류나 위치 뒤바뀜):
- Cie -> Cei
- based on inflections:
- Yannakoudakis et al. (1983) : Dictionary Based Technique (Knowledge-based spelling correction program based on the rules)
Minimum Edit Distance
- 어떻게 한 단어와 다른단어가 다르다는 것을 측정할 것인가?
- 얼마나 많은 연산을 한 단어가 다른 단어로 변환하는데 필요한지를 측정
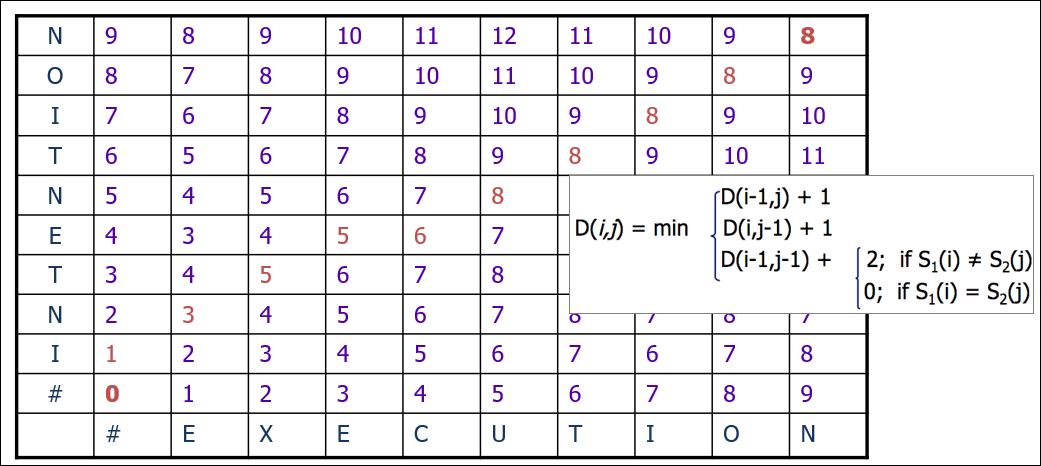
INTENTION과 EXECUTION의 편집거리를 살펴보면 INTENTION을 EXECUTION으로 변환하는데는 하나의 deletion, 3개의 substitution, 1개의 insertion이 필요하므로 거리는 5가 된다. 만약 substitution을 cost 2로 계산한다면 8이 된다.

- Minimum Edit Distance 정의
- For two strings
- X of length n
- Y of length m
- We define D(i,j) : the edit distance between X[1..i] and Y[1..j] i.e., the first i characters of X and the first j characters of Y
- The edit distance between X and Y is thus D(n,m)
Computing Minimum Edit Distance
알고리즘에 대한 설명은 Minimum Edit Distance – Explained ! – Stanford University가 도움이 된다.
핵심은 값을 구할 좌표에서 아래의 3가지 값중 최소값을 구한다. – 타겟 좌표의 왼쪽값 + 1 – 타겟 좌표의 아래쪽값 + 1 – 타겟 좌표의 왼쪽 아래 값 + (타겟 좌표의 가로 세로 문자가 같으면 0, 다르면 2)
예를 들자면 아래 그림에서 N과 E가 교차되는 지점이라면 아래의 3개의 값의 최소값으로 3이된다. – 타겟 좌표의 왼쪽값, 2(N과 #가 교차하는 값) + 1 = 3 – 타겟 좌표의 아래쪽값, 2(I와 E가 교차하는 값) + 1 = 3 – 타겟 좌표의 왼쪽 아래 값(1, I와 #가 교차하는 값) + 2(N과 E가 서로 다르므로) = 3
영어설명은 아래와 같다.
- Dynamic programming: A tabular computation of D(n,m)
- Solving problems by combining solutions to sub-problems.
- Bottom-up
- We comp ute D(i,j) for small i,j
- And compute larger D(i,j) based on previously computed smaller values i.e., compute D(i,j) for all i (0 < i < n) and j (0 < j < m)
N-gram Based Techniques
-
N-gram
- An N-gram is a sequence of N adjacent letters in a word
- The more N-grams, two strings, share the more similar they are.
-
Dice coefficient: DICE(X, Y) = 2 x |n-gram(X) ∩ n-gram(Y)| / |n-gram(X)| + |n-gram(Y)|
-
예제
- Zantac vs Contac
- Bigrams in Zantac : Za an nt ta ac 5 bigrams
- Bigrams in Contac : Co on nt ta ac 5 bigrams
- DICE(Zantac, Contac) = (2 x 3) / ( 5+5) = 0.6
-
Problems :
- N-gram techniques doesn’t show good performance on short words. (e.g. Trigram – The words of length 3 )
- N-gram similarity measure works best for insertion and deletion errors, well for substitution errors, but very poor for transposition errors.
Probabilistic Techniques
Two main probabilities are taken into account:
- Transition Probability : Markov Assumption (n-Gram based LM)
- probability (chance) of going from one letter to the next. e.g., What is the chance that a will follow p in English? That u will follow q?
- Confusion Probability : probability of one letter being mistaken (substituted) for another (can be derived from a confusion matrix) e.g., What is the chance that q is confused with p?
- Useful to combine probabilistic techniques with dictionary methods [ Baye’s Rule: Toussaint, 1978; Hull & Srihari, 1982; Viterbi Algorithm: Forney, 1973 – lexicon (Trans. P) + OCR Device Ch.(Conf. P) ]
- For the various reasons discussed above (keyboard layout, phonetic similarity, etc.) people type other letters than the ones they intended.
- It is impossible to fully investigate all possible error causes and how they interact, but we can learn from watching how often people make errors and where.
- One way of doing so is to build a confusion matrix = a table indicating how often one letter is mistyped for another (this is a substitution matrix)
Confusion matrix for spelling errors
http://norvig.com/ngrams/spell-errors.txt 를 가지고 confusion matrix를 만듦

How do we decide if a (legal) word is an error?
- Noisy Channel Model
- source와 decoder로 구성됨
- source는 정답지(맞는 단어)
- noise channel을 거쳐 나오는 오류의 단어를 베이지안 확률로 제일 높은 확률의 단어로 추측함
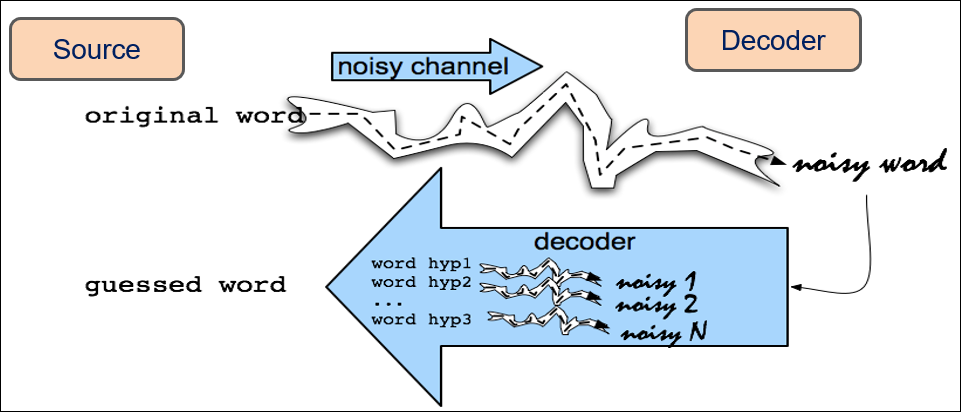
- Language generated and passed through a noisy channel
- Resulting noisy data received
- Goal is to recover original data from noisy data
-
Metaphor comes from Jelinek’s (1976) work on speech recognition, but algorithm is a special case of Bayesian inference (1763)
-
Channel Input: w (true word);
-
Output : O (spell error word)
- Decoding: hypothesis
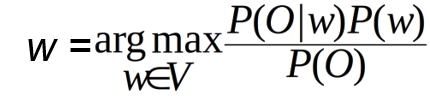
Appling Bayes’ Rule

Applying Bayes’ Rule
오타 caat가 어떤 단어로 교정될지를 베이지안 확률로 예측해보는 것이다. carrot보다 cat이 확률이 더 높기 때문에 cat으로 교정한다.

Neural Nets
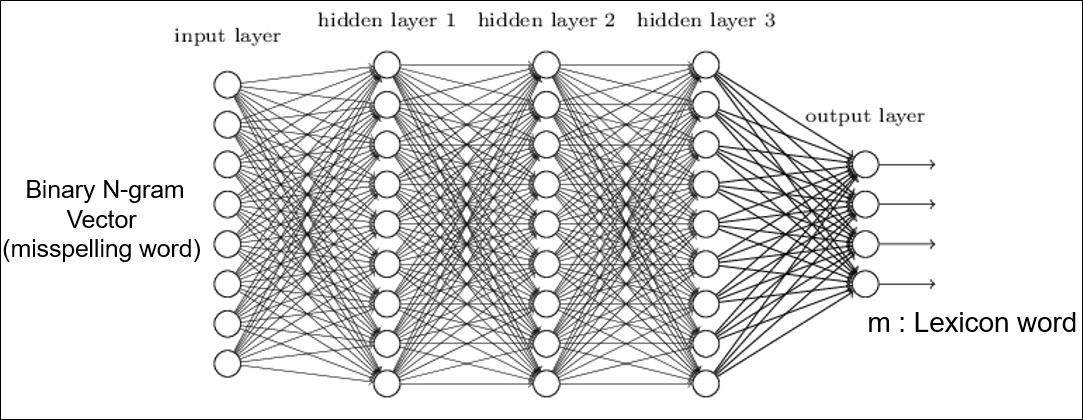
- Application
- OCR (handwritten number recognition e.g. zipcode, receipt readiing): Matan 1992; Keeler 1992
- 2-phase hand-printed-recognizer: Blur 1987
- Name / address correction: Kukich 1988;
- Text-to-speech: Kukich 1990
- ….
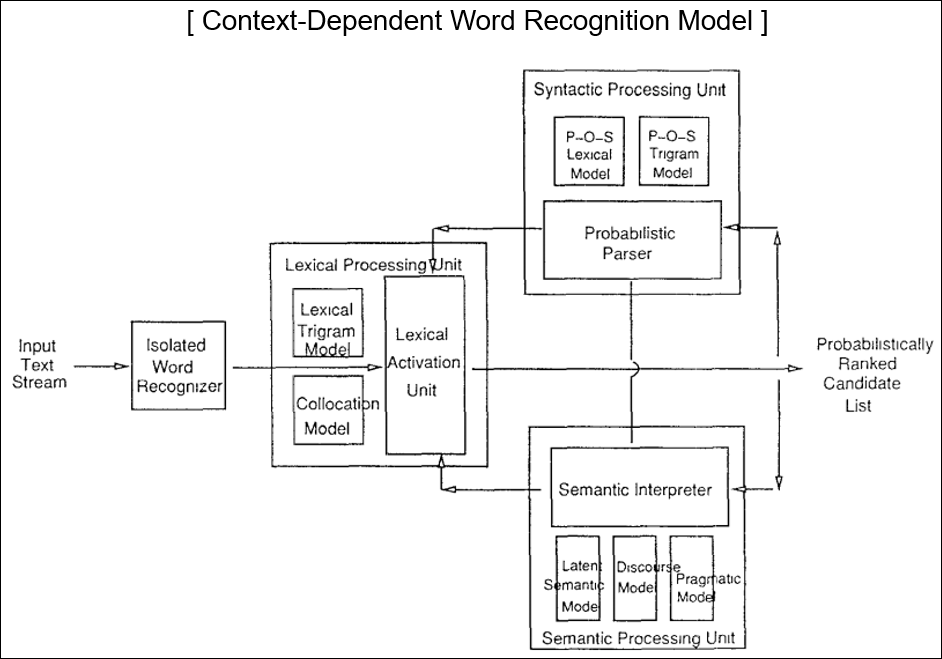
Context-Dependent Word Correction
- Context-dependent word correction = correcting words based on the surrounding context
- Essentially a fancier name for a grammar checker = a mechanism which tells a user if their grammar is wrong.
- 25-40% of spelling errors are real words ( Kukichi, 1992)
Real-word error: Classification
- 5 Levels of processing constraints
- Lexical (어휘) level : Non-word error -> Isolated-word spelling correction techs.
- Syntactic (구문) level : The study was conducted be XYZ Marketing Research
- Semantic (의미) level: see you in five minuets
- Discourse (담화) structure level: Iris flowers have four parts: standards, petals, and falls. Pragmatic (화용) level: Has Mary registered for Intro to Communication Science yet? (where Computer was intended)
- The Other Classification
- Local syntactic errors: The study was conducted mainly be John Black.
- Global syntactic errors: I can’t pick him cup cuz he might be working late.
- Semantic errors: He is trying to fine out.
- Orthographic intrusion errors: is there a were to display your plots on a DEC workstation?
(way -> were )
NLP Prototypes for Handling Ill-Formed Input
- A parser driven NLP system: Lexicon + Grammar + Parsing Procedure

- 크게 3가지 방식
- Acceptance-based approaches
- 문법에 오류가 있더라도 의미만 맞으면 통과시킴
- Relaxation-based approaches
- 에러가 무시될 수 없음 ( EPISTLE, CRITIQUE)
- Input (non-word errors) -> Parsing procedure (real-word errors: grammar, subj.-verb, punctuation)
- Expectation-based approaches
- CASPAR, DYPAR, MULTIPAR, NOMAD
- Parsing procedure: Builds a list of expected words
- If input string is NOT in the list, it assumes an error detected
- Attempts choosing one of the expectation list.
- General techniques exists in lexical & syntactic error correction.
- BUT, techniques for processing semantic, pragmatic, and discourse level are impractical ( ~ 1992).
- Parser-Based Writing Aid Tools: CRITIQUE 1987( previously IBM EPISTLE 1982)
Statistically Based Error Detection and Correction Experiments
- Statistical Language Models (SLMs) : A probability distribution P(s) over strings S attempts to reflect how frequently a string S occurs as a sentence.
- Detecting real-word errors via POS bigram probabilities: UCREL CLAWS – POS bigram transition probabilities ( Dictionary Lookup -> POS bigram transition prob.)
- Improving non-word correction accuracy via word bigram probabilities
- Detecting & correcting real-word errors via Lexical Trigram Probabilities: Mays et al. 1991 – using Bayesian prob. score computation for each sentence
- Neural Networks Language Models
- SLM : explicitly represented as conditional probabilities
- NNLM : implicitly represented as weights in the nets
Future Directions – Note that this is a 1992 paper!!!