개요
Fast phrase querying with Combined Indexes 논문을 읽고 내용을 요약하여 정리한다.
요약
이 논문에서는 어떻게 phrase 쿼리가 효율적으로 낮은 디스크 오버헤드를 가지고 처리하는지 고민하였다. 논문 저자들의 이전 연구결과는 phrase 쿼리가 nextword index를 통해서 아주 빠르게 처리될 수 있다는 것을 증명하였는다. 하지만 인덱스 크기가 일반 역인덱스 대비 2배 커지게 된다. 대안으로, 특별한 목적의 phrase index가 쓰여질 수 있지만 모든 phrase에 대해 적용하기는 불가능하다. 논문에서 제안하는바는 nextword index와 phrase index를 역색인과 조합하여 이 문제를 해결하는 것이다. 논문의 실험결과에 따르면 부분 nextword, 부분 phrase index, 전체 역인덱스의 조합은 phrase 쿼리 처리에 있어 역색인 만으로 처리했을때 대비 1/4로 시간이 단축되는것을 확인했다. 또한 디스크 공간은 26% 늘어났다. (필자 주: 디스크 공간은 25% 늘어나고 쿼리 수행시간이 25%로 단축되면 해볼만한 tradeoff인것 같다.)
INTRODUCTION
- 효율적으로 phrase 쿼리를 수행할 새로운 테크닉을 탐색함
- 일반적인 수행 방법은 inverted index를 사용하는 것이다.
- phrase 쿼리의 효율을 위해 구글검색엔진만 하더라도 2002년까지 자주쓰는 단어를 금칙어로 제거해버림
- 논문저자는 이전에 nextword index(Firstword – Nextword)를 이용하여 phrase 쿼리 처리성능을 향상하였음
논문에서 제안하는 방법은 아래이다.
phrase 쿼리를 자주 쓰지 않는 단어에 대해서는 역색인을 사용한다.
가장 자주쓰는 단어에 대해서는 nextword form을 활용한다.
가장 자주쓰는 phrase에 대해서는 phrase index를 활용한다.
PROPERTIES OF QUERIES
- Excite.com (1997 ~1999) 조사결과
- 1,583,922 queries(including duplicate)
- 총 14.4%의 phrase 쿼리가 20개의 가장 자주쓰는 term 중 하나를 포함하고 있었음
- stop/ignore word는 예상치 못한 결과를 초래한다.
- 예: tower of London => tower – London
so many roads / how many roads
man in the moon / man on the moon
-> 영어에서 전치사를 생략하면 고유명사의 의미가 퇴색되거나 전치사를 포함한 의미가 누락되버릴 수 있다.
- 예: tower of London => tower – London
- 영어에서 자주쓰는 단어는 드물게 phrase 쿼리를 제거한다.
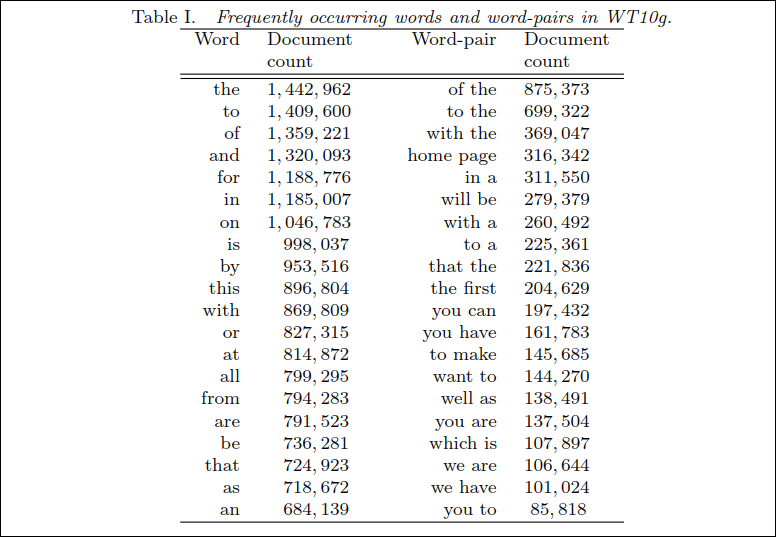
Table 1은 WT10g의 word와 word pair의 빈도이다.
역색인의 포스팅 리스트는 아래의 수식으로 나타낼 수 있다.
$d$는 문서번호, $f_{d,t}$는 문서내의 term의 빈도, $o$는 문서내에서의 위치이다.
$<d, f_{d,t}, [0_1, …, o_{f_{d,t}}]>$
예를 들어 of의 첫번재 포스팅은 <4,2,[5,34]>인데 문서번호 4번에 of가 2번 출현하고 위치는 5, 34라는 의미이다.
예를 들어 “hatful of hollow”를 구하는 과정을 살펴보면 아래와 같다.
- 가장 빈도가 적은 hateful의 위치를 살펴서 9번 문서의 4번재 위치임을 파악한다.
- 두번재로 빈도가 적은 hollow를 보면 위에서 찾은 9번 문서의 6번째 위치가 후보군이 된다.
(hateful – hollow로 -는 아직 검색 전) - 마지막으로 of를 검색해서 9번 문서의 5번째 위치임을 발견하고 결국 원하는 문서는 9임을 발견한다.
-> 이 과정은 linear merge이다.

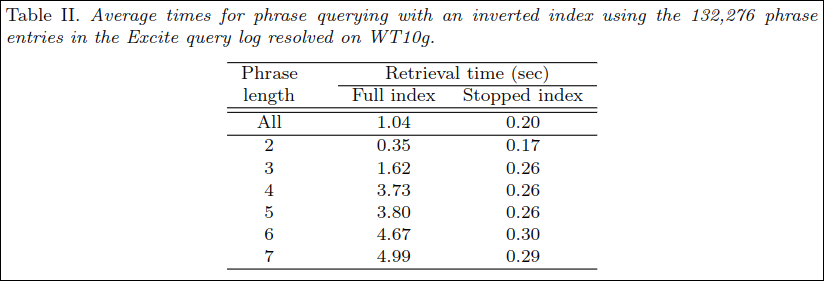
Table2는 phrase 쿼리 크기에 따른 full index와 고심해서 만든 490개 금칙어를 적용한 stopped index의 성능 비교이다.
PHRASE INDEXES
- 정의
- phrase index는 inverted index로써 개별 단어의 저장 대신 단어의 순서대로 사전의 item으로 구성된다.
- partial phrase index는 선택된 phrase에 대해서 색인을 생성하고 이러한 phrase를 포함한 쿼리가 들어왔을때 효율적으로 응답한다.
- Partial phrase index
- partial phrase index는 exact match로 쿼리에 응답한다.
- partial phrase index는 자주쓰는 쿼리나 다른 접근법으로 풀기 힘든 쿼리에 대해 최고의 계산 효율성이 달성 가능하다.
- partial phrase index의 유용성은 예상되는 쿼리를 성공적으로 예측하고 미리 저장하는데 달려있다.
- 하지만, 긴 기간과 제한된 메모리에서 유입되는 쿼리는 LRU나 LFU로 사용된 쿼리에 따라 사전을 업데이트할 필요가 있다.
- 필자의 해석에 의하면 결국 2단어 이상으로 구성된 phrase 쿼리를 아예 쿼리 통채로 캐시해버리는 방법이다. 당연히 성능은 이것보다 좋을수 없겠지만 캐시 Hit 커버리지가 중요할듯 하다.
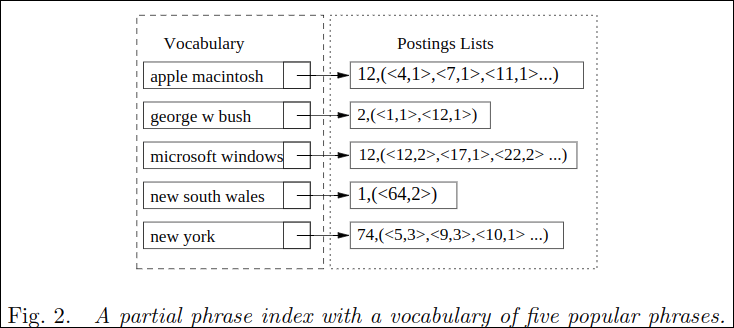
Fig. 2는 5개의 인기있는 phrase에 대한 partial phrase index의 구조이다. vocabulary만 phrase로 바뀌었지 역색인과 구조가 동일하다.
Nextword indexes
- 효율적으로 추가적인 메모리 공간 오버헤드 없이 특별한 목적의 structure를 만든것이 nextword index이다. 이는 단어의 pair를 처리하는데 속도를 증가시킨다.
- 추가로, phrase 쿼리는 2단어를 넘을수 없는 제약이 있어 phrase 쿼리는 단어의 pair로 분해될 수 있다. 나중에 살펴보겠지만 이것을 통해 nextword index는 phrase 쿼리의 단어수에 관계없이 색인조회가 가능하다.
- Spink et al. [2001]이 제안한 것은 쿼리가 ranked query로 입력되었더라도 대부분의 두 단어의 쿼리는 phrase 쿼리로 다루어져야 한다는 것이다. 또한 논문저자는 nextword index를 통해서 빠르게 phrase 쿼리가 처리 가능하다고 얘기하고 있다.
- phrase 쿼리를 처리하는 2가지 접근법은 상호보완적인 장점이 있다. 이 둘의 강점을 조합하는 것은 매력적이다. 이를 뒤 섹션에서 살펴본다.
Fig. 3은 nextword index의 구조를 보여준다. 예를 들어 “hatful of”라면 사전에서 firstword인 hatful, 그다음 nextword인 of를 찾고 이를 역색인 구조인 포스팅 리스트로 찾을 수 있다.
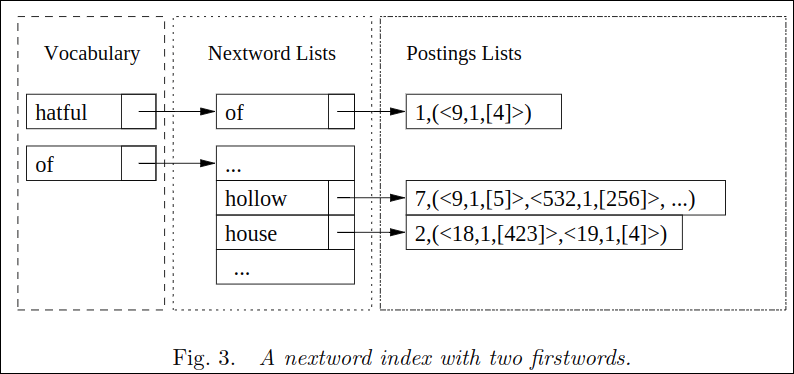
nextword index 구조는 Compaction Techniques for Nextword Indexes 논문을 참고하면 아래와 같다.
- 디스크에는 메모리에는 first word dictionary와 term frequency만 관리한다.
- 디스크에는 next word 리스트와 그들의 포스팅 리스트가 들어가 있다.
- 포스팅 리스트에 $o$의 개념은 Fig 2.와 같은 “the first time the red dog saw the red cat”으로 시작하는 문서가 있다면 offset은 그림과 같을 것이다.
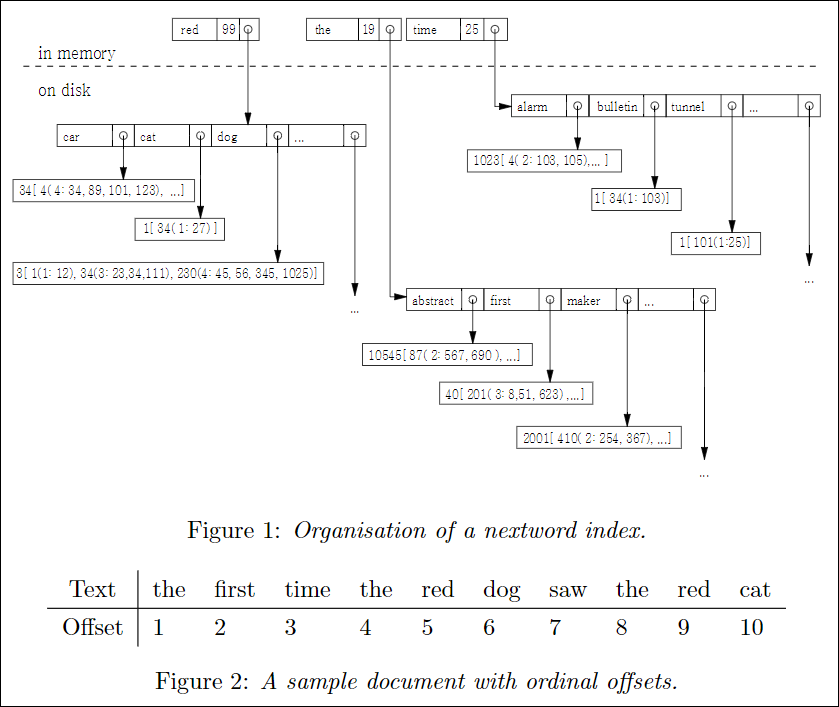
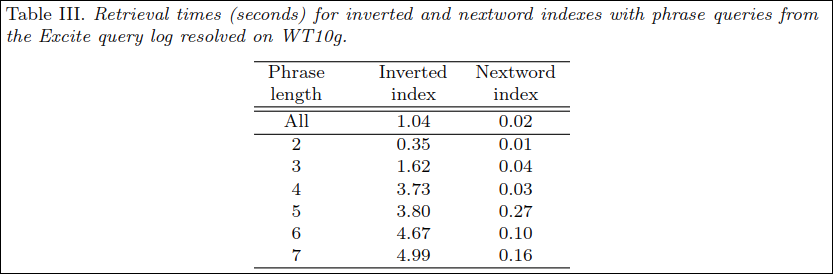
Table III는 phrase 쿼리 길이에 따른 inverted index와 nextword index의 성능차이이다.
COMBINED QUERY EVALUATION
- 따라서 위의 2가지 접근법을 조합하여 nextword index와 partial phrase index의 속도향상을 활용하여 compact inverted index를 생성한다.
- 2개를 조합하는 다른 방법은 아래와 같은데 공통된 목표는 작은 partial phrase나 partial nextword index를 생성하여 이를 조합하여 inverted index를 만드는 것이다. nextword와 phrase index는 주장컨데 partial이어야 하는데 이유는 특정 쿼리는 inverted index로 효율적으로 처리 가능하기 때문이다.
Combined inverted and nextword indexes
- 논문에서 제안하는 방식은 자주쓰는 단어에 대해서는 partial nextword index를 사용하고 나머지는 역색인을 사용하게끔 새로운 index structure를 만드는 것이다.
- 이를 Combined inverted and phrase indexes라고 부른다.
Fig. 4는 inverted index와 partial nextword index를 조합한 색인이다.
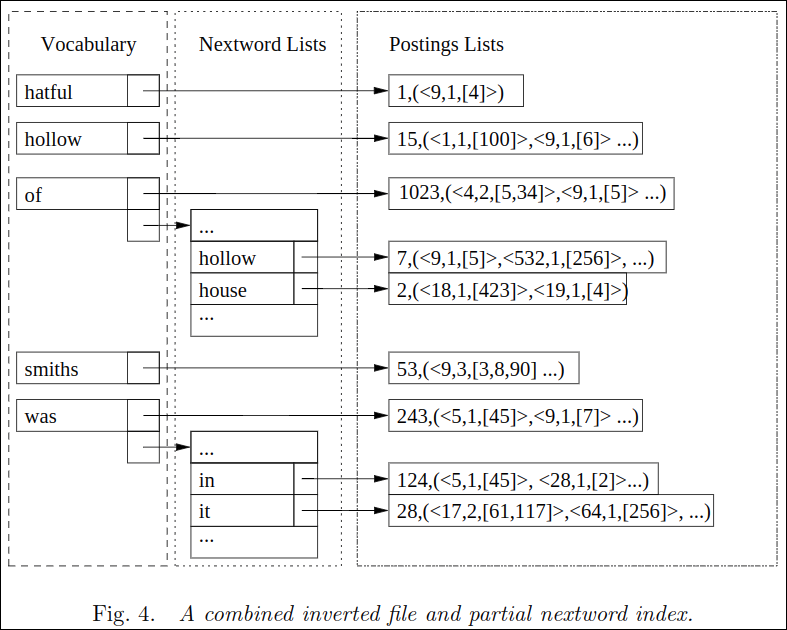
Combined inverted and phrase indexes
- 논문에서 제안하는 2번째 조합은 자주쓰는 phrase에 대해서는 partial phrase index로 수행해보고 안되면 역색인을 사용하는 방법이다.
- 이렇게 조합하여 생성된 index를 이용하여 역색인과 partial phrase index 둘로 부터 포스팅 리스트를 처리한다.
Three-way index combination
- 끝으로 3번째 조합된 색인은 partial nextword, partial phrase, 완전한 inverted index를 조합하는 것이다.
- 이전에 언급한것처럼 논문에서 주장컨데 이 조합은 상당한 장점을 얻을 수 있다는 것이다: partial nextword index는 자주쓰는 단어에 대해 단어 쌍을 처리하는 속도를 향상할 수 있다. partial phrase index는 자주쓰는 phrase 쿼리를 처리할 수 있는데 이 쿼리는 자주쓰는 단어를 보통 포함하지 않는다. 그리고 역색인은 나머지 쿼리를 처리한다.
- 필자가 해석한 의미는 예를 들어 자주쓰는 단어가 영어의 전치사로만 구성된다면
nextword index로는 “school of rock”과 같이 자주쓰는 school이란 단어와 전치사 of를 포함한 phrase를 잘 찾을 수 있고 partial phrase index로는 “new york city”와 같이 흔하지 않은 단어라도 자주 (검색이 된다고 가정) 쓰는 phrase를 빠르게 조회할 수 있다. 이외의 나머지 케이스는 역색인을 사용해서 기존에 하던대로 linear merge를 수행한다.
알고리즘은 아래와 같이 나타낼 수 있다.
- phrase query가 완전히 일치하는 phrase index가 있는지 확인한다.
- 만약 발견되면 포스팅리스트를 조회하여 문서를 fetch한다.
- 그렇지않으면 Combined inverted and nextword indexes(위에 기술)를 사용하여 문서를 fetch한다.
EXPERIMENTAL RESULTS
- solid line으로 보듯이 phrase 쿼리 수행는 기존 역색인 구조대비 200MB의 추가 용량대비 드라마틱한 성능향상이 있다.
- 논문에서 기대하는 것은 위의 관측처럼 짧은 쿼리에 대해서는 쿼리 시간이 효율적으로 향상하는 것이다.
(긴 쿼리는 해당 없음)
Table 4는 first word의 크기에 따른 디스크와 메모리의 오버헤드를 보여준다. 디스크는 퍼센트를 보면 된다. 192개 정도 쓰면 약 8.23% 정도 증가한다는 뜻이다.
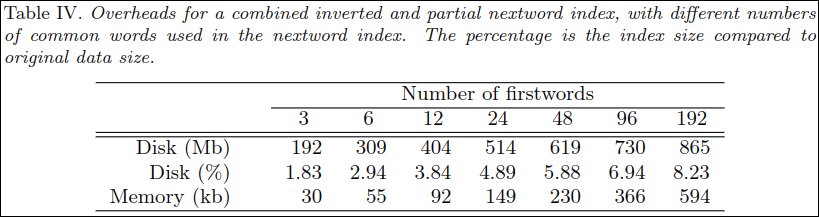
Fig. 5가 설명하는 것은 Combined Index의 오버헤드(용량) 대비 phrase query length(n)에 따른 쿼리 성능을 의미한다. 그림에서 보듯이 200MB의 오버헤드만으로도 상당한 성능향상이 있음을 확인 할 수 있다.
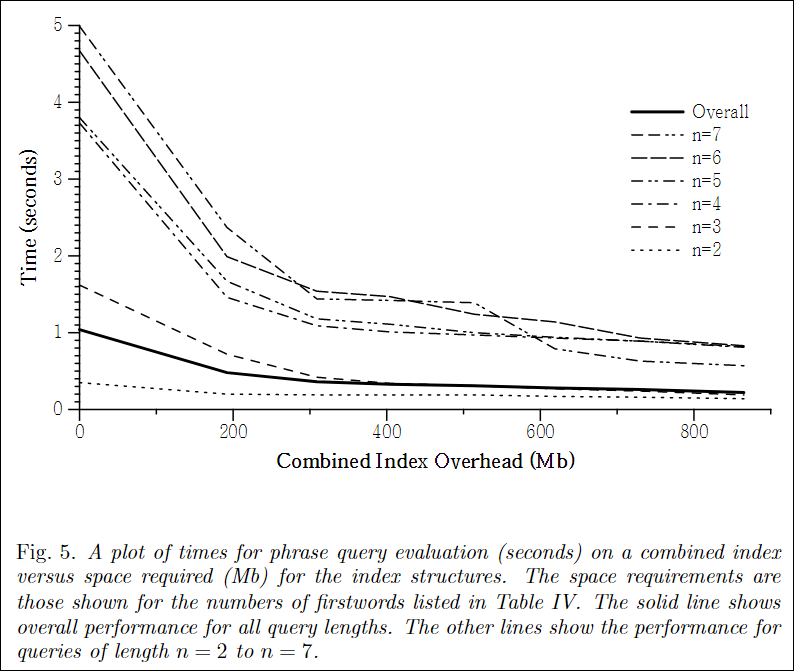
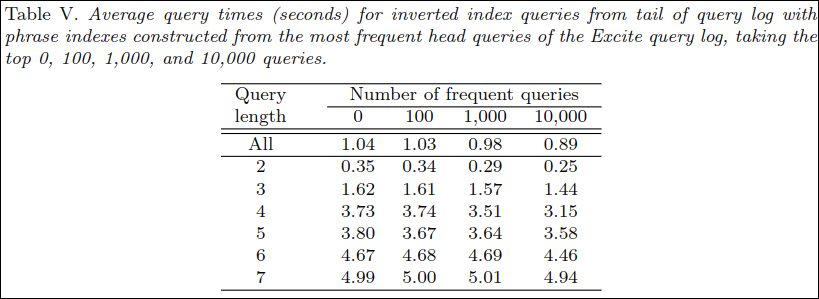
Table 5는 query lenght에 따라 쿼리 빈도를 0/100/1000/10000만큼의 phrase query index를 보유하고 있을때의 평균 쿼리 성능이다.
CONCLUSIONS
- disk 가용량에 따라 논문의 솔루션은 phrase 쿼리 수행의 평균시간을 stopping-based 접근법 대비 비슷하거나 감소킨다.
- 대용량의 완전한 nextword index는 phrase 쿼리 수행을 역색인 대비 50배, stopping-based 대비 10배 향상시킨다.
- 더 실용적으로, 논문의 제안은 partial phrase, partial nextword, full inverted index를 조합하면 적은 디스크 오버헤드 대비 높은 성능향상을 이룰 수 있다는 것이다.
- 앞으로의 연구는, 논문은 nextword list를 표현하는 구조에 대해 연구를 진행하려 한다. 큰 쿼리 로그가 가능해짐에 따라, 논문은 자주쓰는 phrase를 선택하여 partial phrase index를 준비하는 것과 이 쿼리가 빈번해지지 않음에 ㄸ라 제거하는 것을 연구중이다.
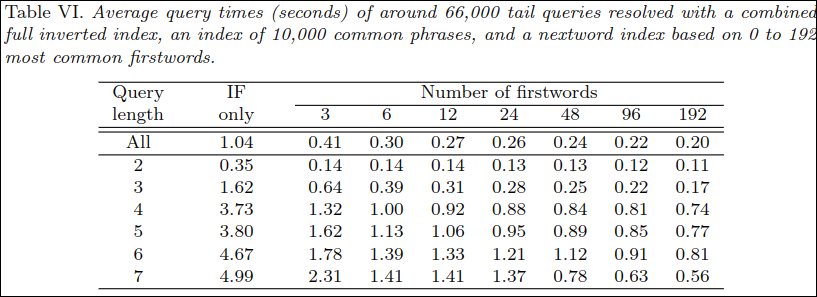
테이블 6은 query length에 따라 성능을 측정하는데 first word수를 달리하며 측정한다. 또한 common phrase는 가장 빈번한 1만개를 적용한다. 평균적으로 firstword수에 따라 쿼리 성능은 20%~80%의 성능향상이 있었다.
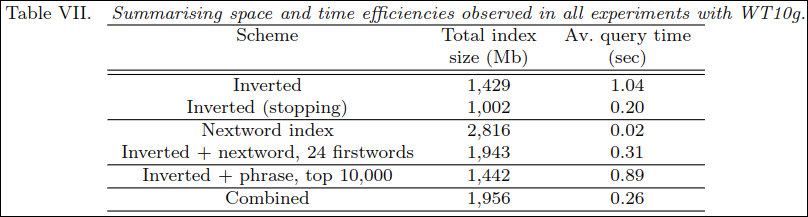
테이블 7은 각 색인 조합마다 차지하는 용량과 쿼리 시간을 나타낸다. Combined의 경우 늘어난 용량대비 쿼리시간이 확 줄어든것을 확인 할 수 있다.