Slide
SlideShare에 올려놓은 슬라이드 버전은 아래와 같습니다.
Content
- Linearly non-separable data
- Supervised Learning
- Gradient Descent Algorithm
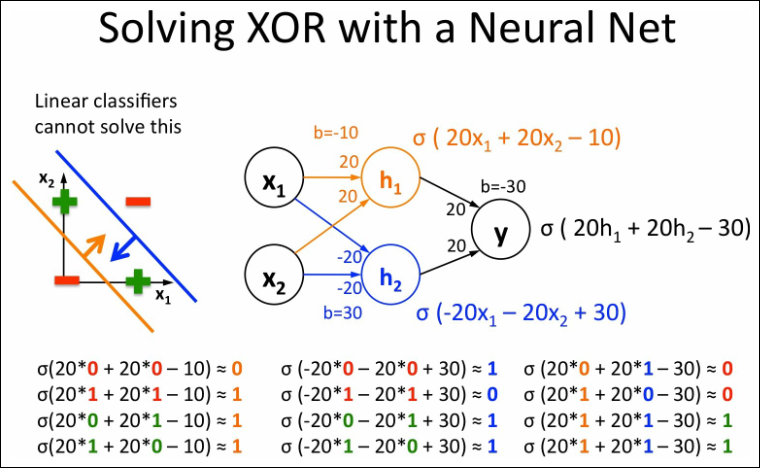
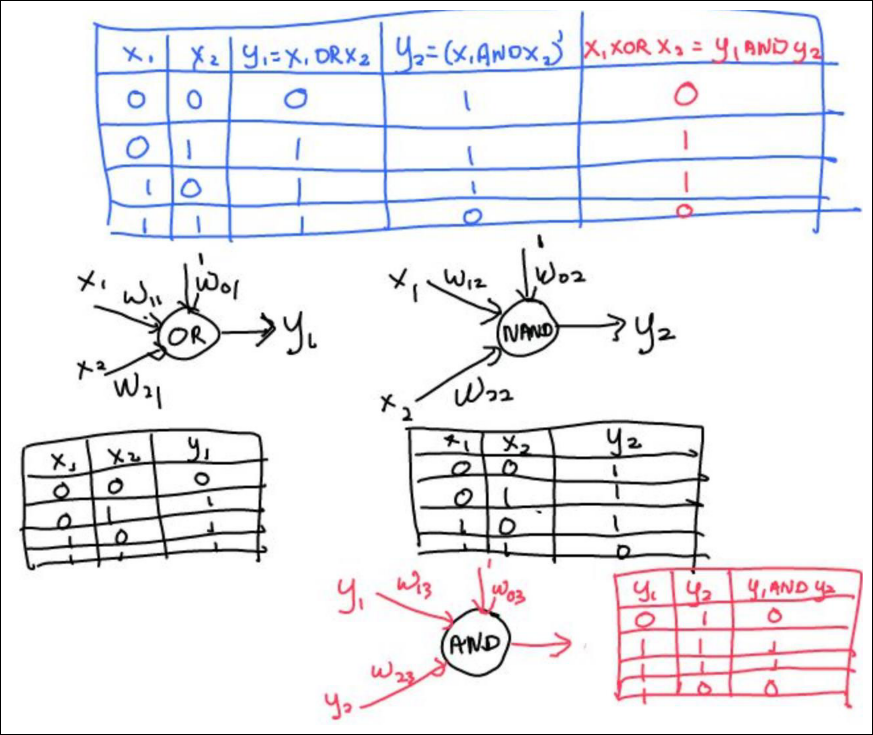
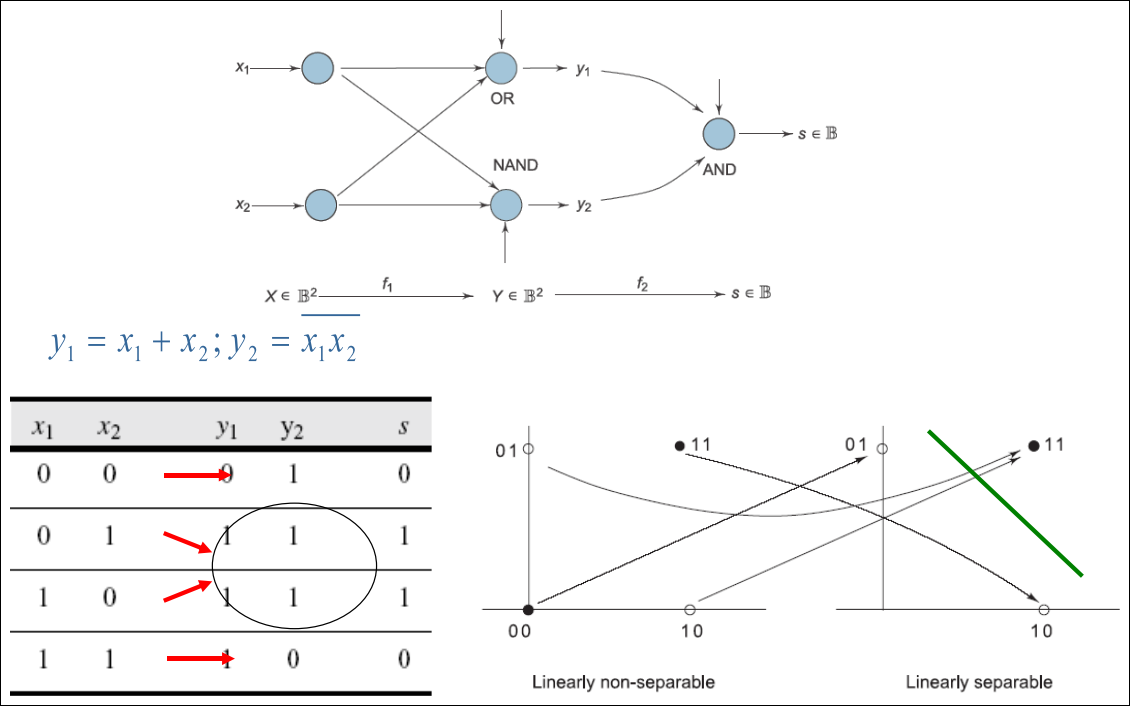
XOR is Not Linearly Separable
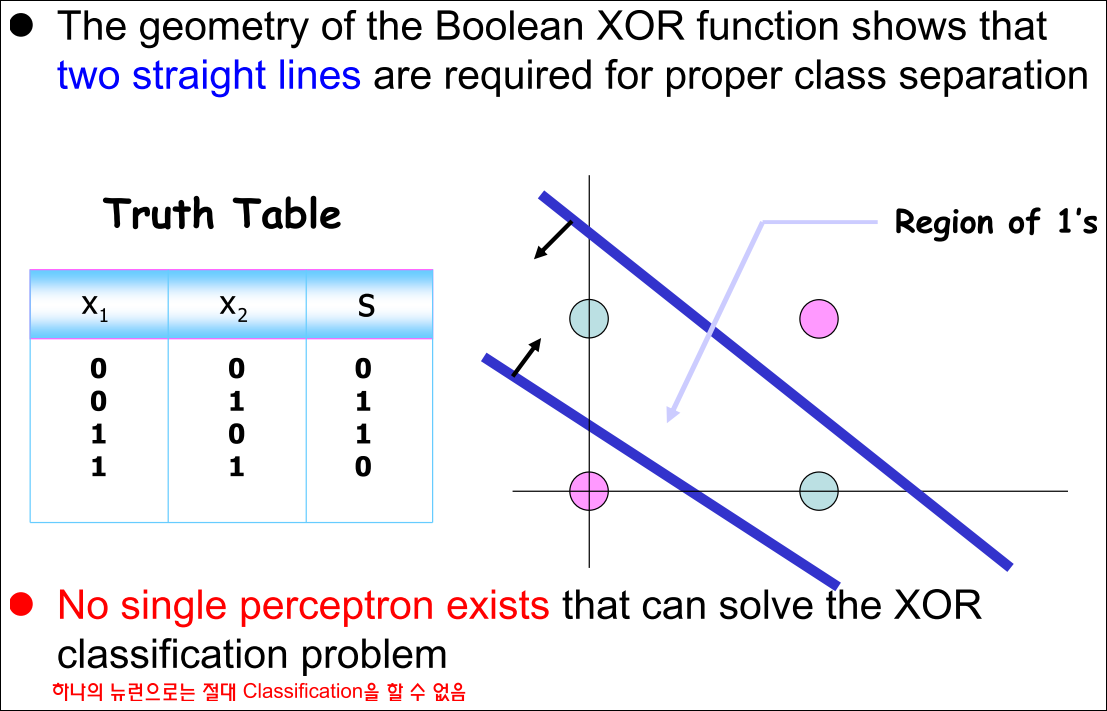
Three Perceptrons Are Required
- 2개의 뉴런이 hyperplane을 만들어 내고 나머지 한 뉴런이 2개의 hyperplane을 연결
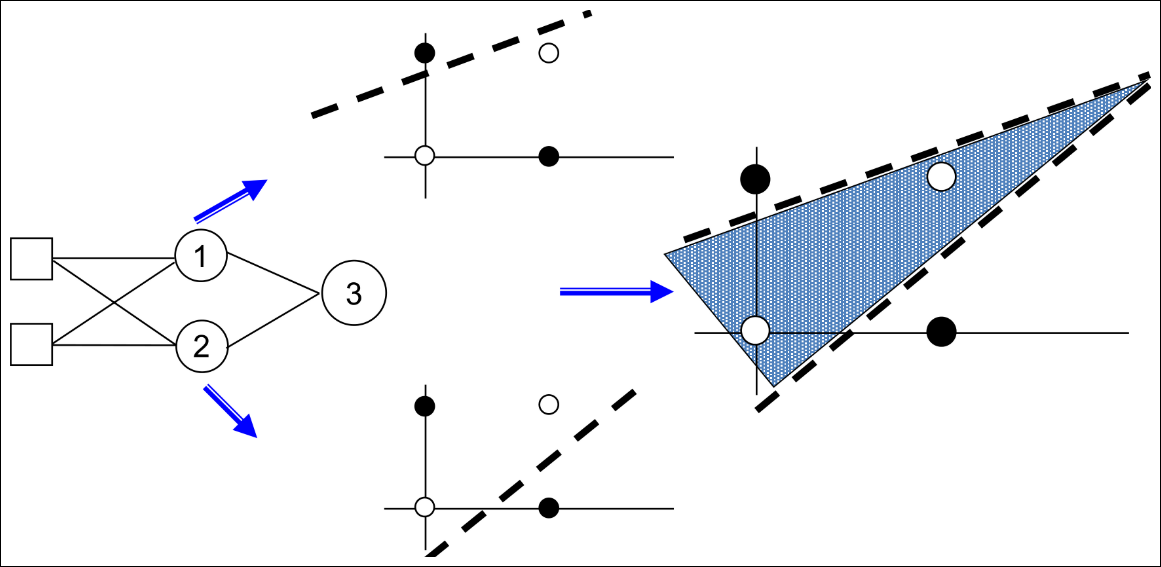
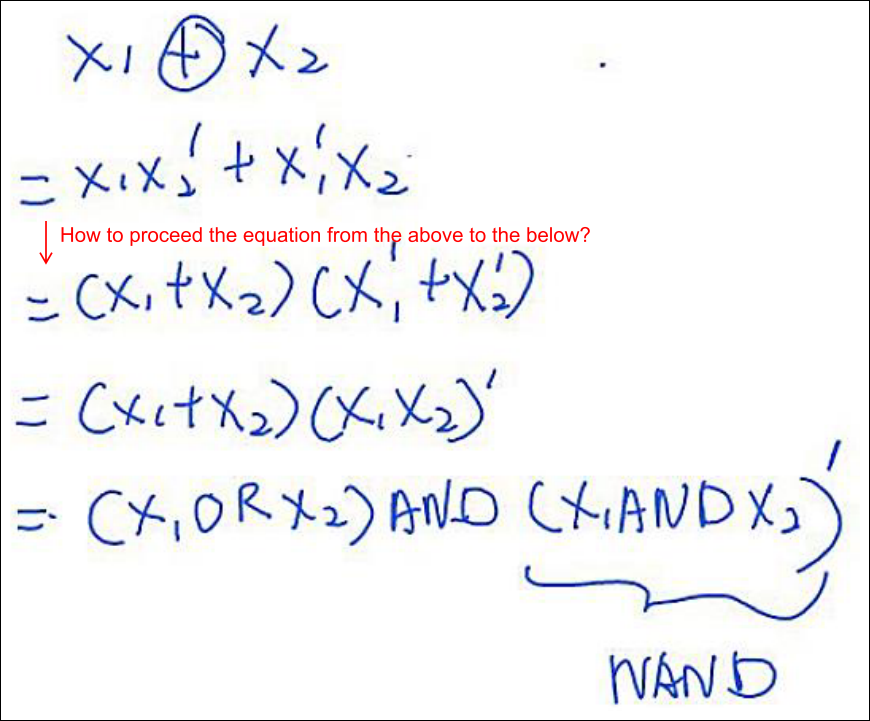
Network of Perceptrons to solve XOR (1/2)
Interpretation
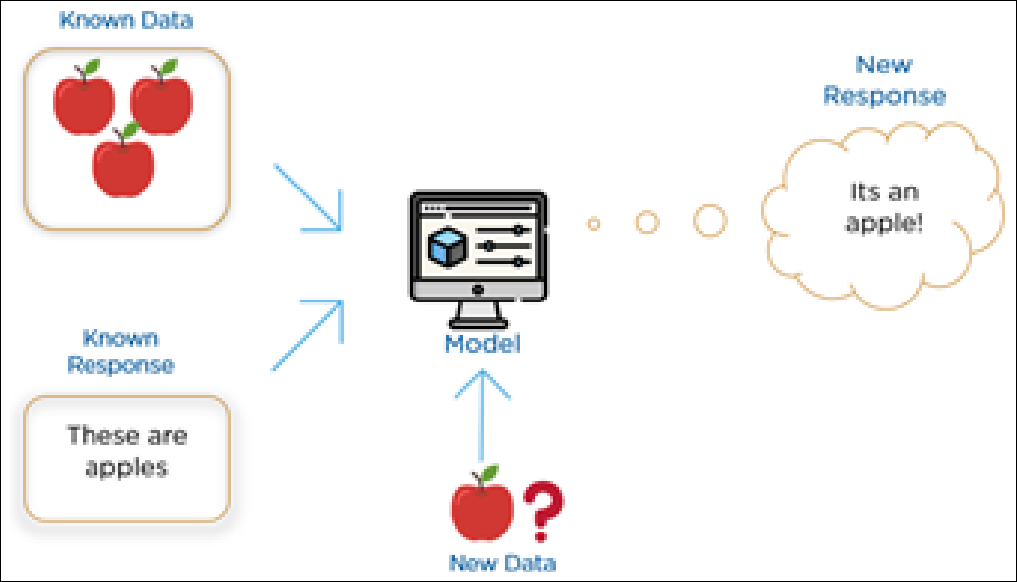
Supervised Learning
Main Idea
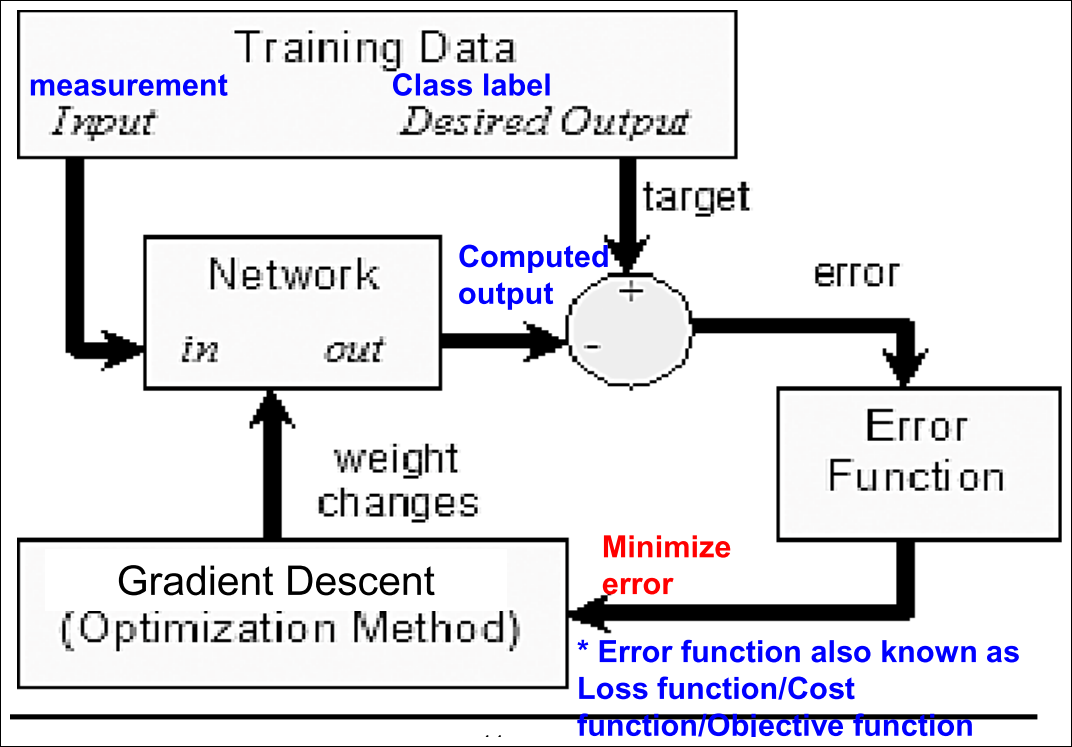
Gradient Descent Algorithms
- Close form solution
- Batch Gradient Descent (BGD)
- Stochastic Gradient Descent (SGD)
- Mini-batch Gradient Descent
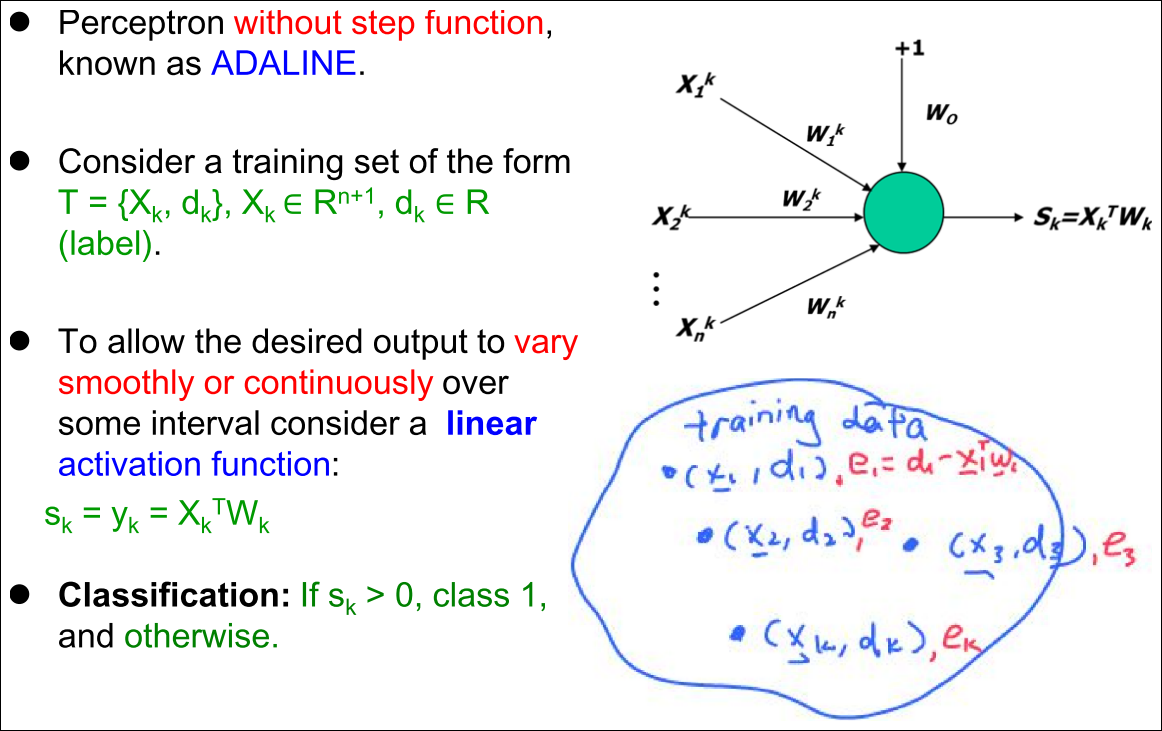
Perceptron without Step Activation Function
Mean Squared Error (MSE)

Vectorization (1/2)

Vectorization (2/2)

Our problem…
- 에러를 최소화하는 Wk를 찾는 것
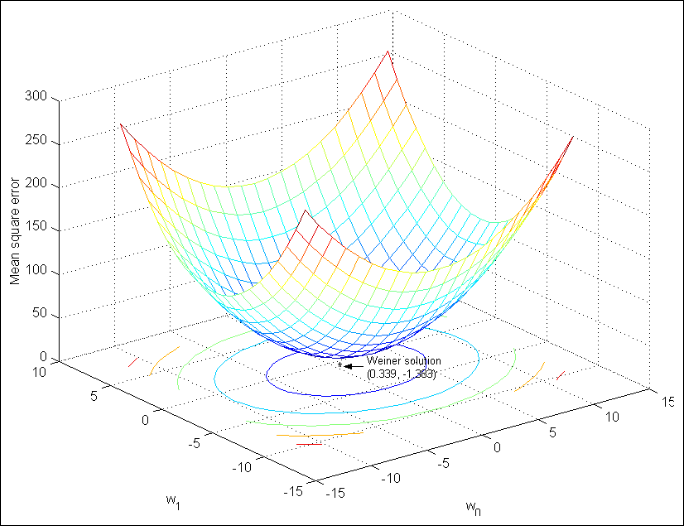
Close Form Solution
Finding the Minimum Error

Summary
-
Close form 솔루션은 한번에 해결책을 제시해 줌
-
단점 ?

Batch Gradient Descent (BGD)
Batch Gradient Descent (BGD)
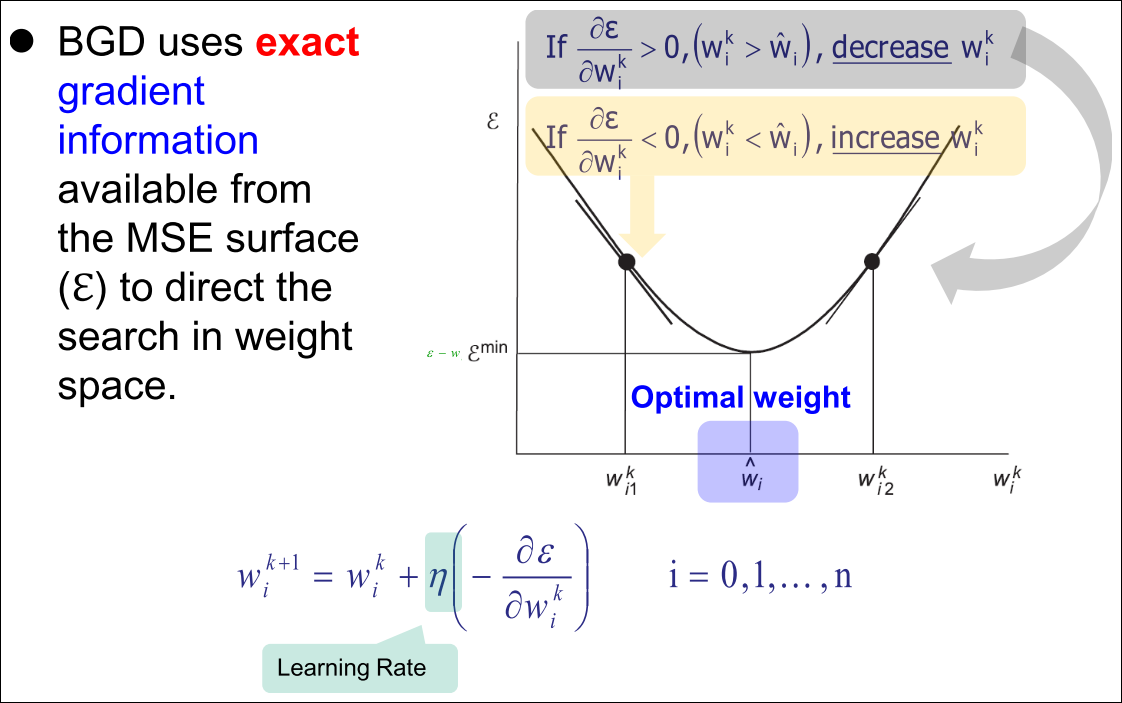
Batch Gradient Descent (BGD)
BGD Interactive Demo
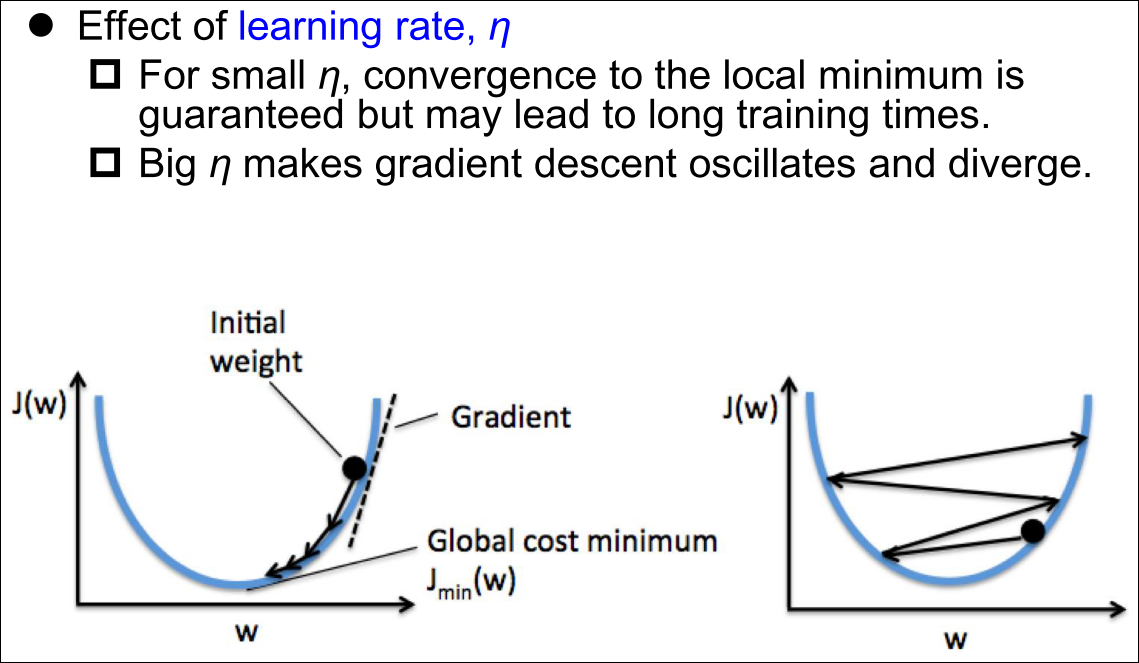
Batch Gradient Descent (BGD)


Problems of BGD
-
정확한 gradient 정보는 사전에 정의 되어야 함 즉 R과 P가 정확히 계산되어 있어야함
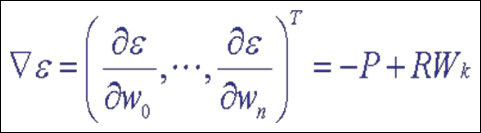
-
문제 1 : 랜덤한 스트림 패턴의 데이터가 들어오면 R과 P를 정확히 계산 못함
-
문제 2 : P와 R을 계산하는 것은 벡터 차원이 커질수록 매우 heavy함
Stochastic Gradient Descent (SGD)
Stochastic Gradient Descent
-
데이터 스트림에서 정확하게 예측하기 위해 합리적으로 긴 시간동안 평균치를 구해야 함
-
신뢰할만한 R과 P를 예측하기 위해 얼마나 많은 스트림 데이터를 흘려보내야 할까?
-
방안: SGD는 k개의 interation동안 Wk가 최적의 솔루션 Wopt에 가까워질수록 평균으로 수렴한다.
Stochastic Gradient Descent

Stochastic Gradient Descent
-
SGD의 가중치 업데이트 수식
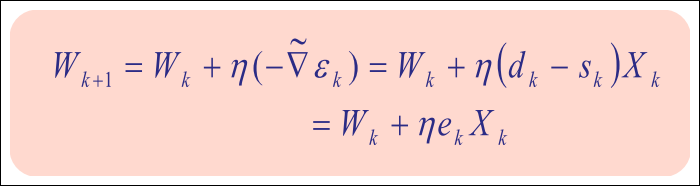
-
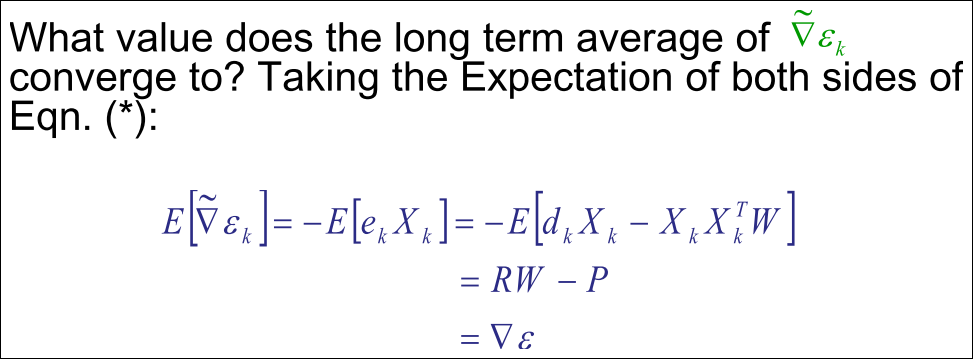
Stochastic Gradient Descent (SGD)
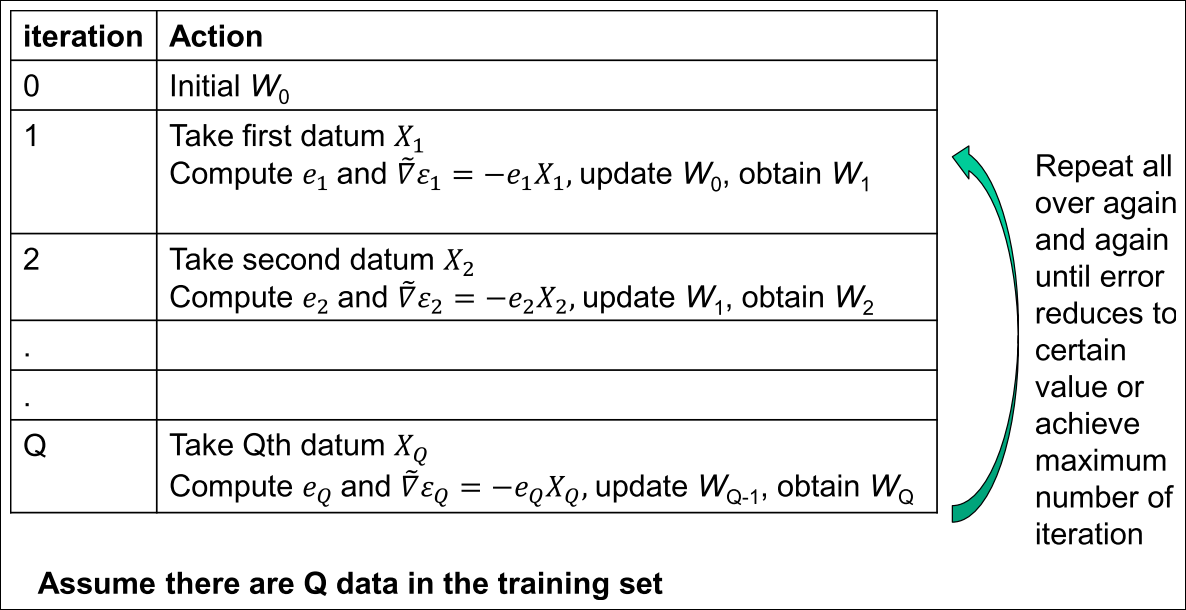
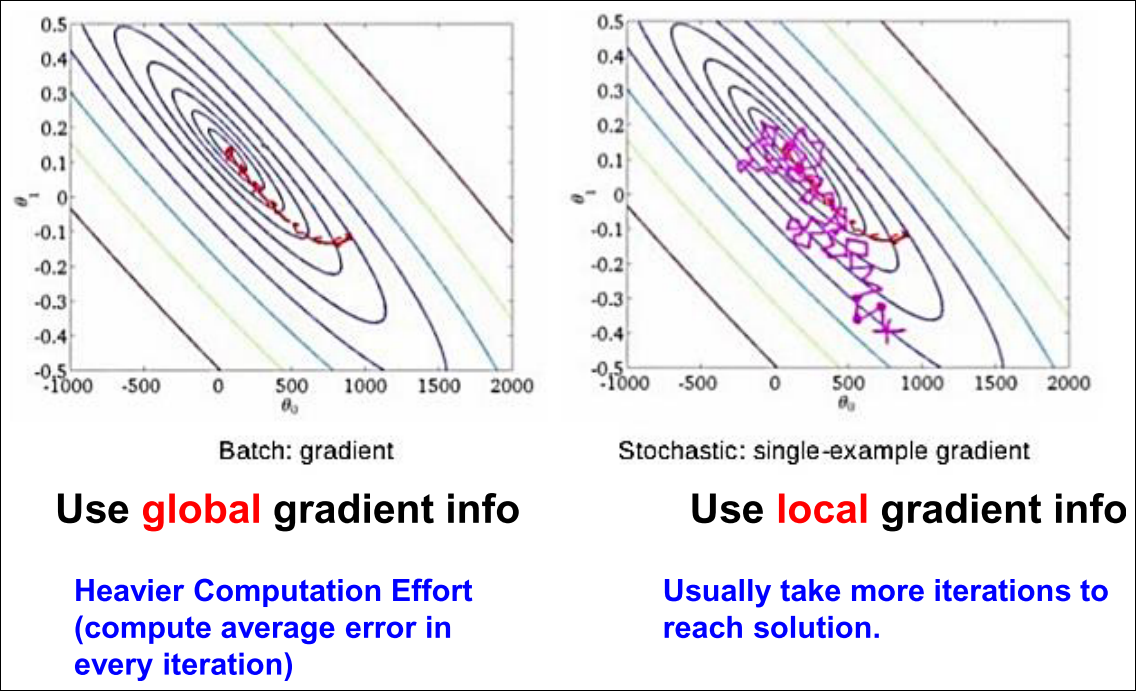
BGD vs SGD (1/2)
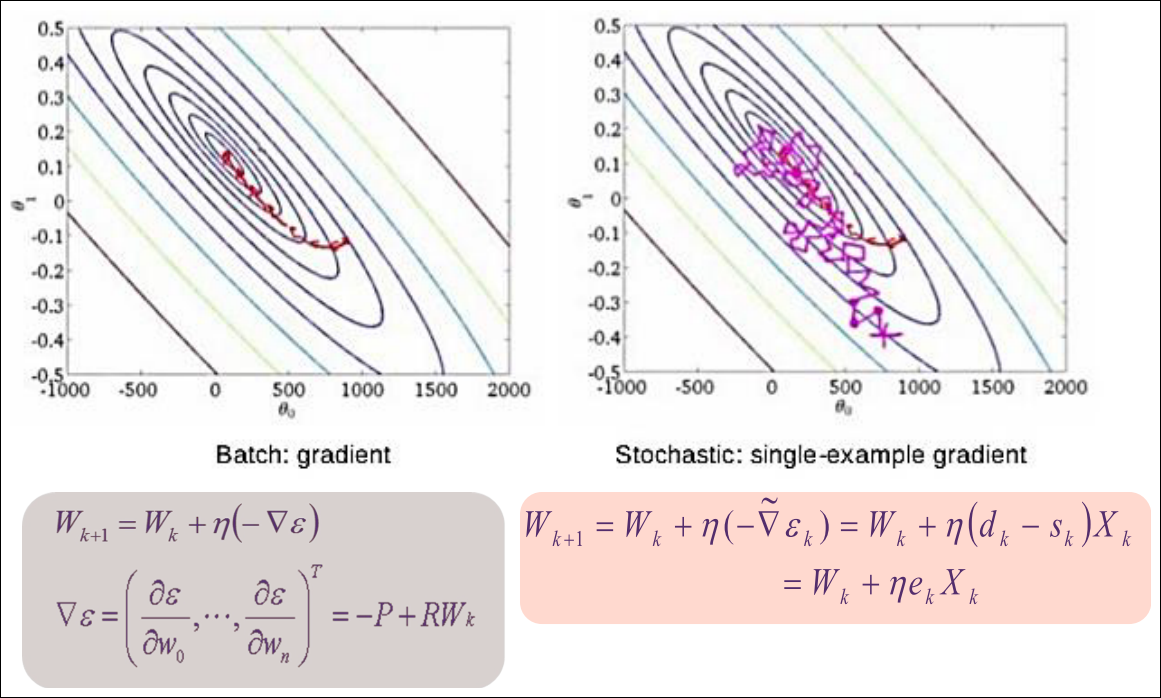
BGD vs SGD (2/2)
Mini-Batch Gradient Descent
- Batch와 SGD의 중급자 모드

Mini-Batch Gradient Descent

Summary

다음 강의
-
다중 퍼셉트론을 이용한 non-seperable 문제를 풀어보았음
-
그러나 실제로 데이터는 noisy하고 이진 분류 분제로 제한되지 않음 어떻게 더 네트워크를 발전시킬 수 있을까?
-
자동으로 학습하는 알고리즘을 배웠음 그러나 현재까지 배운 활성화 함수는 미분 불가능인데 어떻게 GD를 뉴럴넷에 적용시킬수 있을까?