슬라이드 버전 공유
Outline
- Basic Concepts
- Ordered Indices
- B+ Tree Index Files
- B- Tree Index Files
- Static Hashing
- Dynamic Hashing
- Comparison of Ordered Indexing and Hashing
- Multiple-key Access
- Bitmap Index
Basic Concepts
- 인덱싱 메카니즘은 찾는 데이터 Access 부스트
- Search Key는 파일에서 레코드를 찾는 attribute
-
인덱스 파일의 레코드는 아래와 같이 구성됨

-
인덱스 파일은 원본 파일에 비해 훨씬 작음
-
인덱스는 2가지 종류가 있음
- Ordered 인덱스 search key가 순서대로 저장
- Hash 인덱스 search key가 Bucket들에 해시함수를 이용해 분산되어 저장
Ordered Indices
-
인덱스 entry는 순차적으로 저장됨
-
만약 파일의 레코드가 순차적으로 정렬되어있다면 primary index는 search key가 순차적으로 저장된 파일임; 다른말로 clustering index라고 부름
-
실제 원본파일의 순서와 다르게 search key가 독자적인 순서를 가지는 것을 secondary index라고 부럼; 다른말로 non-clustering index라고 부름
Primary Index: Dense Index Files
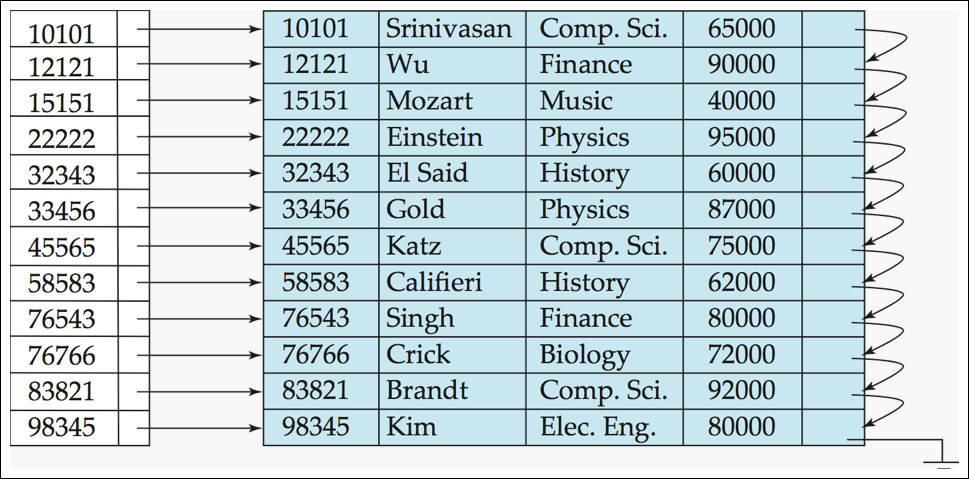
Primary Index: Sparse Index Files
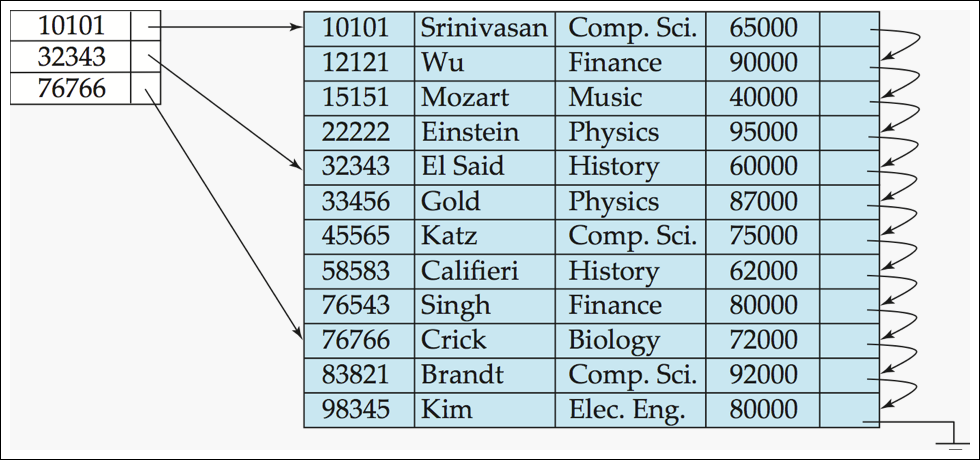
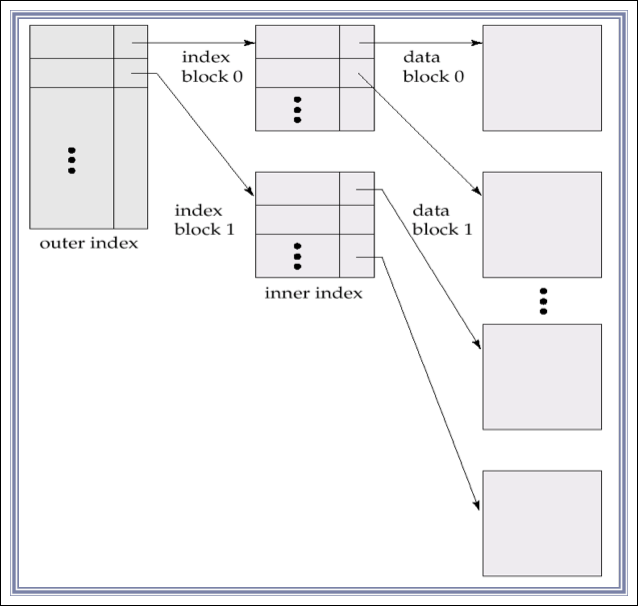
Primary Index: Multilevel Index
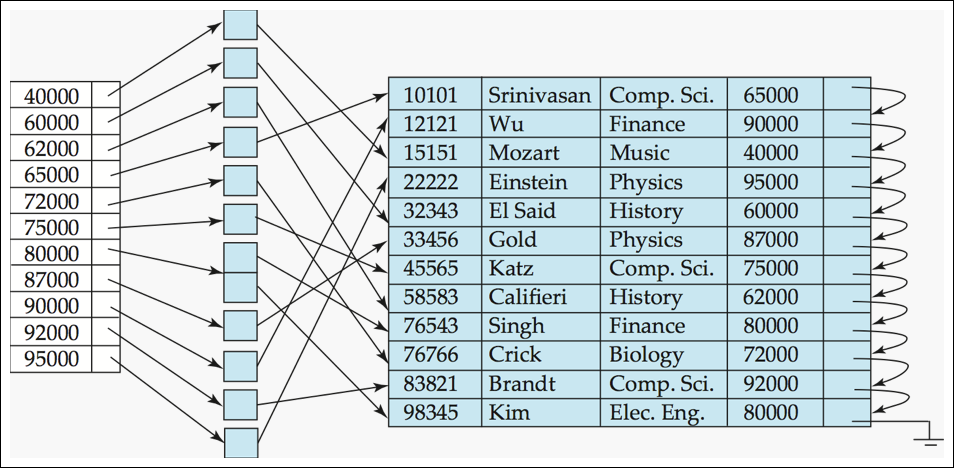
Secondary Index
B+ Tree Index Files (1/2)
- indexed sequential file은 파일이 커짐에 따라 성능이 저하됨(블럭 오버플로우, 주기적 재구성)
- b+ 트리의 장점 : 자동으로 insert/delete 시 reorganize함
- b+ 트리의 단점 : 추가적인 insert/delete 공간 오버헤드
- b+트리의 장점이 단점을 압도함
B+ Tree Index Files (2/2)
-
모든 leaf는 같은 길이를 가짐
-
루트나 리프가 아닌 노드는 n/2 ~ n 사이 자식을 가짐
-
리프 노드는 (n-1)/2 ~ n-1 개의 값을 가짐
-
루트는 반드시 2개 이상의 자식을 가져야 함
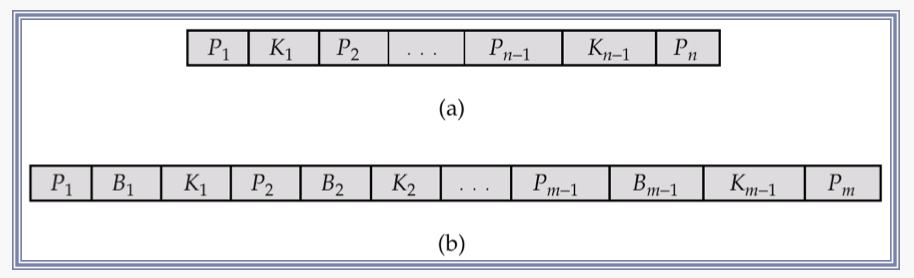
B+ Tree Node Structure
- K는 Search Key Value
- P는 포인터

- Search Key는 순차적임
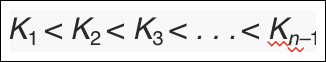
Leaf Nodes in B+ Trees
- 리프노드 구성
- 이름 순서에 따라 Search key 정렬된 예제

Non-Leaf Nodes in B+ Trees
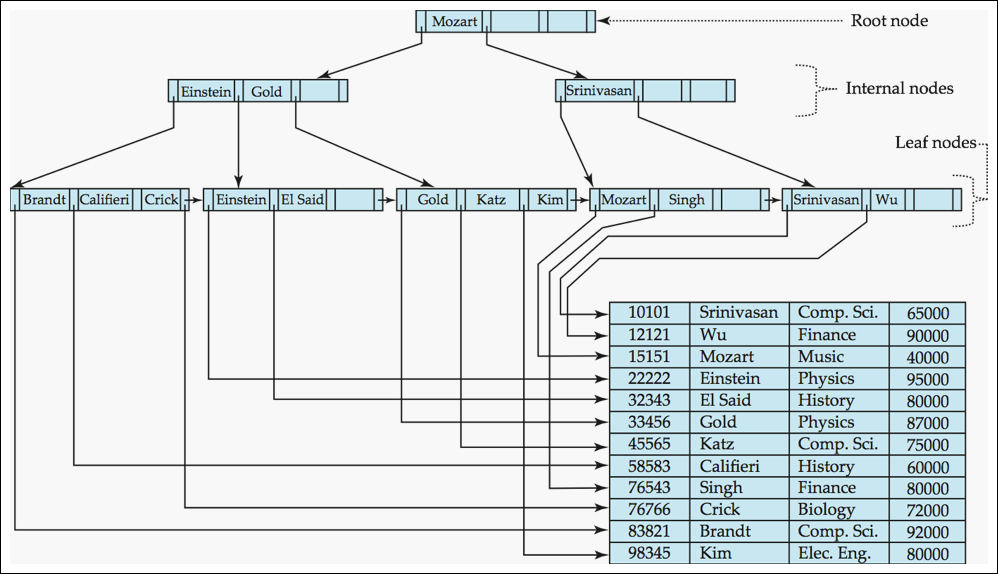
Example of a B+ Tree (1/2)
- 아래와 같이 이름 순으로 정렬되어 있음
Example of a B+ Tree (2/2)
- 아래는 n=6인 b+ 트리(Pn이 최대 6이라 생각하면 됨)
- 리프노드는 n-1/2 ~ n-1이니까 3~5의 값을 지님
- non 리프노드는 n/2 ~ n 이니까 3~6의 자식을 지님

Queries On B+-Trees
search key 값이 k인 모든 레코드를 찾아라
-
루트 노드에서 시작

-
만약 위의 포인터가 자식노드가 아니라면 위의 절차를 반복한다.
-
자식 노드에 도달하면 Ki=k라면 Pi를 따라서 레코드를 찾는다. Ki!=k라면 조건에 맞는 레코드가 없다는 뜻이다.
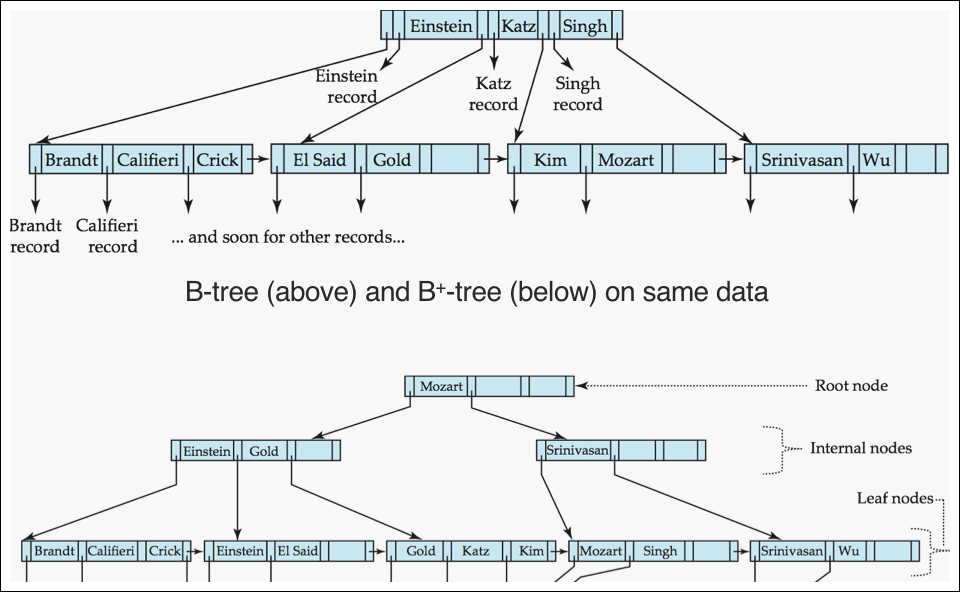
B Tree Index Files (1/3)
- B+ 트리와 유사하지만 B 트리는 search key 값이 딱 1번만 등장해야함; 중복된 key값은 삭제
B Tree Index Files (2/3)
B Tree Index Files (3/3)
- B 트리의 장점
- b+보다 더 적은 tree 노드를 가질 수 있음
- search key 값을 leaf노드까지 가지 않더라도 얻을 수 있는 확률
- B 트리의 단점
- 일찍 발견되는 Search Key 양이 적음
- non리프노드가 커지고 fan-out이 감소됨, 따라서 B+ 트리보다 depth가 깊어짐
- Insert/Delete가 B+ 트리보다 더 복잡함
- B 구현이 더 어려움
- 일반적으로 B 트리의 장점이 단점을 이기지 못함
Static Hashing
-
버킷은 하나 이상의 레코드의 단위
-
해시 함수에 의해 버킷이 구해짐
-
서로 다른 search key가 같은 버킷에 기록될 수 있음; 따라서 버킷 안에서 순차적으로 검색해야함
Hash Organization of instructor File
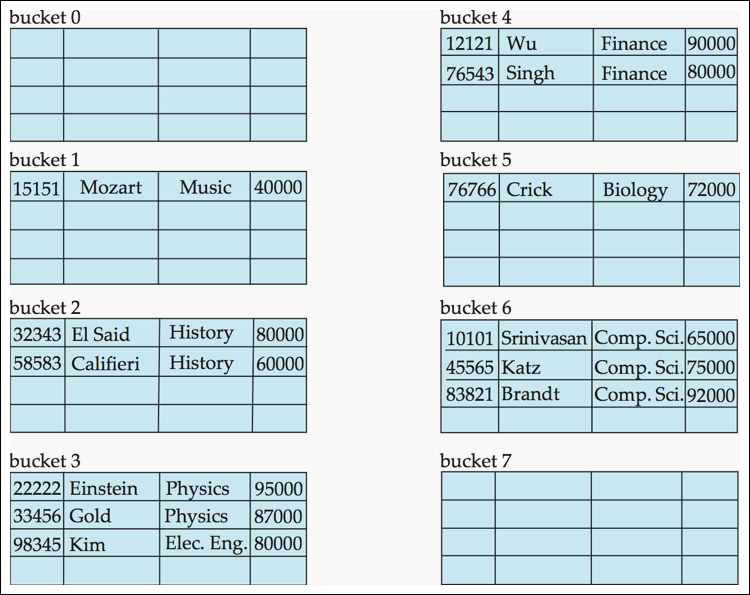
Handling of Bucket Overflows
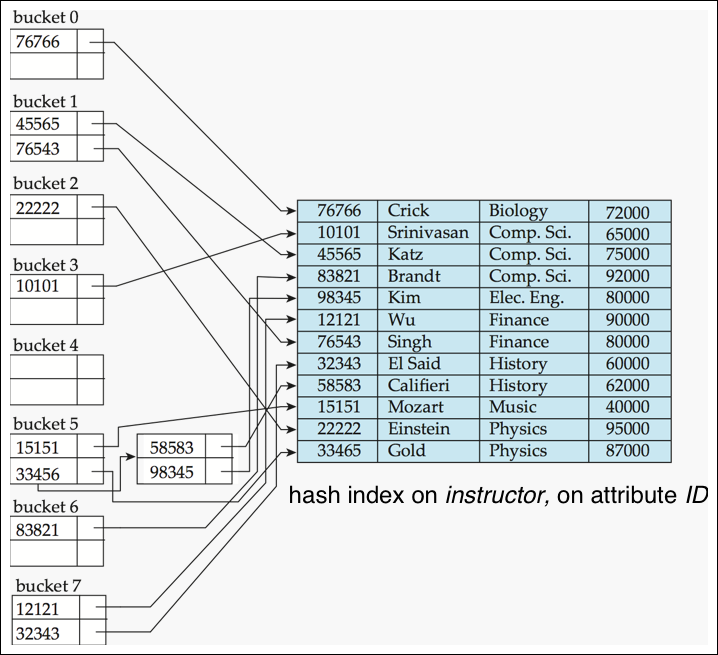
Hash Indices
- 해싱은 file 구조화에도 쓰고 색인 구조 생성에도 사용
Example of Hash Index
Deficiencies of Static Hashing
- static Hashing에서는 고정된 버킷 주소로만 맵핑함
- 시간에 따라 특정 버킷이 너무 작거나 너무 클 수 있음
- 반대로 db가 줄어들면 버킷 공간이 낭비 됨
- 대안으로 주기적으로 compaction하는것인데 비용이 비쌈
- 이러한 문제는 dynamic hashing으로 해결 가능
Dynamic Hashing
- db 크기가 늘거나 줄어는데 효과적인 방법
- 해시 함수가 dynamic하게 바꾸어줌
Extendable Hash Structure
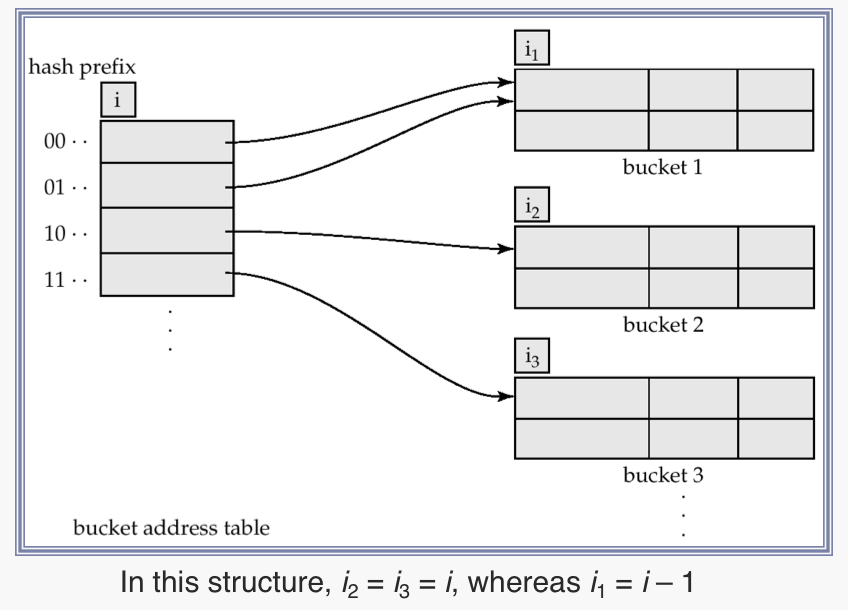
Use of Extendable Hash Structure
- 각 버킷 j는 값 ij를 저장
- search key k로 버킷을 지정하는 방법은
- compute h(k) = X
- X에서의 높은 i비트를 버킷 주소 테이블로 사용
- search key k에 insert하기
- 위와 같은 절차를 거침
- 버킷에 여유가 있으면 Insert
- 버킷에 여유가 없으면 split 이후 insert
Updates in Extendable Hash Structure (1/2)
스플릿 절차에 대해 알아보자.
- if i > ij(more than one pointer to bucket j)
- 새로운 버킷 z를 할당하고 ij와 iz를 ij + 1에 이어붙임
- 기존에 j를 가리키던 절반을 z로 옮김
- 지우고 다시 bucket j 에 기록
- k에 대한 버킷을 다시 계산하고 insert
- if i = ij ij (only one pointer to bucket j)
- i를 증가하고 bucket 주소 테이블을 2배로 만ㄷ름
- 각 엔트리를 각 버킷으로 양분함
- 버킷 주소를 재계산
Updates in Extendable Hash Structure (2/2)
삭제시 절차를 알아보자.
- 버킷을 확인하고 지움
- 만약 엔트리가 비게 되면 버킷 자체를 지움
- 버킷 병합이 가능함
- 버킷 주소 테이블의 감소도 가능함
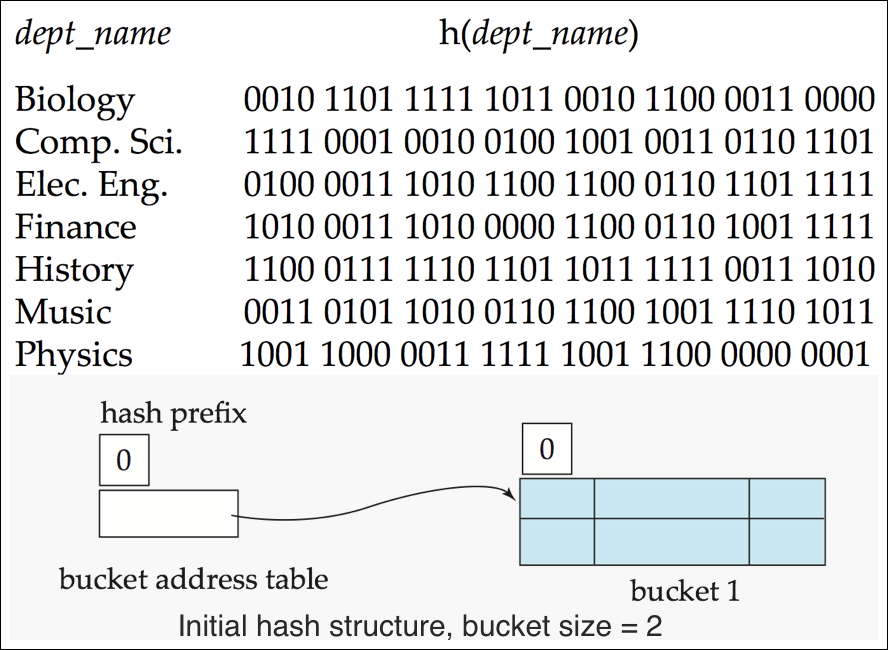
Use of Extendable Hash Structure: Example (1/7) #1
- 각 과이름이 저렇게 비트가 구성되어 있다.
- 여기서 insert를 시도하면 hash prefix도 0이고 bucket 1도 0이라 hash prefix값을 +1 한다.
Use of Extendable Hash Structure: Example (1/7) #2
Use of Extendable Hash Structure: Example (2/7)
- 3개 insert를 시도함
- music은 최상위 비트 0이니 위에 insert
- comp와 finance는 최상위 비트 1이니 밑에 insert

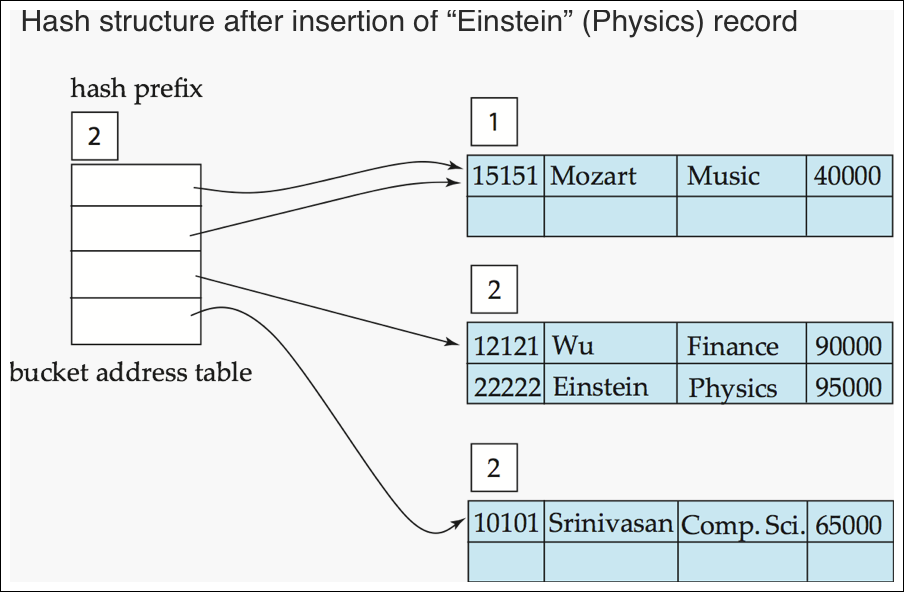
Use of Extendable Hash Structure: Example (3/7) #1
- 여기서 다시 physics insert를 시도하면 최상위 비트가 1이라 overflow
- 1번째 버킷을 쪼개고 다시 hash prefix 2로 늘임
- 관련된 버킷 계산을 다시함(music은 해당없음)
- 최상위 10 : finance, physic
- 최상위 11 : computer
Use of Extendable Hash Structure: Example (3/7) #2
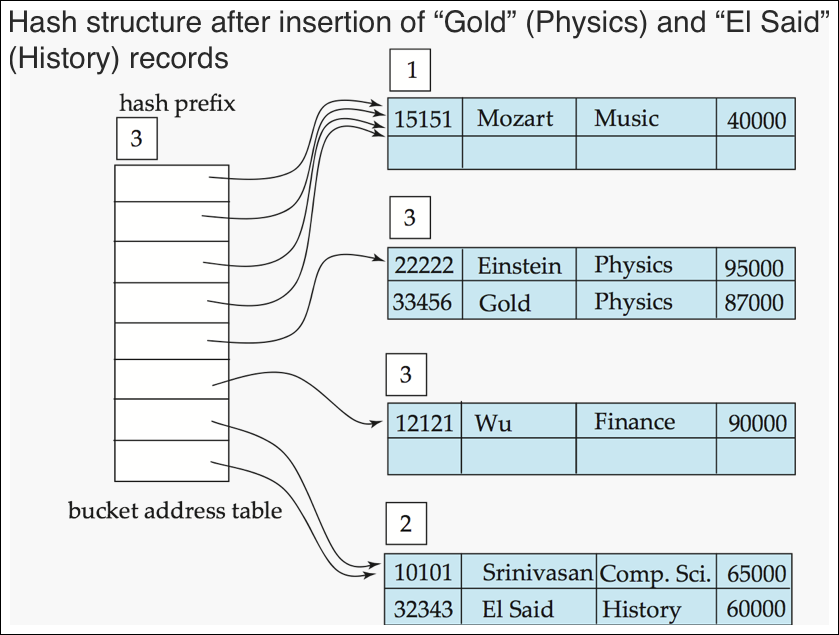
Use of Extendable Hash Structure: Example (4/7) #1
- physics insert시도 하면 10 overflow
- hash prefix 3으로 만듦
- 관련된 버킷 재계산
- 100 : physics
- 101 : finance
- history insert, 11에 속함
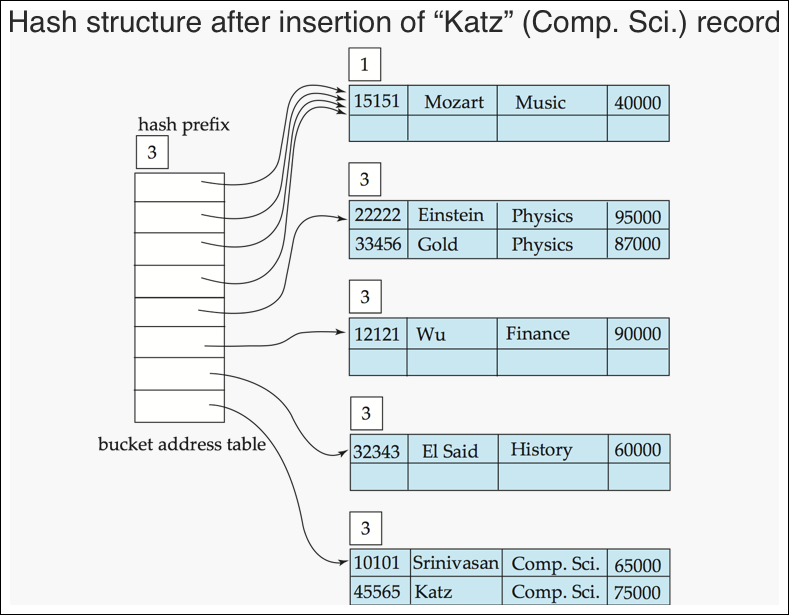
Use of Extendable Hash Structure: Example (5/7) #1
- comp insert시 overflow
- 관련 버킷 재계산
- 111 : computer
- 110 : history
Use of Extendable Hash Structure: Example (5/7) #2
Use of Extendable Hash Structure: Example (6/7)
- 11개 레코드 insert 후 결과
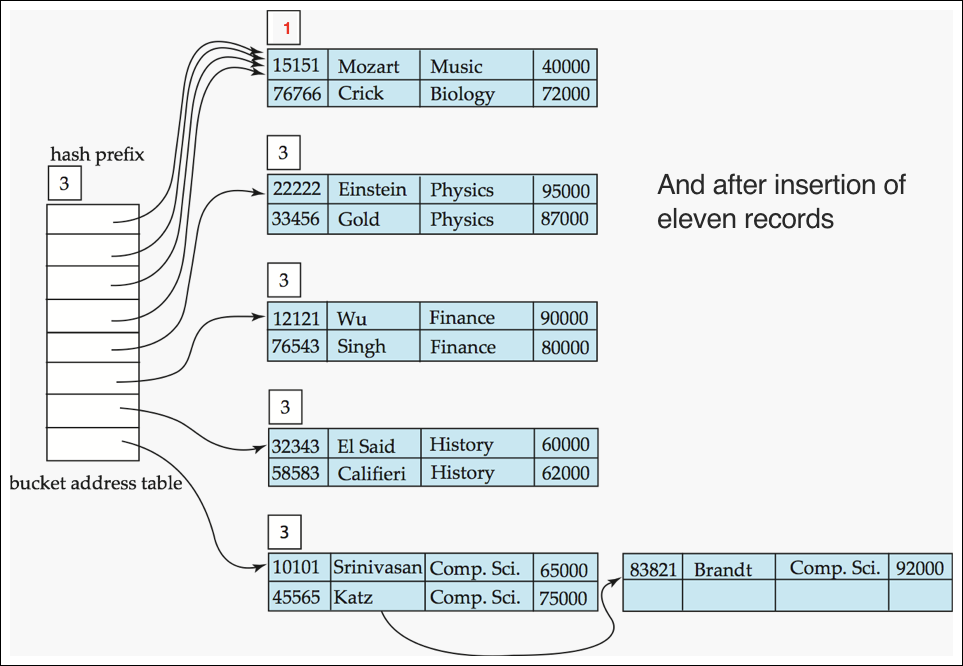
Use of Extendable Hash Structure: Example (7/7) #1
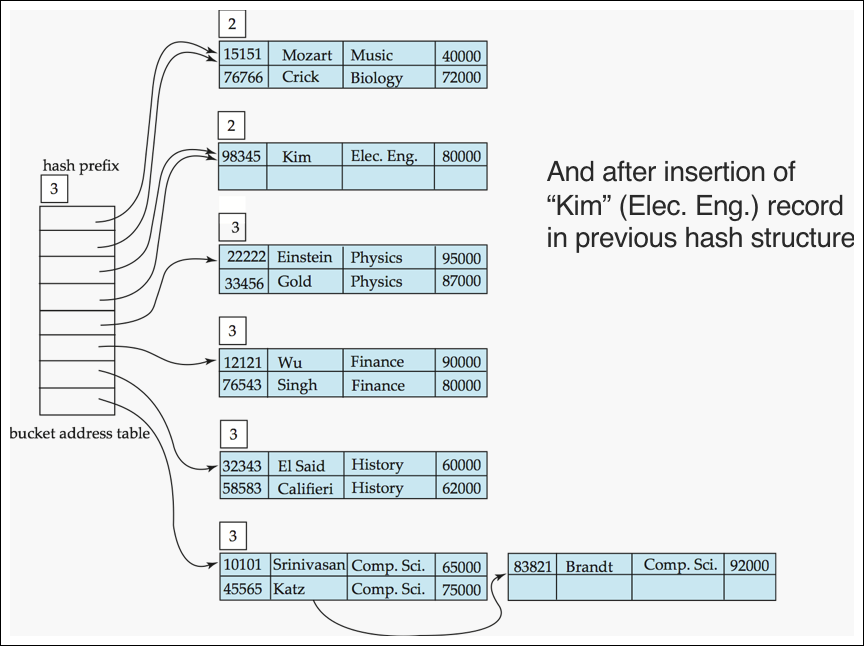
- elec insert 후 결과
Use of Extendable Hash Structure: Example (7/7) #2
Extendable Hashing vs. Other Schemes
- extendable hashing의 장점
- hash 퍼포먼스가 파일 증가에 영향을 받지 않음
- 최소한의 공간 오버헤드
- extendable hashing의 단점
- 원하는 레코드를 찾는데 추가의 level이 필요
- bucket 주소 테이블이 커질 수 있음(메모리보다 크게)
- 버킷 주소 테이블 크기의 변경은 비싼 연산임
Ordered Indexing vs. Hashing

Multiple-Key Access
Use multiple indices for certain types of queries
Possible strategies using indices on single attributes: 1. Use index on dept_name to find all instructors in the Finance department; test salary = 80000 2. Use index on salary to find all instructors with salary of $80000; test dept_name = “Finance” 3. Use dept_name index to find pointers to all records pertaining to the Finance department. Similarly use index on salary. Take intersection of both sets of pointers obtained
Indices on Multiple Attributes

Bitmap Indices
-
bitmap은 다중 key 조회를 효과적으로 처리하기 위한 타입
-
관계가 있는 레코드는 순차적이라 가정함
-
주어진 숫자 n은 n개의 레코드를 손쉽게 얻어야함
-
상대적으로 작은 카디널리티에 쓸 수 있음
-
비트맵은 비트 배열임
Use of Bitmap Indices: Example
아래와 같은 비트를 AND/OR/NOT 연산해서 검색하면 됨

Bitmap Indices
-
bitmap은 multiple attribute에 유용함
-
and/or/not 연산에 유용함
-
아래와 같은 예제가 가능
- males and L1(10010 and 10100 = 10000)
- 조건에 맞는 row수 셀 때 더 빠름
