개요
이번 포스팅에는 앞으로 배울 회귀분석 등에 필요한 가설에 대한 통계학의 기본 이론과 그래프(plot)를 그리는 방법을 알아본다.
코드중심의 설명이기 때문에 본문 보다는 코드의 주석이 집중적으로 추가되어 있으니 참고 바란다.
가설검증
통계 데이터에서 인사이트르 얻기 위해 가설을 세우는 방법을 잠깐 알아보자.
이때, 검증자가 주장하고 싶은 가설을 H1, 반대되는 가설을 H0로 세운다.
무죄추정의 원칙은 기본적으로 무죄인데 이를 반하는 강력한 증거가 나타났을때 유죄가 된다. 통계적 가설검증은 기본적으로 강력하게 H1이 참임이 입증되기 전까지는 H0를 참이라고 생각한다.
가설 이론에 대해 간단하게 살펴보자면 통계학에서 가설은 크게 2가지로 나뉠수 있는데 귀무가설과 대립가설이다.
귀무가설
위키피디아에 의한 귀무가설의 정의는 아래와 같다.
귀무가설(歸無假說, 영어: null hypothesis, 기호 H0) 또는 영가설(零假說)은 통계학에서 처음부터 버릴 것을 예상하는 가설이다. 차이가 없거나 의미있는 차이가 없는 경우의 가설이며 이것이 맞거나 맞지 않다는 통계학적 증거를 통해 증명하려는 가설이다. 예를 들어 범죄 사건에서 용의자가 있을 때 형사는 이 용의자가 범죄를 저질렀다는 추정인 대립가설을 세우게 된다. 이때 귀무가설은 용의자는 무죄라는 가설이다. 통계적인 방법으로 가설검정을 시도할 때 쓰인다. 로널드 피셔가 1966년에 정의하였다.
대립가설
위키피디아에 의한 대립가설의 정의는 아래와 같다.
가설 검정 이론에서, 대립가설(對立假說, 영어: alternative hypothesis) 또는 연구가설 또는 유지가설은 귀무가설에 대립하는 명제이다. 보통, 모집단에서 독립변수와 결과변수 사이에 어떤 특정한 관련이 있다는 꼴이다. 어떤 가능성에 대해 확률적인 가설검정을 할 때 귀무가설과 함께 사용된다. 이 가설은 귀무가설처럼 검정을 직접 수행하기는 불가능하며 귀무가설을 기각함으로써 받아들여지는 반증의 과정을 거쳐 받아들여질 수 있다.
p-value
간단히 이해하자면 p-value 값이 작으면 귀무가설(H0)가 거짓을 가능성이 높다는 것이다.
위키피디아의 정의는 아래와 같다.
통계적 가설 검정에서 유의 확률(有意確率, 영어: significance probability) 또는 p값(영어: p-value)은 귀무가설이 맞다고 가정할 때 얻은 결과보다 극단적인 결과가 실제로 관측될 확률이다. 실험의 유의확률은 실험의 표본 공간에서 정의되는 확률변수로서, 0~1 사이의 값을 가진다.
유의수준(Significance level)
위키피디아의 정의는 아래와 같다.
유의수준(significance level)은 통계적인 가설검정에서 사용되는 기준값이다. 일반적으로 유의수준은 alpha 로 표시하고 95%의 신뢰도를 기준으로 한다면 (1−0.95)인 0.05값이 유의수준 값이 된다. 가설검정의 절차에서 유의수준 값과 유의확률 값을 비교하여 통계적 유의성을 검정하게 된다.
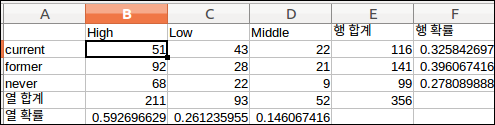
흡연자 테이블 예제로 알아보기
아래와 같이 테이블을 불러와 보자. csv파일은 github에 올려져 있다.
여기서 2가지의 변수는 사회 경제적인 수준과 또 하나는 흡연 여부이다.
- 귀무가설은 두 변수가 독립적이다는 것이다.
- 대립 가설은 두 변수가 독립적이지 않다는 것이다.
아래의 summary를 통해 p-value를 간단히 확인해 볼수 있는데 p-value값이 기본적인 잣대인 0.05보다 작으니 대립가설은 채택한다. 즉 두 변수는 독립적이지 않고 연관성이 있다는 것이다.
> smokerData <- read.csv("/home/lks21c/Downloads/ch4/smoker.csv")
> smokerTable <- table(smokerData$Smoke, smokerData$SES)
> summary(smokerTable)
Number of cases in table: 356
Number of factors: 2
Test for independence of all factors:
Chisq = 18.51, df = 4, p-value = 0.0009808
부연설명을 하자면 아래와 같이 전체 값에 대한 비율과 각 변수별 비율이 통계적으로 비슷하다면 두 변수는 연관성이 없다고 볼 수 있다. 하지만 흡연상태 former나 사회적 경제수준 High, Middle이 전체 통계와 비율이 다르므로 두 변수는 연관성이 있을 확률이 높다는 것이다.
> expected <- margin.table(smokerTable, 1)%*%t(margin.table(smokerTable, 2))/
+ margin.table(smokerTable)
> expected
High Low Middle
current 68.75281 30.30337 16.94382
former 83.57022 36.83427 20.59551
never 58.67697 25.86236 14.46067
예제에 대한 그래프 그리기
두 변수가 연관성이 있는지 시각화 해서 확인해 보기 위해 그래프를 그려보자.
통계적으로 두 변수가 연관성이 없다면 전체 분포에서의 비율대로 각 변수별 비율이 유지되어야 하는데 이 예제에서는 사회 경제적 수준과 흡연 여부가 모두 같은 비율이 아니므로 서로 연관이 있을 가능성이 있는것을 그래프로도 알 수 있다.
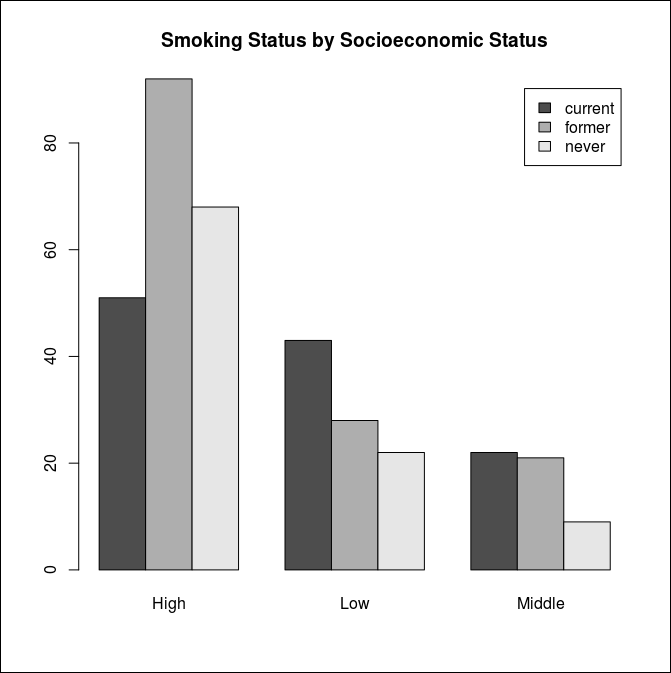
barplot
plot
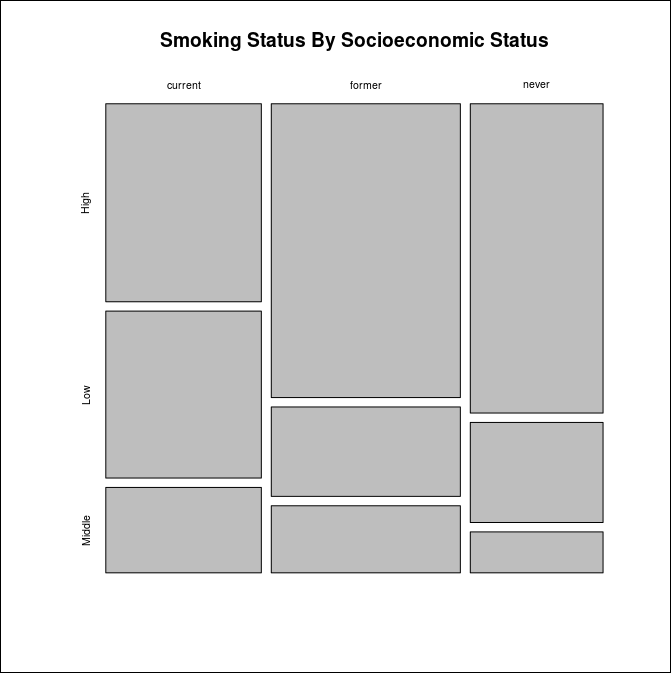
스택 형태로 비율을 보여주는 그래프를 그리면 아래와 같다.
다차원 테이블 만들기
테이블을 다루는 추가 Tip으로 아래와 같이 3개 이상의 인자를 지정하면 다차원 테이블을 만들 수 있다.
> library(vcd)
> head(Arthritis)
ID Treatment Sex Age Improved
1 57 Treated Male 27 Some
2 46 Treated Male 29 None
3 77 Treated Male 30 None
4 17 Treated Male 32 Marked
5 36 Treated Male 46 Marked
6 23 Treated Male 58 Marked
아래를 보면 트리트먼트별로 성별, 개선여부에 따라 테이블이 출력된다.
> mytable <- table(Arthritis$Treatment, Arthritis$Sex, Arthritis$Improved)
> ftable(mytable)
None Some Marked
Placebo Female 19 7 6
Male 10 0 1
Treated Female 6 5 16
Male 7 2 5
그래프 그리기
R에서 가설검증, 통계를 확인해 볼때등 그래프를 많이 활용한다. 이 그래프를 그리는 방법을 알아보자.
Simple Bar Chart
mtcars 데이터셋으로 실린더의 개수별 빈도수를 테이블로 만든다.
이 테이블을 그래프로 그려보는데 옵션은 그래프 제목, x축 레이블, y축 레이블을 지정하여 간단한 막대 그래프를 그린다.
> counts <- table(mtcars$cyl)
> counts
4 6 8
11 7 14
> barplot(counts,
+ main="Simple Bar Plot",
+ xlab="Number of Cylinders",
+ ylab="Frequency")
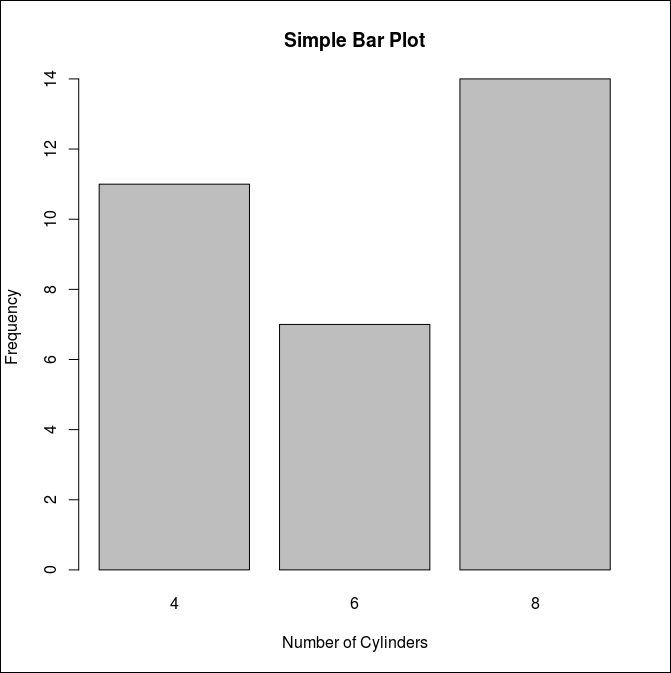
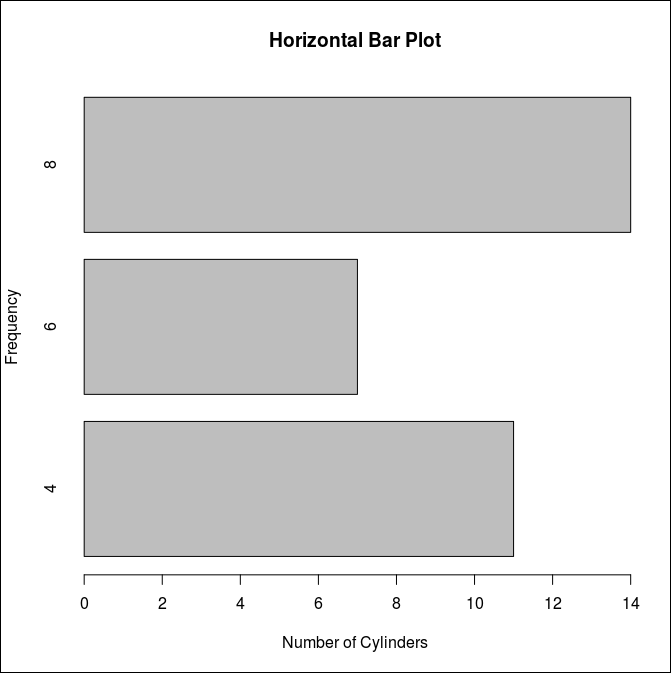
세로로 그리면 아래와 같이 된다.
> barplot(counts, horiz=TRUE,
+ main="Horizontal Bar Plot",
+ xlab="Number of Cylinders",
+ ylab="Frequency")
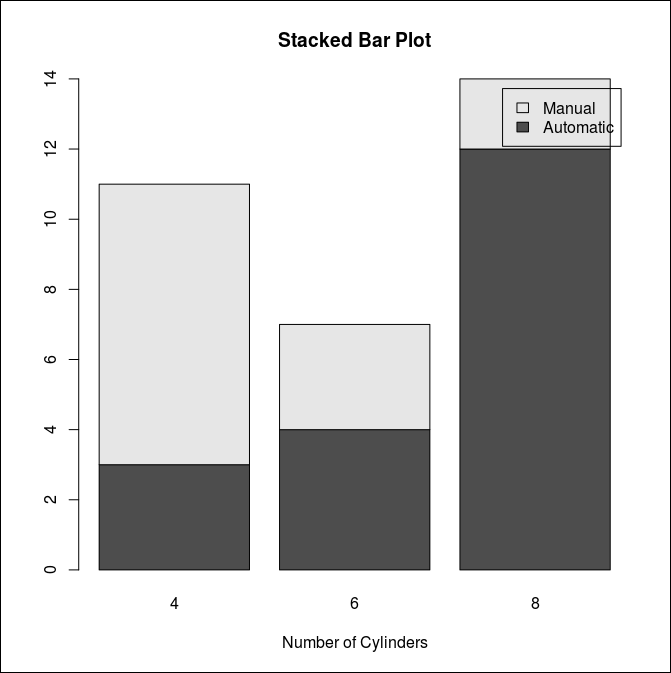
Stack Bar Chart
막대 그래프를 스택으로 확인하면 데이터의 비율을 볼 수 있다.
> counts <- table(mtcars$am, mtcars$cyl)
> rownames(counts) <- c("Automatic", "Manual")
> counts
4 6 8
Automatic 3 4 12
Manual 8 3 2
> barplot(counts,
+ main="Stacked Bar Plot",
+ xlab="Number of Cylinders",
+ legend=rownames(counts))
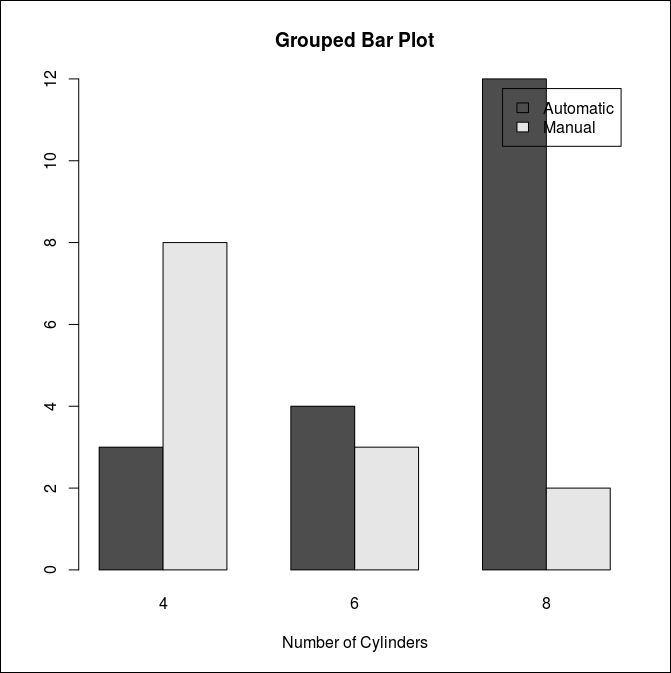
스택이 아닌 각각의 막대 그래프로 만다는 방법은 옵션으로 beside=TRUE를 지정하는 것이다.
> barplot(counts, beside=TRUE,
+ main="Grouped Bar Plot",
+ xlab="Number of Cylinders",
+ legend=rownames(counts))
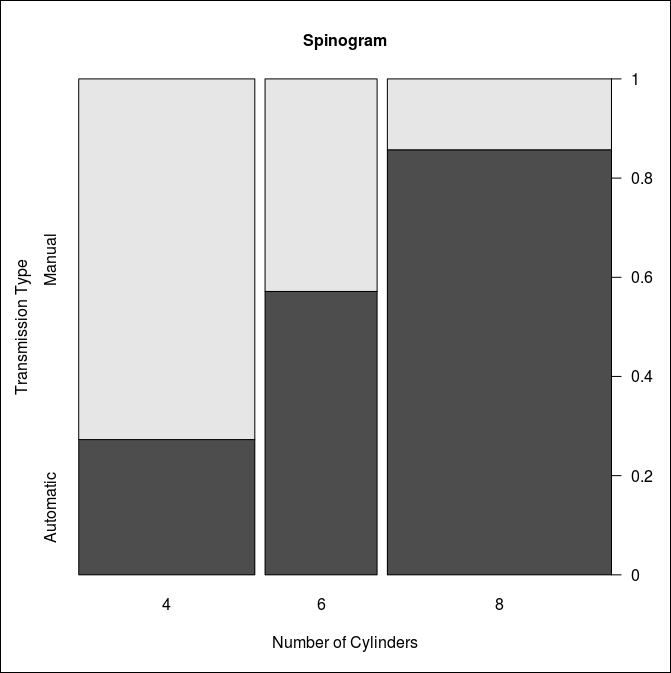
Spinogram
Spinogram은 세로의 높이를 전체 1로 만들어 차지하는 비율을 파악하는데 도움이 되는 그래프이다.
> install.packages('vcd') # vcd 패키지 설치가 필요하다.
> counts <- table(mtcars$cyl, mtcars$am)
> colnames(counts) <- c("Automatic", "Manual")
> counts
Automatic Manual
4 3 8
6 4 3
8 12 2
> library(vcd)
> spine(counts,
+ main="Spinogram",
+ xlab="Number of Cylinders",
+ ylab="Transmission Type")
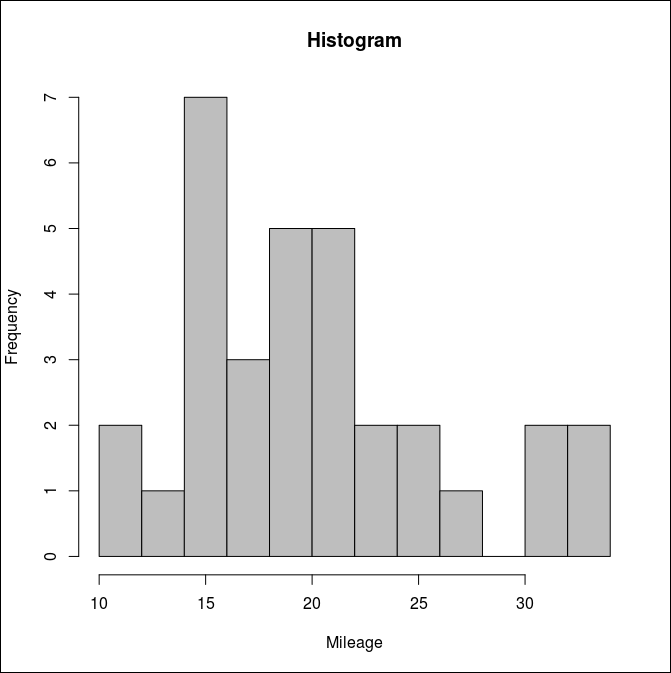
histogram
구간별 데이터의 값을 그려주는 히스토그램은 아래와 같이 그려볼 수 있다.
breaks로 몇개의 구간으로 자를 것인지 지정한다. 다만 정확히 지정한 breaks 값으로 구간이 나뉘는 것이 아니라 R에서 입력된 값과 가장 비슷하면서 데이터를 잘 나눠줄수 있는 구간을 R에서 판단하여 제공한다.
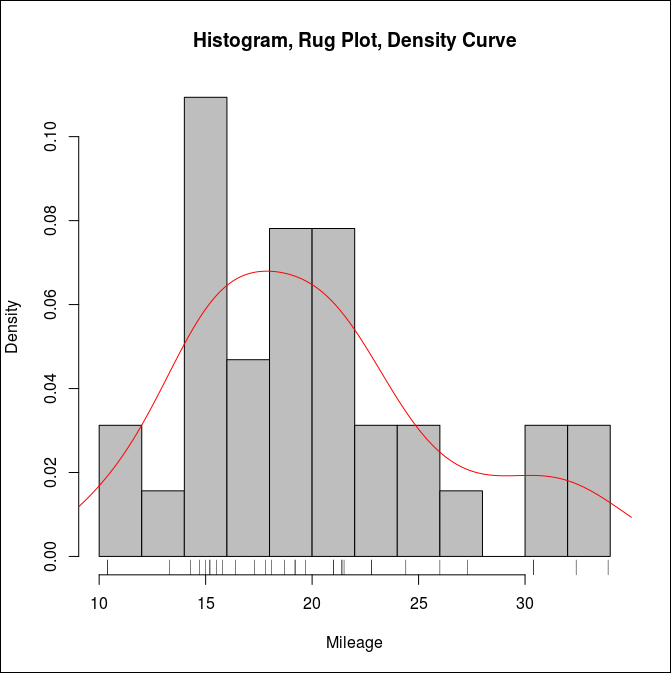
아래의 코드는 히스토그램을 그리는데 몇 가지 옵션을 더 지정한다. rug는 값의 분포를 표시해준다. 이를 통해 값의 분포를 바코드로 알 수 있다. lines 통해서 빨간색 라인으로 density curve를 표시한다.
> hist(mtcars$mpg, breaks=12,
+ freq=FALSE, col="grey",
+ main="Histogram, Rug Plot, Density Curve",
+ xlab="Mileage")
> rug(mtcars$mpg)
> lines(density(mtcars$mpg), col="red")
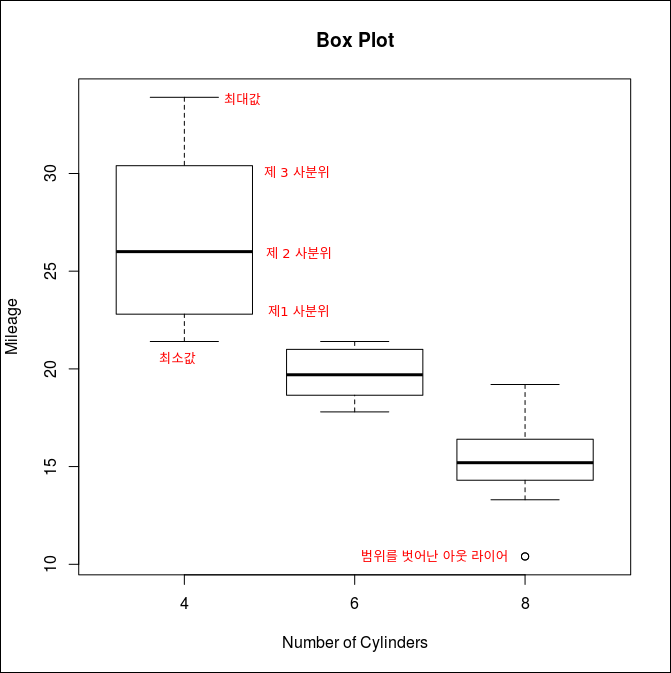
Box Plot
전체 집단에서 outlier가 존재하는지 파악하기 위해 Box Plot을 활용한다.
상자가 나타내는 것은 상자의 아래부분, 중간부분, 윗부분이 제1~3 사분위수이다. minimum값, maximum값이 있다. 펜스를 넘어가면 점으로 표시하고 이는 아웃라이어에 해당한다.
> boxplot(mpg ~ cyl, data=mtcars,
+ main="Box Plot",
+ xlab="Number of Cylinders",
+ ylab="Mileage")
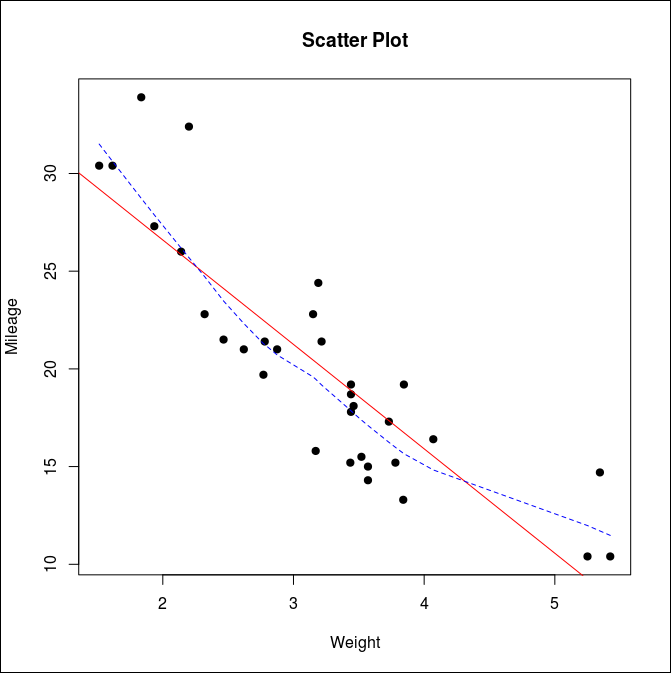
Scatter Plots
Scatter Plot은 회귀문제(regression)문제에서 많이 쓰는 그래프로 반드시 알아두어야 한다.
abline으로 lm함수로 회귀분석 된 선을 빨간 선으로 그려준다.
lines로 lowess 함수로 계산된 그래프를 파란 선으로 그려준다. lowess는 회귀분석값이 아니라 구간별 평균값으로 추적된 그래프이다.
파란색 라인으로 데이터 형태를 파악해보면 가설함수가 직선보다는 곡선이 조금 더 적절해 보인다는 것을 확인할 수 있다. 이를 가설함수 설계시 고려할 수 있다.
> attach(mtcars)
> plot(wt, mpg,
+ main="Scatter Plot",
+ xlab="Weight", ylab="Mileage", pch=19)
>
> abline(lm(mpg ~ wt), col="red", lty=1) # 라인타입 1은 실선
> lines(lowess(wt, mpg), col="blue", lty=2) # 라인타입 2는 점선
> detach(mtcars)
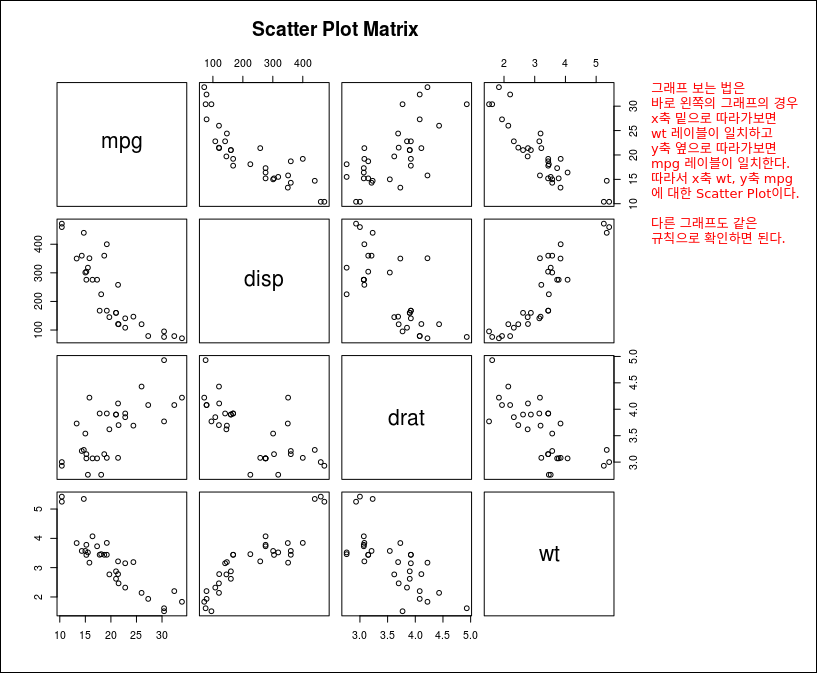
Scatter Plot Matrix
Scatter Plot Matrix를 통해 변수별 x,y축의 Scatter Plot을 한번에 확인 할 수 있다.